也许应该叫“调度那些事”。
前段时间我司的调度系统发了一篇论文《Scaling Large Production Clusters with Partitioned Synchronization》,荣获ATC 2021 best paper,很是让人艳羡。我对YARN比较熟悉,论文跟我现在的工作也算有些关联,所以特意去读了下。结合自己的一些思考,总结下。
什么是调度
在技术领域,提到“调度”这个词,大家第一反应是啥?crontab?内核、时间片、CFS?
这个词还是太宽泛了,红绿灯不也是交通调度系统么?我们加一些限定条件:大数据或分布式系统领域。
借用我司fuxi调度系统的分类,大概有以下几种:
- 资源调度:典型的就是YARN和Mesos等分层调度系统,虽然现在提的不多了。这类系统的特点是:无业务逻辑,着眼于资源管理、分配与隔离。最大的意义在于将资源调度逻辑从应用中解耦出去;
- 这种分层调度系统还可以出现一些很好玩的“嵌套”,比如k8s on YARN、YARN on fuxi、fuxi on k8s等等;
- 理论上,A on B on C也是可行的,不过禁止套娃;
- 任务调度:传统意义上的调度系统,也包括各种DAG调度系统。关注任务之间的依赖关系、failover、重跑等;
- 比如早期的jobtracker、spark中的TaskScheduler、presto中的NodeScheduler等;
- 也包括各种DAG调度,azkaban/airflow等;
- 数据调度:这个比较特殊,大意是关注数据的locality,如何在不同的机房/region之间调度数据尽量避免跨region读;
- 可能是特定场景才有用,开源领域没有看到类似的系统;
- 有那么点像缓存一致性问题;
- 单机调度:只有分层调度+混合负载时才会有这类问题,如何做到单机超卖与多种workload的平衡;
这种分类的方法未必是科学的,比如spark的DAGScheduler如何分类?DAGScheduler严格来说是不是应该叫做DAGPlanner、DAGSplitter,而不是Scheduler?
这就已经是玄学的领域了,还是不碰为妙。正如那个TwoHardThings joke: “There are only two hard things in Computer Science: cache invalidation and naming things.”。
常见的还是资源调度和任务调度。
我个人理解,所谓的调度,是一个“撮合”的过程。撮合的可以是资源请求与物理资源、可以是task与node、可以是split与task等等等等。这个“撮合”的过程,以YARN为例,被称作“assignment/allocation”,在YARN中这两个术语是混用的。
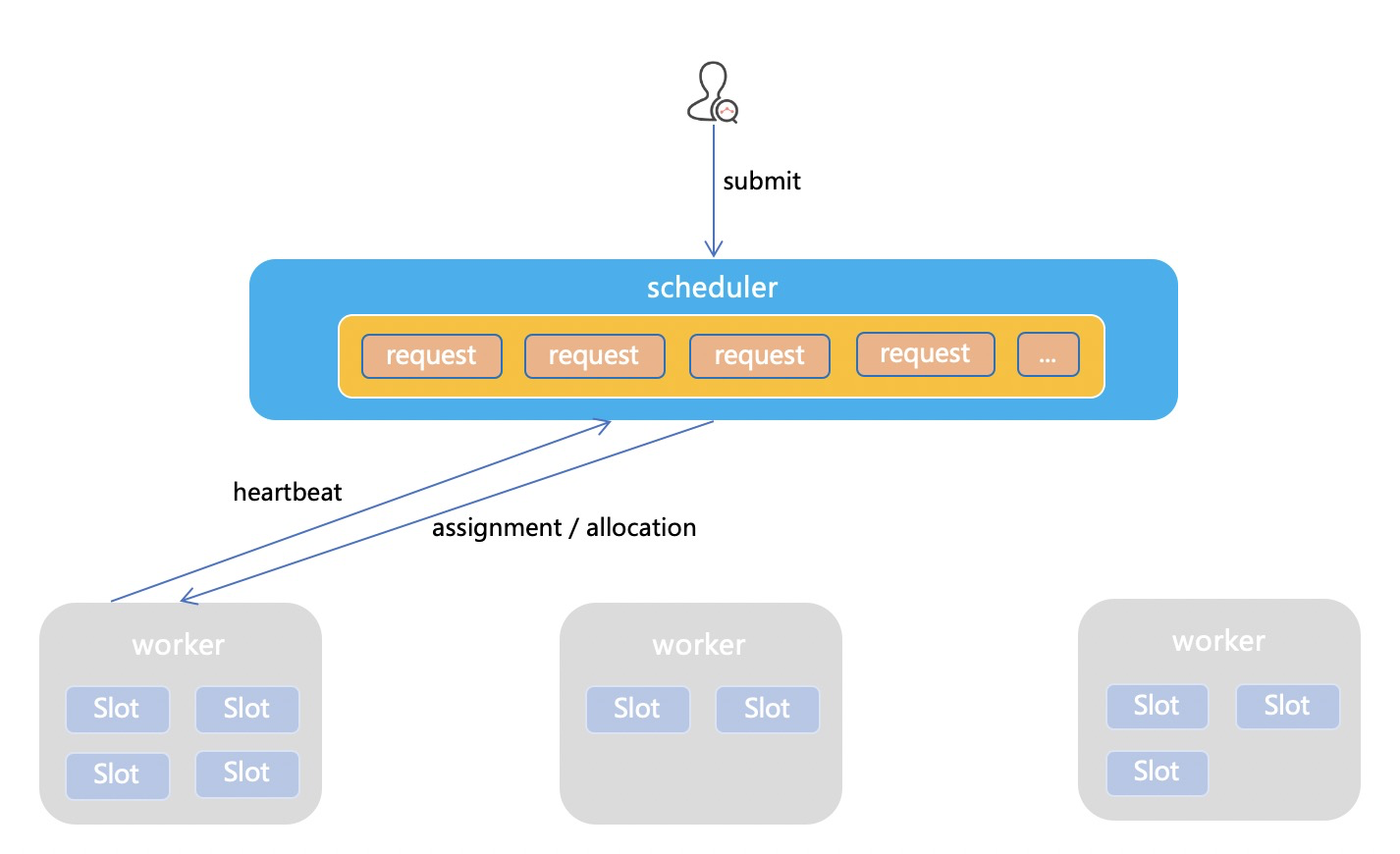
