非常赞的一本书,链接:OReilly Shop,6月才出的。话说OReilly真是业界良心。
我订阅了Hadoop Weekly,某天它推荐了一篇cloudera blog,具体链接忘了,部分内容就是节选自本书,讲了实时处理的一些架构,当时就感觉很赞。于是找来原书看看,顿觉相见恨晚。
断断续续看了2个月,550多页啊,全英文。简单总结下。
书如其名,讲的是如何利用hadoop生态圈中的各个组件,构建自己的应用,或者叫data pipeline。只讲架构,而不会太深入细节。
先扯些别的
我在以前的文章中写到:大数据技术很多,但成熟的少,门槛很高,落地太难。
现在依然这样觉得。
我认为hadoop圈已经发展的足够复杂了,各种开源项目可以覆盖到大部分需求。这么多apache顶级项目任君选择,还有各种孵化器项目。在hadoop-user的邮件列表中,还经常有人推销一些不太知名的第三方项目。
所谓的定制开发需求,很多是没有必要的,或者是从业务逻辑上可以绕过的,可以称作伪需求。说的不客气点就是自己YY出来的。有多少公司能达到阿里/腾讯那个数据量?会碰到他们的问题?不应该为一些很小的需求投入大量精力去改造。纯研究性质的另说。
hadoop现在真正欠缺的是易用性。技术已经很成熟,但对用户不友好。这里的用户不只是终端用户,也包括运维、开发。
很多项目为了追求技术的极致,为1%的性能提升而花费大量精力。一些出自学院派的项目尤其如此(想到scala,以用户大都是博士硕士为荣)。
其实如果能优化下用户体验,就推广上而言,远比1%的性能提升要好。
可能也是我最近做业务做多了。很多时候,技术都不是最重要的,够用就好。当然也不能太low。。。
Done is better than perfect嘛。
似乎我以前也吐过这种槽。。。
这算是学术界vs工业界?
其实很多发行版都在做出努力优化用户体验,但是还不够。
如果我是一个新用户,面对这么多项目、这么复杂的系统,肯定无从下手。我只知道我要建一个数据仓库/我要分析日志/我要实时监控,有人跟我说hadoop能解决,但具体怎么做?
咳,这本书就是告诉你怎么做的。扯了半天终于扯回正题了。。。
关于本书
凭一本书当然不可能解决hadoop的易用性问题。
本书只是描述了各个组件的适用场景,结合一些实例,总结一些经验供读者参考。这些经验都是经过实践检验的,比较可靠,比自己慢慢摸索好多了。
对于我这样对hadoop比较了解,对其他项目也有一些了解,但缺少实践经验的人而言,本书非常适合,简直是雪中送炭。如果要我自己去构建一个系统,应该也能搞出来,但会比较痛苦,会踩很多坑,后续的维护性和扩展性也不好说。
但对新人而言,看这种书可能会比较累,一些设计上的抉择也不容易搞明白。建议先了解些基础知识。
下面系统的总结下。
如果要构建一个基于hadoop的系统(无论离线还是实时),要从哪些角度去思考?或者说,要如何设计数据流?
一个前提:不存在one fits all的解决方案。
数据建模
这是第一步,也是最重要的一步,但却很容易被忽视。我们以前直接纯文本,最多lzo压缩下,简单直接。
按本书的说法,这里有很多问题要考虑:
- 数据格式。纯文本?二进制?是否有schema?
- 文件格式。行式?列式?avro?parquet?sequence file?
- 压缩。是否压缩?lzo/snappy?splittable?
- 存储。数据存在哪里?hdfs/hbase/kafka?有些时候会存多份。如何分区?
- 元数据管理。这是最抽象的。很多时候都意识不到元数据的存在。hive?hcatalog?