上图可以认为是一个极简的调度系统模型(参考YARN):
- client提交request给master,每个request有自己的调度约束:需要的资源大小、SLA等等,master汇总所有request的状态;
- worker节点心跳向master汇报状态,master汇总所有node的状态;
- master根据已知的全局状态(request + node),进行撮合(assignment/allocation);
另一种理解调度系统的角度,就是把它看做一个决策系统,而决策系统的核心是什么?
- 输入:就是上文提到的master所需的全局状态(request + node);
- 决策逻辑:如何撮合,有哪些约束条件?公平?先到先得?是否有抢占?
- 输出:最终做出的决策,哪些request分配到哪些node、哪些split分配给哪些task等;
不管是单一的调度系统、分层调度系统,还是现在糅合了“编排”概念、大有一统天下之势的k8s,其调度过程本质都类似。
题外话:调度 vs 编排
既然提到了k8s,就不得不聊聊所谓的“编排”,这个翻译还是比较拗口的。我对k8s并不熟,只是写下自己的理解。
调度(schedule)和编排(orchestration),到底是啥区别?早期的各种文章,会将DAG调度(oozie/airflow)之类也称作orchestration systems。但这种不在讨论范围之内。
个人理解,调度(schedule)指的是单次决策(上文中的“撮合”)的过程。assignment后,本次调度便结束了。而编排(orchestration),更多是强调“自动化”,通过各种手段,包括但不限于调度,使app保持在特定状态。“调度”是相对原子化的,而“编排”是一个人更上层的、持续的过程。
以k8s中的Deployment为例,用户需要描述app的最终状态:我要某个服务部署在3个节点上,暴露一个域名,还要LB。k8s master会通过多次的调度行为、各种配置的修改,来满足用户的需求。并持续监控app的状态,如果状态不一致会采用各种手段自动恢复。在这个“编排”的过程中,“调度”行为会发生多次,也是其中最重要的步骤,但不是唯一。
题外话:推 vs 拉
另一个有趣的话题,为何大多数调度系统,甚至说大多数主-从的分布式系统,都是基于心跳的pull模式,而不是master主动去轮询所有节点的状态并推送任务?
推模式也不能说少见,没记错的话,spark和presto都是推模式,或者说是推/拉结合(task结束触发新的推送)。但单纯的推模式有些弊端:
- master增加了额外的工作和错误处理逻辑,更容易成为全局的瓶颈;
- 比如有慢节点导致master轮询时卡住了,master是等还是不等?
- 推模式下,集群规模更受限,毕竟每次都要轮询所有节点;
- 如果每次轮询一部分节点呢?感觉也不是不行,但何必给自己增加难度?
相对的,异步的pull模式能支撑更高的吞吐和规模。
调度系统的复杂性
综上,“调度”这个行为是很单一的:根据现有的全局状态做出决策。但为啥现有的各种调度系统,无论开源/闭源,都这么复杂?YARN有超过110w行代码,HDFS也不过150w左右。即使刨除各种外围代码,只看核心的调度器部分(scheduler),也是很复杂。
很大程度上是因为调度约束(constraint)实在太复杂了(也可以叫做调度策略),或者说在撮合的过程中,要考虑的因素太多了。
常见的soft constraint(尽量满足):
- Locality:数据本地性,一般分为NODE_LOCAL/RACK_LOCAL/OFF_SWITCH等几个级别;
- 这也是最常见的soft constraint。调度器会尽量满足每个requset的locality,但不保证;
- 话说,现在Locality似乎没有以前重要了,很大程度上是因为带宽资源没那么紧张了;以前有个说法:移动计算比移动数据更经济。因为都是千兆网卡,最多几个千兆做个bond,现在都是万兆起步了;
- Fairness/Priority:多租户环境下,如何分配资源;调度器可以根据特定的公平算法,尽量保证公平;
常见的hard constraint(必须满足):
- Quota/ResourceLimits:如果超过了quota,一个request是不可能被调度的;
- quota是有很多层次的,除了常见的队列级别(queue level quota),还可能有user、app、app type等;
- Node Label/Partition:根据节点的属性进行调度;包括inclusive/exclusive partition等;
- YARN里面做的更复杂一点,细分为Node Label和Node Attribute,而且可以用DSL来写约束条件,比如:这个task要放在python版本大于xx并且tensorflow版本小于xx的节点;
- Affinity/Anti-Affinity:亲和性与反亲和性,某些task必须调度到同一个节点、或者不能调度到同一个节点;
- 例:hbase的task和zk的task调度到一起;高优先级的、在线服务的task,不能和低优先级、batch的task调度到一起;
- Gang Scheduling:all or nothing的调度模式;
- 其他:DAG也算是一种约束(上游任务不结束,下游不能调度);时间(不到特定时间,任务不能调度);
为了满足各种调度约束,调度器还会引入一些更复杂的处理机制:抢占(Preemption)、预留(Reservation)等等。
凡此种种,导致调度器本身的逻辑不断膨胀,代码也同步膨胀。当然不同的调度系统可以选择支持或不支持某些约束。
如果不考虑调度约束,那就简单了,只要node还活着,XJB乱调就行了,不如称之为“Monkey Scheduler”,正如排序算法中的猴子排序。