数据格式,这是由各个应用决定的。
文件格式,我会尽量选择parquet。因为hadoop最大的应用场景是文本处理,或者类似OLAP,列式存储会有很大优势。以前还有种文件格式rcfile,现在好像很少用了。也要看具体的应用场景,如果是偏向于整行处理的,也可以选择avro。甚至可以基于sequence file设计自己的文件格式。总之还是看自己的应用模式。
压缩,尽量选择snappy。parquet+snappy是非常完美的。parquet/avro是一种类似于“容器”的格式,是splittable的,而不必关心容器内的数据是如何压缩的,于是snappy不能split的缺点也可以克服了。以前我们用的最多的是lzo,只是为了split。但每个lzo文件还要单独加index太蛋疼了。另外由于许可证问题,lzo的部署也比较麻烦,snappy就简单很多。如果要归档历史数据,也可以考虑gzip/bzip2。
存储的选择很简单,批处理就hdfs,实时就hbase/kafka。但直接用kafka存数据的比较少见,一般只是拿它过渡。
元数据管理没什么统一的方案,要看自己的应用。但有个偷懒的方式,尽量把数据全部导入hive,让hive去管理元数据。
数据导入
这是数据开始“流动”的起点。如何将数据导入hadoop?
- 数据类型?日志?数据库?纯二进制文件?
- 数据处理模式?流式?批处理?随机读取?
- push or pull?
- 传输过程中,是否需要一些处理/过滤?
- sink类型?是否要增量更新?append/overwrite?
最简单的方式是直接以文件形式传到hdfs上,hdfs fs -put。这种方法虽然土,但有效,而且可以导入任意格式的数据。缺点是不太可靠。
如果是从rdbms导入,只能用sqoop了,没有太多选择。
其他情况下,一般flume都是最优选择。在hadoop圈的日志传输工具里,flume算是最成熟的了。而且flume提供interceptor机制,可以做一些简单的实时处理。但处理逻辑如果太复杂,会影响flume节点的吞吐率。
flume另一个问题是可能有数据重复。这是所有日志传输工具都会有的问题。flume的理念是“at least once”,优先保证数据不丢失,但故障时允许重复。
想要做到真正的“exactly once”是非常难的,而且势必会影响效率。
flume支持pull和push模式。但push模式需要改应用代码,直接在代码中像log4j一样调用,感觉不太好。。。常用的还是pull模式吧。flume实现了基于文件的pull模式,但只有当文件写完后才能pull,也就是说数据不是实时的,不支持类似tail的模式。
如果目的地不是hdfs,而是hbase或是其他的系统,首先看下flume有没有提供对应的sink,没有的话就要自己写了。
另外,kafka虽然不是用于数据导入的,但它像万金油一样,到处都可以用,能玩出很多花样。。。比如应用直接写数据到kafka,flume从kafka读取数据并归档到hdfs;或者flume直接写到kafka,让其他应用去消费。这样数据的可靠性可以交给底层的kafka保证。而且kafka中的数据可以有多个消费者,同一份数据可以用于多个地方。