除了核心的调度器逻辑之外,作为一个完整的调度系统,肯定还要考虑其他一些事情。
- 从产品和用户的角度:
- 如何支持多租户?YARN是用队列实现的,但并不是唯一解;
- 单一负载 or 混合负载?
- 资源如何抽象?slot?mem和vcore?flops?
- 如何计量/计费?
- 从工程实现的角度:
- 调度器决策需要维护大量的全局状态(request+node),这些状态如何同步与持久化?
- 状态又会带来failover与HA的一堆问题;
- 资源如何隔离?如何超卖?
- 资源碎片如何处理?如何提高资源利用率?
调度系统的衡量指标
借用论文中的总结,调度系统需要关心的指标包括:
- scheduling efficiency:这是一个比较学术的词。从工程的角度来说,就是吞吐:你的系统每秒能支持多少调度请求?换句话说,你的调度器每秒能做出多少assignment决策?
- scheduling quality:不同系统对quality定义可能不同。典型的就是各种soft constraint(比如locality)是否能被满足;
- quality和efficiency往往是互斥的,如果要精准match每个request,吞吐就上不去;
- fairness and priority:我感觉这个也可以算作quality;
- resource utilization:好的调度系统是能尽量将集群资源用满的,可能是通过超卖、碎片整理等手段;
此外,从工程的角度来说,还要补充个很重要的指标,就是集群规模。实践中的各种系统大多是基于心跳向master汇报状态的,集群规模一大,光是心跳就能将master打挂。
不同的调度系统,对各个指标的偏向性是不同的。一般来说,短时task、batch的调度系统,更关注吞吐(即使某些soft constraint不能满足,也影响不大,反正任务很快结束);而长时任务、在线服务的调度系统,更关心调度质量。
工程实践
上面讨论的都偏学术、偏抽象,接下来讨论点实际的。以YARN为例,看看它在各方面存在的问题和可能的解法。
- efficiency:YARN的调度器单机吞吐其实一直都不高,通过SLS等模拟可能就1k左右,这可以说是YARN的设计缺陷导致;
- quality:支持的调度约束很丰富。但主要用于batch场景,关注点也不在quality;
- fairness:支持公平算法+抢占;支持各个粒度的quota限制;支持队列级别的优先级;
- resource utilization:一般而言也不高,因为YARN的中心化调度机制导致NM必然有一段时间是空跑的;
- 规模:实践中有2k~3k的,再大规模估计也很难,主要还是心跳问题。
演进1:提升单机吞吐;
YARN调度器的特点:
- NM周期性向RM汇报心跳,触发NODE_UPDATE事件,调度器会尝试在这个节点上分配container;
- 默认配置下,每次心跳只分配一个;
以hadoop 3.3.1为例,代码截图: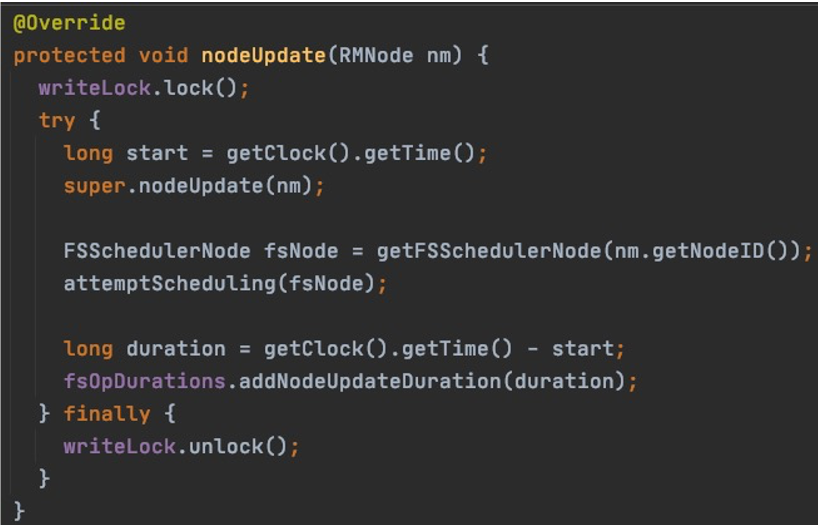
时序图: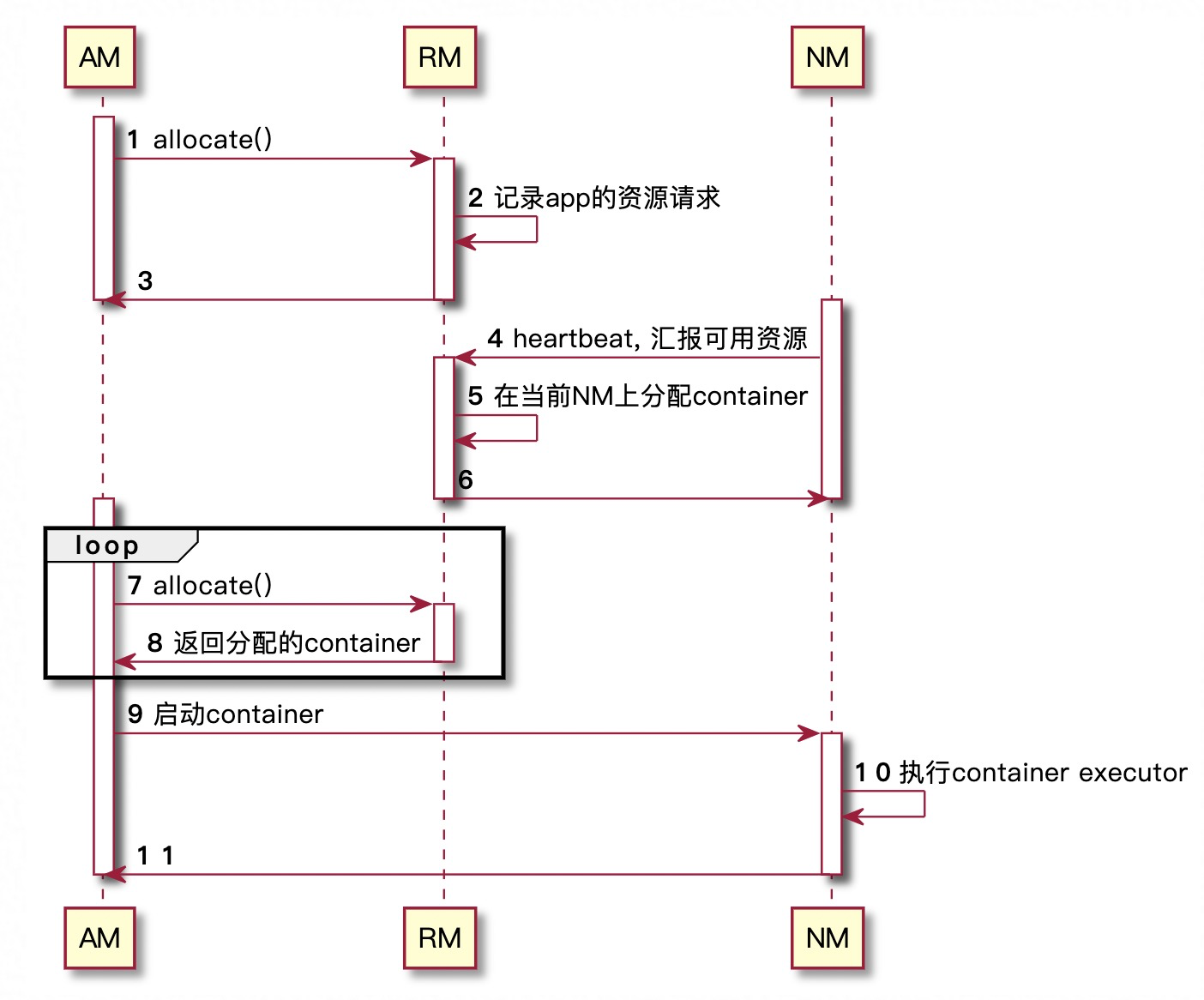
这种设计的好处:NM发心跳过来了,至少说明它肯定是活着的,调度器能“看到”这个节点最新的状态,做出的assignment是“明确”的。
但弊端也很明显:吞吐受限于NM的心跳,很难提升;如果缩短NM心跳的间隔,又可能会带来其他的问题;
暂且称这种方式为同步调度。一个很自然的想法,能否在NM没有心跳发过来的时候,调度器自己异步的进行assignment?本质上,心跳是用于更新node state的,和assignment是两个过程,可以解耦。
FairScheduler和CapacityScheduler都有这方面的尝试。FairScheduler中叫做ContinuousScheduling,不过已经废弃;以CapacityScheduler中的GlobalScheduling(YARN-5139)为例:
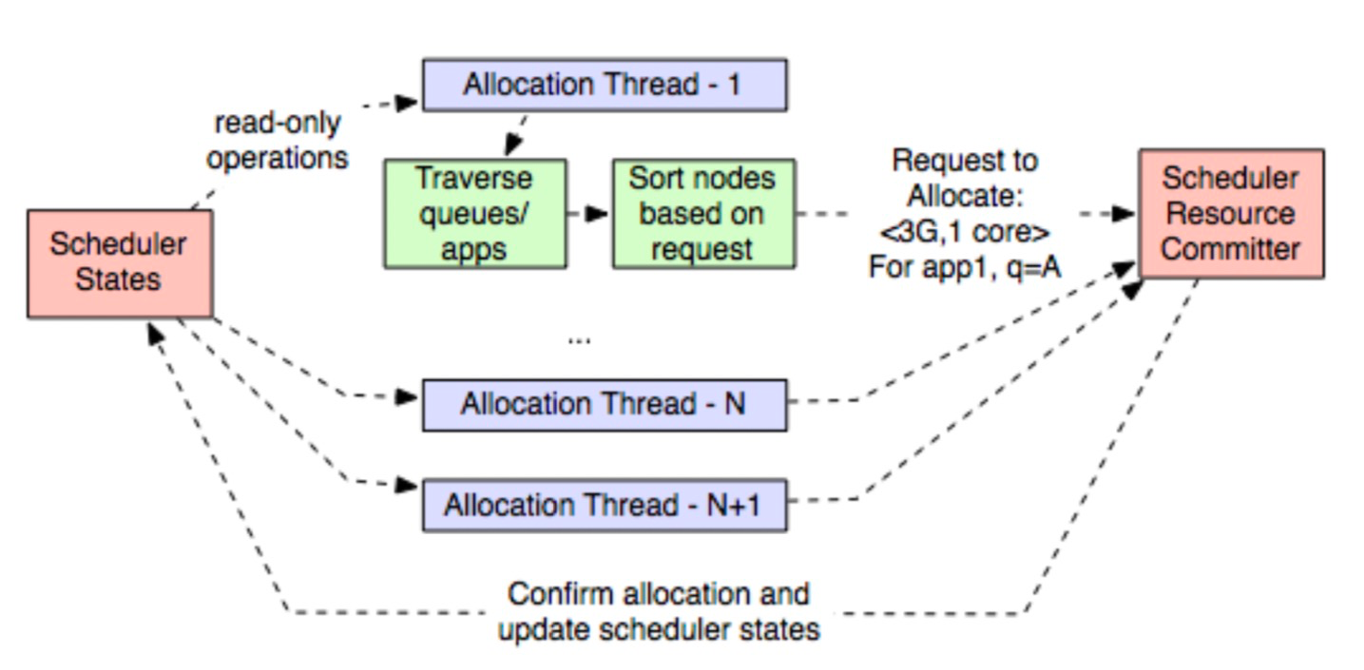
本质上,类似两阶段提交:
- RM中有多个线程,周期性的、异步的进行assignment;
- 由于不等待NM的心跳,所以这些线程看到的状态可能是“不新鲜”的,做出的决策可能也是错误的;
- 一个例子:线程1看到节点A上有空闲资源,分配掉了;但线程2不知道,仍会尝试在节点A上分配任务;
- 简单的解法就是加锁,但吞吐又会受影响;
- 这是和同步调度最大的区别。同步时,assignment必然是“明确”的;
- 所以每个线程的决策只是一个提议(proposal),是否能真正提交变为一个assignment,需要有一个全局的committer进行仲裁;
- 这个committer是一个全局单例;
- 各个线程读取全局状态时需要加readLock,只有NM心跳或committer更新全局状态时,才需要writeLock;
和所有两阶段系统类似,这种设计也面临几个问题:
- 仲裁逻辑是什么?目前的实现就是简单的比较proposal提交时间;
- 如何缓解冲突?目前有一些简单的方法,比如错开各个线程的调度时间、错开尝试的节点等;
结合YARN后续的一些优化(包括assignMultiple、锁粒度优化、序列化相关优化等),社区给出的测试结果是单机吞吐可以达到5k左右。
演进2:多调度器;
单机吞吐的提升终究有极限,而且也不能解决规模的问题。另一种思路,就是既然一个调度器搞不定,用多个调度器行不行?大体的思路就是放松全局状态的一致性(弱一致并且不在关键的调度路径上),换取吞吐和规模的提升。
一个关键问题:状态(request+node)如何拆分?