其实在现实中,很多公司会自己开发日志传输工具。
题外话,很多公司最常见的“定制开发”:日志传输和调度系统。这两个确实是和需求绑定比较紧的,不太容易通用。这种定制开发看着容易,随便写写就能cover 95%的需求,但剩下的5%才是真正的问题所在,决定了这个工具是“优秀”还是“能用”。
数据处理
首先要明白自己的处理模式。
借用书中的一张图: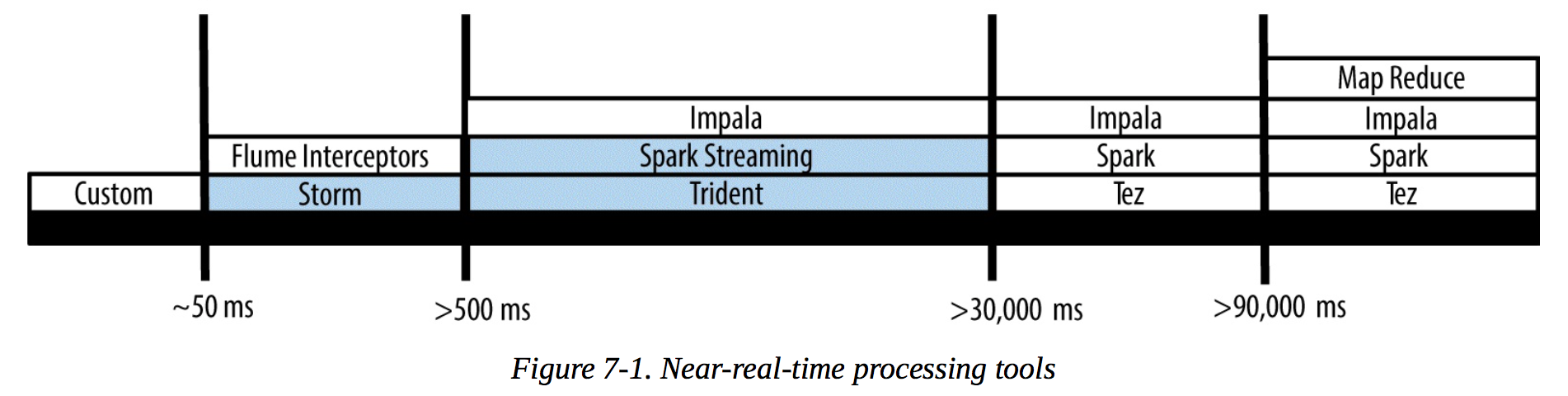
如果简单点按响应时间分类,应该有3种:
- 批处理/batch process,至少是分钟级别的。典型的比如MR、spark。特点是一次性处理大量数据,没有daemon。
- 交互式查询/ad-hoc query。一般是秒级别,比如impala。特点是有daemon进程常驻内存。spark也能部分覆盖到这个场景。
- 实时处理/流处理/stream process。处理模式跟前两者完全不同,基于每条日志去处理。比如storm。
这是一种很模糊的分类,没有明确的界限,大概知道就可以。
ad-hoc query很多时候是由batch process优化得来的。如果能让MR有个线程池之类的东西,再加上一些优化,相信MR也可以作为ad-hoc query。
spark streaming虽然也号称是流处理,但真实的处理模型其实是micro batch。
所以不要纠结分类,知道每种工具的适用场景就可以了。
上图中最左边的custom,意思是如果要更实时的处理,只能自己实现了。想到高频交易那帮人。。。
个人感觉,spark有一统天下的趋势,各种场合都可以用。
批处理
hadoop最主要的用处。
批处理和交互式查询除了响应时间,很多时候计算模式是类似的。放在一起说了。
这里要区分计算引擎和工具:
- 引擎:MR(经典/可靠/效率低)、spark(新贵/准备登基)、tez(已死/有事烧纸)、impala(没用过/不确定)。
- 工具:hive、spark sql、pig、crunch、cascading。
引擎和工具的区别,就是执行效率和开发效率的取舍。直接写MR可以控制大量细节,人为的做很多优化,但是要写大量代码,开发和维护的代价都很大;如果用hive,直接写sql就可以了,但hive sql编译出来的job往往不是最优的。spark/spark sql也是同理。
重点说说MR和spark,至于其他的,其实不用关心。。。早晚会败在spark手下。。。
MR是非常经典的计算模型,最重要的设计是share nothing,所以可以简单的并行执行。在MR的过程中只有一次数据交换的机会,就是shuffle,所以多次迭代必须要多次MR。更为人诟病的是效率低,startup overhead非常大。