- request:目前已有的各种实现,request都只会发送到特定的某个scheduler;换句话说,不同的scheduler,只能看到自己的request;
- node:这里就有两个流派了;
- shared state:每个scheduler看到的node state是相同的,都是全局视角;
- static partitioning:每个scheduler只能看到一部分node state;但这会带来一个问题,scheduler的调度规模受限,需要用其他手段解决;
shared state
shared state的概念最早是Google Omega提出的:
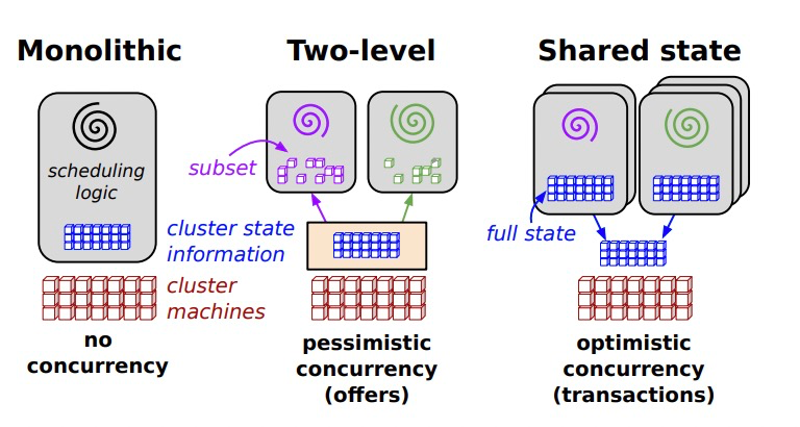
简言之:
- 多个调度器周期性的从某个角色同步node state到本地;
- 每个调度器根据自己的local state进行决策;
跟YARN中GlobalScheduling的问题类似:
- 冲突如何解决?全局加锁肯定是不行的,google给出的解法是乐观机制,假设冲突很少;如果出现冲突,理论上应该每个node自己仲裁,scheduler重试;
- 如何缓解冲突?论文中没提,各显神通了;
一个很标准的shared state实现就是Microsoft Apollo(2014):
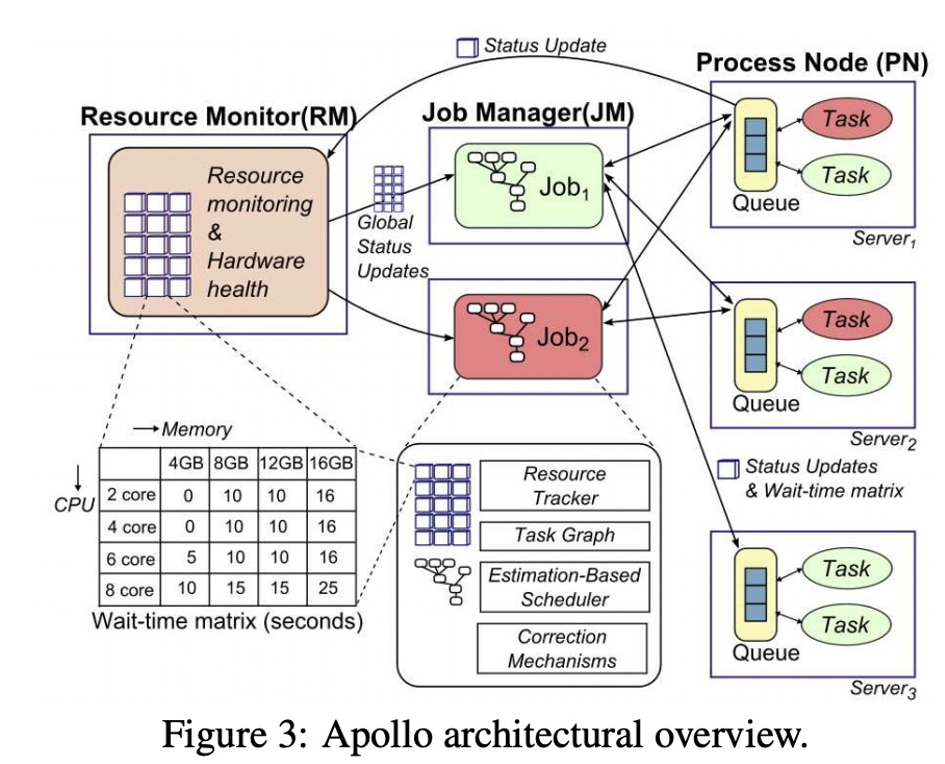
标准的不能再标准了。。。
ParSync
终于到了那篇ATC best paper的核心内容。它本质解决的是shared state模型中的第二个问题:如何缓解冲突。
- omega假设每个调度器同步node state的时间很短,代价很小;但fuxi实际的观察中,同步代价很高;而且集群规模上去后,这个状态会很大;
- “不新鲜”的状态导致冲突几率增加(论文中有详细论证),问题进一步恶化;
- 这也是很符合直觉的;正如YARN的同步调度为何选择有节点心跳时才触发调度逻辑;
- 我猜测这个结论是来自于实际的经验总结,然后才进一步用数学化的方法建模论证;
论文提出了一种被称作ParSync的解法:
- 将node state分区,每个调度器每次同步状态时,只同步一个分区的状态,很快就能完成;
- 这样,每个调度器看到的状态,有部分是新鲜的,有部分是不新鲜的;
- 调度时,调度器优先在状态新鲜的节点上调度,以减少冲突几率;
- 但新鲜的节点毕竟是少数,只在这些节点上调度会导致quality下降(比如locality无法满足);调度器提供几种模式给用户选择,是latency-first还是quality-first;