spark的初衷则是DAG处理,跟MR完全不同。spark感觉就是非常学院派的。。。spark在技术上的nb是毫无疑问的,发展非常快,但快也有很多问题,书中的原话是“Spark still has many rough edges”,以后应该会慢慢好转。
hive是sql on MR的标准实现,很多项目都兼容hive的语法/元数据,hive也慢慢变成sql on hadoop的标准了。
spark sql也兼容hive。但鉴于他们放弃shark的“前科”,未来如何还要再观察。
另一个有趣的对比就是hive on spark和spark sql,二者功能上其实有些重叠的。但spark的东家databricks似乎对hive on spark非常不感冒,坐看他们撕逼了。。。
对于impala,它是用C++写的,在hadoop圈中算是比较另类的存在。但对于交互式查询,好像只有impala比较成熟,其他一些类似的项目drill、stinger,基本都没人用的。所以在spark成熟前,在交互式领域,impala还是首选。
流处理
flume interceptor之类的暂不考虑,其实可选的工具就两种:storm和spark streaming。很久以前还有些其他的实时框架,S4什么的,但已经没人用了。
流处理和批处理的区别是什么?其实处理上是没什么区别的。。。感觉是用吞吐量的下降换取实时性。另外由于每次只处理一条数据,一些上下文相关的处理会比较麻烦。
我最早接触的实时框架就是storm,那时好像是0.7.x的版本。最让人惊艳是无状态的设计,nimbus可以随时重启,这是第一次见到。storm是最纯粹的record-based process,每次只处理一条。除了处理数据外,storm另一个重要作用是DRPC。ack机制也是storm的特色。
trident相当于扩展了storm,类似于hive与MR的关系,提供了更方便使用的接口,但似乎处理模型也有一些变化,变成了“伪batch”。
而spark streaming是“真batch”,它的实时只是降低了每次batch处理的数据量,同时提高处理频率。对实时性要求没那么高的情况下,性能会比storm好很多。不过,它真正的大杀器是批处理和流处理可以共用同样的代码。。。因为spark的RDD抽象层次很高,无论批处理还是流处理,都是对RDD的各种变换,只要改下作为输入源的RDD就可以。
对于流处理,一个很重要的问题是可靠性保证,一共有3个级别:
- at most once。每条记录最多处理一次。简单的说,数据发出去就不管了,即使处理失败也不会重发。这是安全性最低的级别,可能会有数据丢失。
- at least once。每条记录至少处理一次。这也是大多数框架默认的级别。比如storm的ack机制,一条记录处理后必须ack一次,否则storm会认为处理失败,重发一次记录。但这样也可能造成重复处理。比如一条记录处理完毕,已经更改了外部的状态(比如mysql里的计数器+1),但ack()之前失败了,就会重复处理。
- exactly once。最严格的可靠性保证,每条记录只处理一次。使用上有很多限制,对输入源、输出目标、编码方式都有要求。而且对效率影响非常大。
一般最常用的还是at least once。
稍微google了下exactly-once语义。要实现exactly-once,首先输入源必须是transactional的,大概的意思就是输入必须是严格有序的,可以根据id回放,并且回放的数据必须和以前的完全相同。无论storm还是spark streaming,目前只有kafka输入源能满足这个要求。其次,在写程序时,也必须一些额外的工作,处理一条记录后,不能直接修改状态(比如直接改数据库),而要把状态分成多个阶段,beforeCommit、commit等,实现相应的方法。这样把状态更新交给上层去处理(storm或spark),storm或spark会将状态变换暂时缓存到内存里,当前记录或batch处理完后,才会真正更新。如果失败,会回放数据并重新处理。这中间的机制很复杂。
storm早期提供了一种transactional topology以支持exactly-once,大意就是每条记录必须完全处理完毕才能开始处理下一条,不用想就知道性能很差。
后来出现了trident、spark streaming等micro batch模型,对exactly-once友好了很多。换句话说,rollback的代价没有那么大了。
micro batch的另一个好处是写hbase性能会好很多,不用每条记录一次put。
个人感觉,选择哪个工具还是要看自己的应用,一般情况下spark streaming是最优的。
如果有特殊需求,比如实时性要求较高、DRPC等,可以选择storm/trident。
处理模式
只是总结下常见的数据处理模式,不限定于具体工具,不限定于具体应用,不区分批处理与实时。
基础:filter、transform、aggregate
高级一点的:windowing analysis、graph processing
更高阶的:machine learning、visualization
我暂时能想到的就是这些。
对于基础,用任何工具去做都很简单。但对于其他模式,是有所谓的最佳实践的。
比如图处理,可以用MR去算,像page rank那样多次迭代。但更好的办法是用专门的工具,比如spark GraphX。
比如machine learning,可以用mahout或spark MLlib。
还是那句话,选哪种工具,看自己的应用场景。
Lambda Architecture
storm作者提出的一种架构:wiki。
大意就是说基于hadoop的系统都要是这样一种架构:有批处理和流处理两条线,数据是不可变的,同时进入批处理系统和流处理系统。批处理用于处理历史数据,流处理用于处理近期的数据。查询时会同时从两个系统中查询并合并结果。
这种架构已经经过实践检验了,据说linkedin内部一直是这样的架构(我觉得是因为他们有kafka)。其实很多系统也会不自觉的向这种结构发展。
但这种架构争议也很多。最大的争议是处理逻辑变化时,要同时更改两个地方的代码。摘录一段:
以类推方式,想想跨数据库ORM框架臭名昭著的困难,试图跨越这两个系统提供一个近似标准接口语言也会如此,试图在两个不同编程范式的顶部建立一个抽象层是非常难的。
如果流处理足够强大,也许就不需要批处理部分了。但这种合并了批处理和流处理的方式还是值得参考的。
其实,很多理论未必是真理,尤其是提出时间不长的。比如CAP就有很多争议。BASE更是牵强。
调度系统
这是永远的痛啊。。。hadoop圈中一直没有一种好用的调度工具,勉强能用的是oozie和azkaban。
如果用crontab能满足的话,还不如用crontab简单直接。
所以很多公司都会开发自己的调度系统。
oozie的配置太过复杂了,让人望而生畏,workflow的管理也很不方便,不直观。其他传参数、传第三方lib之类的,也很麻烦。
azkaban的优点是强大的web界面,很多配置可以在web上修改。问题在于修改workflow很麻烦,不能部分修改,因为它是以zip包形式管理的,只能整个替换。更麻烦的是要修改自己的代码才能被azkaban调度。
如果一定要选的话,也只能是azkaban了。最近似乎2.7.x版本发布了,不知道会不会有些改进。
另外我能吐槽下linkedin么,似乎开源项目的代码质量都不高啊。。。我看过WhiteElephant的代码,这哥们以前不是写java的吧?我也看了azkaban一点代码,也不咋样。不过这两个项目的前端倒是都不错。
想看高质量的代码,可以看hadoop,我看过一点yarn和hdfs的,受益匪浅。
总结
只是个人感觉。
- 大部分系统从这几个角度去设计:storage/ingestion/processing/analyzing/orchestration。
- 能用hive的尽量用hive,甚至整个pipeline架在hive上也可以,有很多好处:hive原生支持parquet/avro;支持各种计算引擎;可以方便的对接各种BI工具和查询工具;支持hiveserver;后续的索引支持;对hive sql的扩展更方便,写UDF比写MR/spark简单的多;方便做各种优化等等。说实话,我也不愿意写一大堆代码做ETL和各种计算,sql要简单的多。如果以后spark sql成熟了,也可以考虑。
- 不能用/不好用hive的地方,用spark。不要用MR。写scala,不要写java。
- 尽量用parquet+snappy。
- 数据导入一般是flume+sqoop。
- 需要可实时读写的持久化存储时,考虑hbase。否则一般是hdfs。
- 实时处理优先考虑spark streaming,不能满足需求再考虑trident,最次storm。
- kafka就像润滑剂一样,设计系统碰到困难时,试着扔个kafka进去。
- 牢记,抱着spark的大腿总是没错的。
实例
书中给出了几个实例,具体的设计过程我就不列了。看看架构图吧。
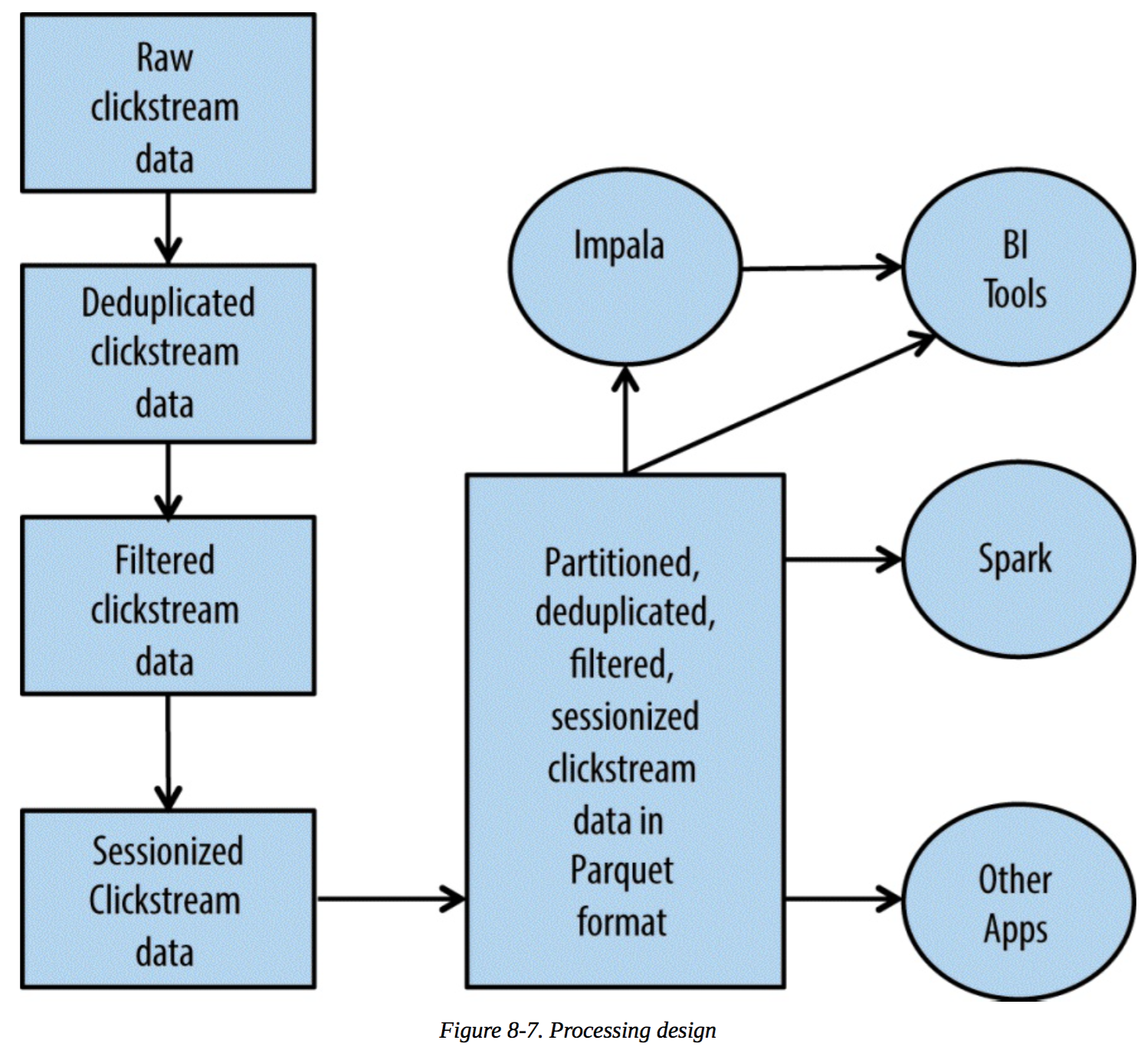
点击流分析
特点是完全离线处理。注意数据处理过程中的sessionization.