其实吧,论文的核心内容就这些。其他的数学公式、实验数据等只是为了支撑这个论点。
static partitioning
这个流派的代表是YARN Federation。
微软2019年发表了基于YARN开发的Hydra调度系统,将之前的Apollo替换掉了(不知为啥),并将大部分feature回馈给社区。
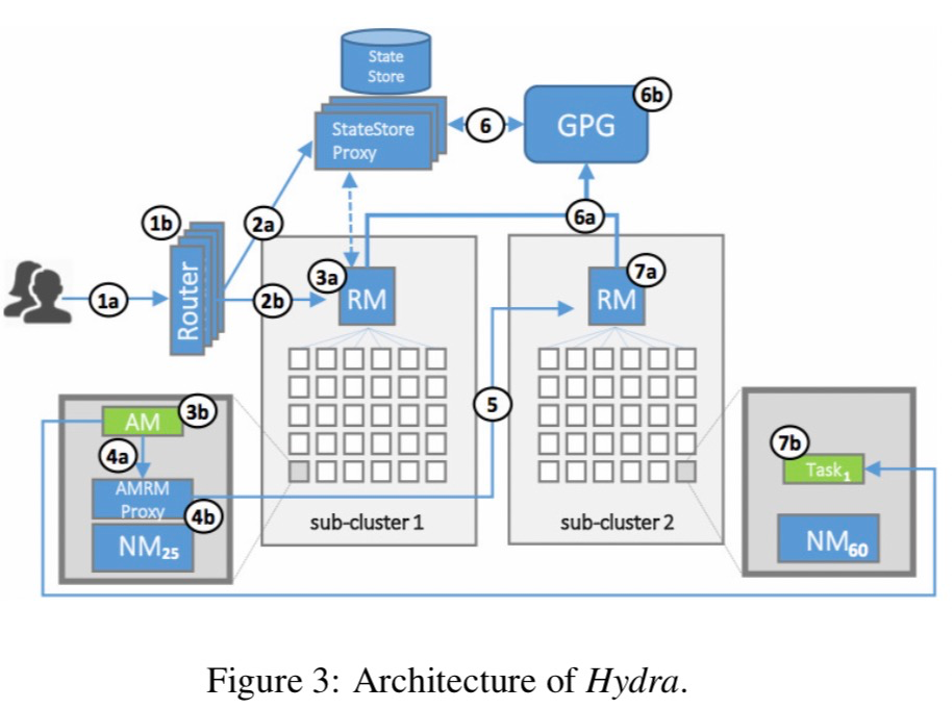
- 多个sub-cluster组装成一个大的cluster,对外API不变;
- 引入一个极其重要的角色AMRMProxy,用于不同sub-cluster之间的路由;
- 单个scheduler是不知道其他sub-cluster的存在的,全靠AMRMProxy透明的代理掉;
- AMRMProxy有点类似微服务中的sidecar模式;
- 引入另一个角色GPG负责汇总全局状态,但不在调度的关键路径上;
- 引入全局的state store用于存储各种路由策略;
据论文中的披露,微软维护着目前已知最大的YARN集群,单集群5w+节点,由20~30个sub-cluster组成,每个sub-cluster 2k~3k节点。
个人感觉,相对于shared state,这种工程实现上要更复杂一些,暂且没有看到特别突出的优点。
也许最大的好处是可以尽量复用YARN已有的各种能力。
演进3:Distributed Scheduling
同样来自微软的贡献。YARN中可以开启OpportunisticContainers特性使用。某些情况下,调度行为可以不经过master,直接将任务提交给worker。
对于短时的、batch任务效果非常明显,因为省去了中间的调度开销,提升资源利用率和吞吐。

其他思路
最近还看到个画风不太一样的系统:facebook的流处理调度系统Turbine:
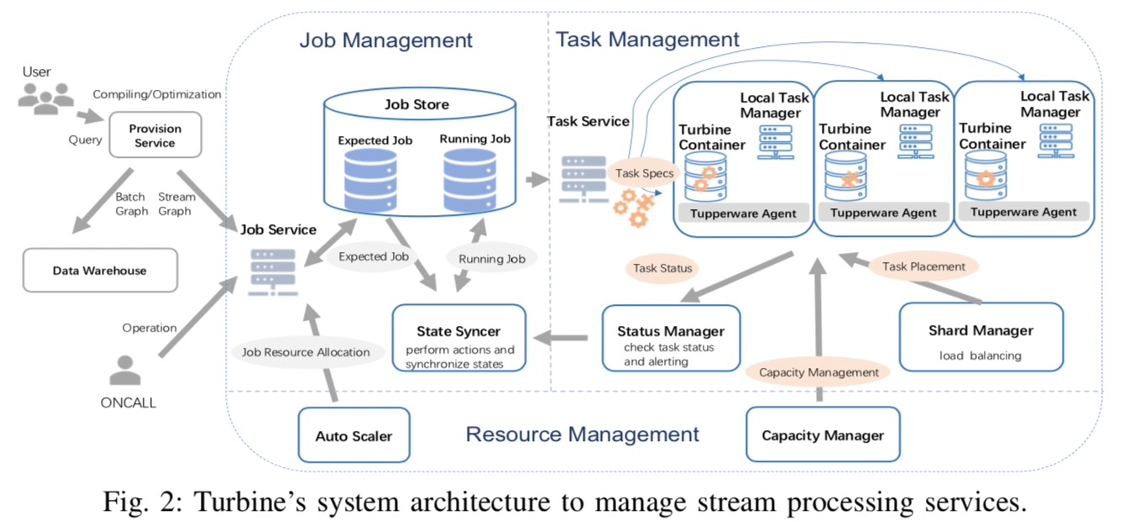
论文看下来,这个系统是比较特异化的,估计也只适用于他们的场景,但其中有一个思路很有意思:事中调整替代事前决策(fast scheduling),与其在事前考虑各种约束、资源大小等等,不如事中通过LB/scale-up等方式动态调整。
这个思路也只适用于长时任务,对于batch等短时任务,根本没有事中调整的机会。
一些总结
本来只是想总结下fuxi那篇论文的读后感,写着写着内容就慢慢越来越多。
遗憾的是我对k8s还是不够了解,不能更多的横向对比下。有一个孵化器项目yunikorn,稍微看了下,感觉就是将YARN支持的各种调度约束移植到k8s。
现代的调度系统之所以会成为一个全局的基础设施,很大程度上是因为在云原生的大背景下,混合负载的重要性前所未有的提高了。以前,每个系统自己搞一堆机器,自己玩就行了。现在,我们要弹性、要serverless、要在离线一体化,所以一个大一统管理所有资源的调度框架,提升利用率压低成本,非常迫切。k8s之所以能快速成熟并且流行,很大因素是切中了这个时代趋势。
YARN其实也看到了这个趋势,在LRS(long running service)上的努力也一直未停止过,融合了早期的Apache Slider等项目,推出了YARN Services等feature。但不得不说,YARN从基因上就并不适合在线服务,在业界也并没有成功的大规模验证过,更多还是用于离线batch。而k8s是从在线向离线演进,天然与容器技术结合,难度就更小一些,也有了spark on k8s等成功的范例。虽然支持的各种约束/策略没有YARN丰富,但这些可以慢慢完善。
之前看过一种论调,云原生的未来必定是裸金属+容器,深以为然。以前所谓的“上云”只不过是将服务搬到云上的虚拟机。
写到最后,聊聊hadoop。最近总是有不少文章宣传着“hadoop已死”,前几年CDH/HDP合并,前段时间又有很多hadoop相关的apache项目退休,有不少我还用过。
我11年开始接触hadoop,从0.20.x/1.x/2.x/3.x一路走来,10年了,也算是见证整个生态兴起、蓬勃与沉寂。个人感觉,死倒不至于,但确实式微了:
- hadoop生态本身就过于复杂了,组件太多不是好事,我也觉得很难用。。。随着clickhouse/ES等一站式解决方案兴起,用户都会用脚投票的。这方面的一个正面例子是snowflake:极致的产品易用性,性能反而是其次。
- 云的冲击:云化的大趋势是不可逆的,而hadoop本身并不是为云而设计,自然会被后来者超越;
hadoop本身,以后应该会隐藏的更深,甚至对用户不可见。但hadoop留下的各种标准,会继续被后来者兼容,比如HDFS/HiveMeta等等。
但话说回来,10年本就是不短的时间了,太多的事情可以改变,hadoop也不过是沧海一粟罢了。我们已经见识了房价飙升、巨头兴起、贫富差距、P2P暴雷等等大事件,这点事算个啥。。。
即使是科技界,也从不缺热点,前些年的深度学习、AI、区块链,更远些的ios、移动互联、IOT、微服务,现在的k8s/云原生/serverless,还有更玄幻的“元宇宙”、脑机接口。
笑看谁主沉浮吧。