反作弊
实时+离线,就是所谓的lamda architecture。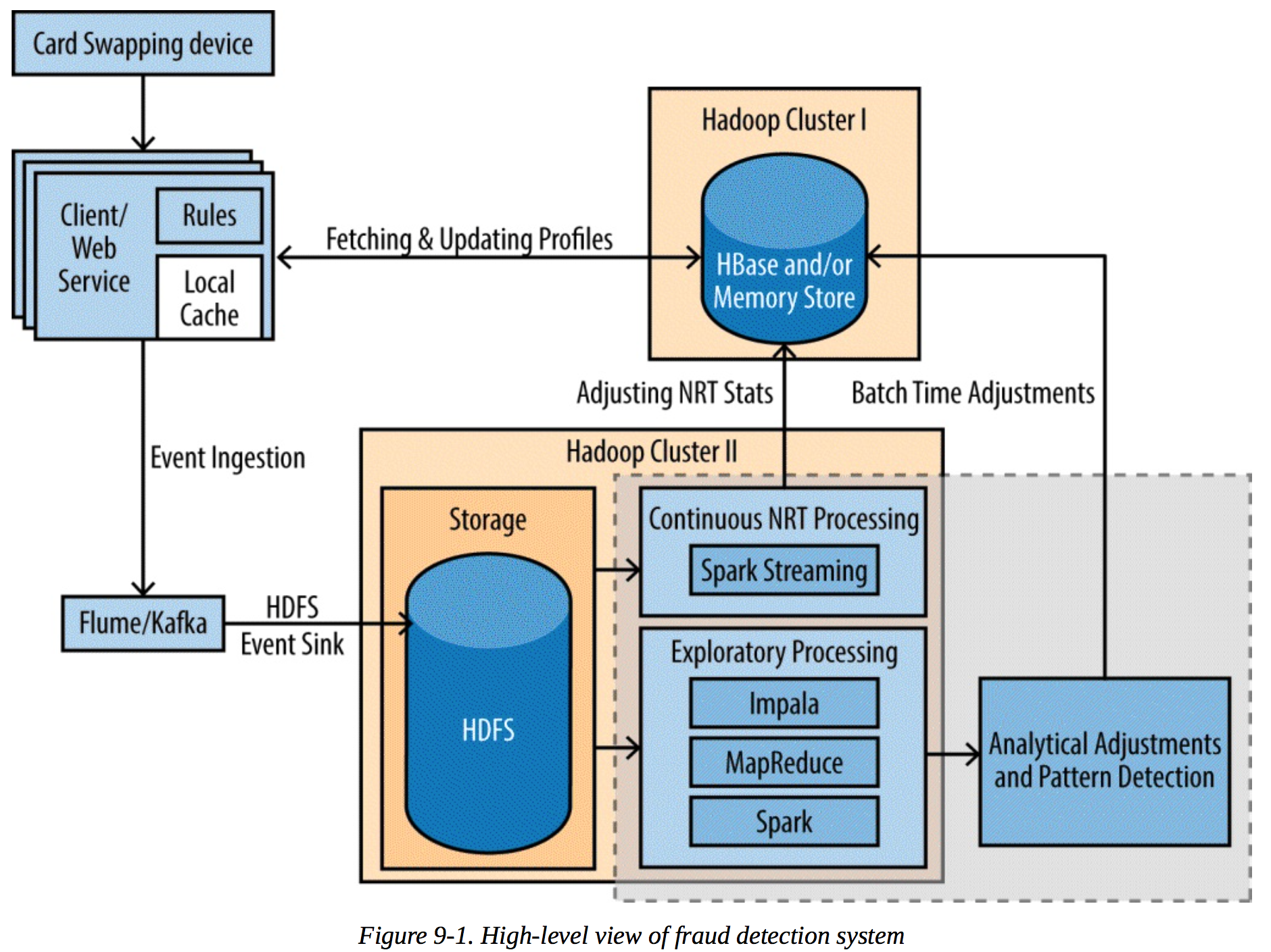
数据仓库
跟传统的数据仓库概念差不多。只不过是基于hadoop的。
数据仓库的关键在于建模,很多时候要反范式。从架构图上看不出什么东西。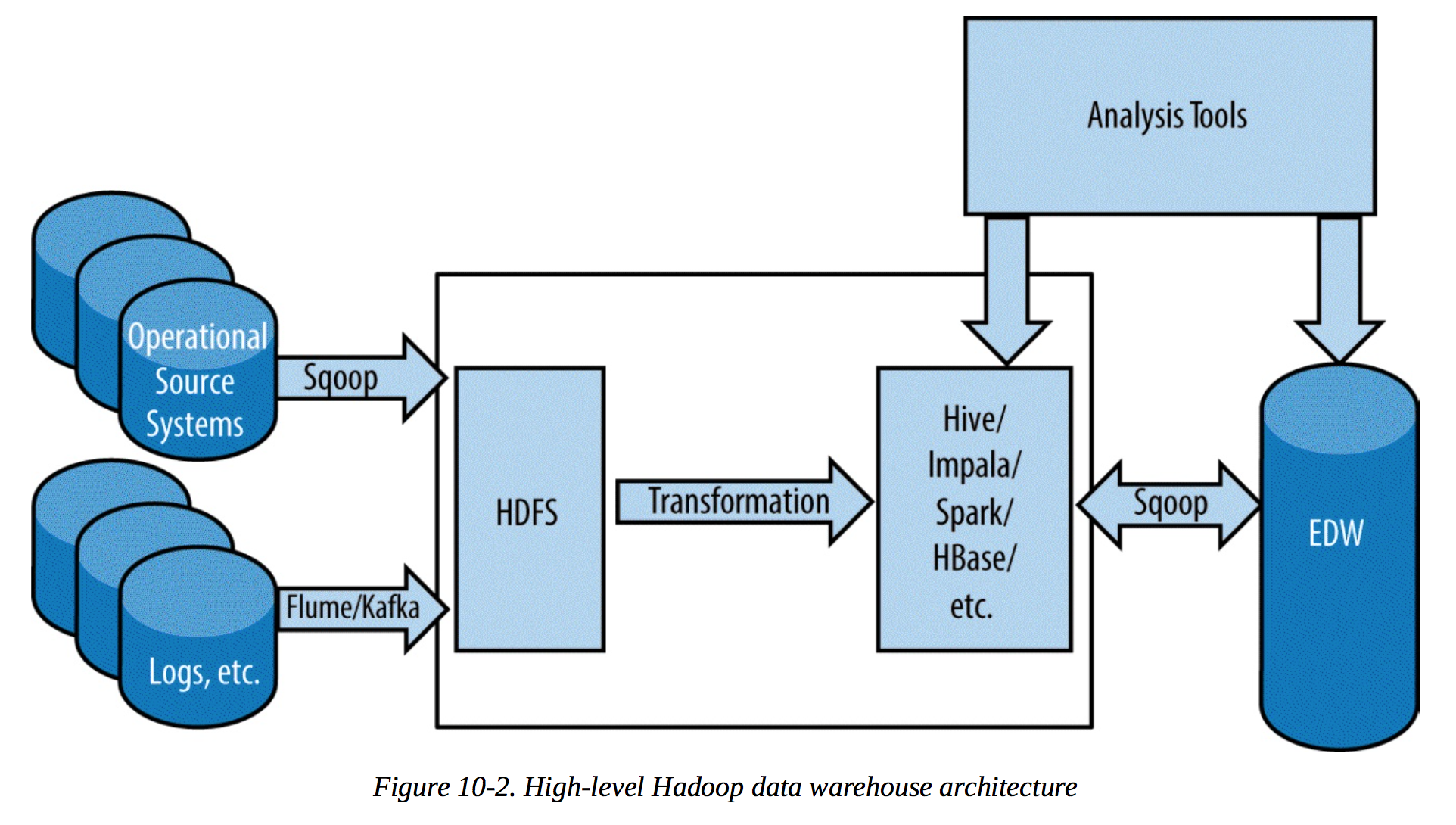
事实标准
跟技术无关的一些想法。
hadoop已经是大数据处理事实上的标准。谈到大数据,必言hadoop。hadoop应该称为data hub更合适,各种技术、框架依附于它而存在。
作为大数据处理技术,hadoop未必是最早的,未必是最NB的,却是最普及的。
在我心目中,hadoop生态圈中各种项目的“江湖地位”:
- 事实标准:hdfs、yarn、hive、zookeeper
- 将成为事实标准:spark、kafka
- 能独当一面:hbase、flume、storm
- 能解决特定问题:pig、sqoop、oozie、azkaban、impala、mahout、hue
- 快退休的:MR、tez
详细的项目列表见这里,虽然我觉得其中一些项目不属于hadoop生态圈。
纯粹凭感觉分类。对我来说,大部分项目属于第4类,只是能解决特定的问题。如果能做的更好,覆盖特定领域的大多数问题,就会进化到第3类,能独当一面。至于能否进化到第2类甚至第1类,不光看技术,也要看推广,甚至是运气。
话说,前些年如火如荼的nosql运动好像沉寂很长时间了?我记得当时隔几天就有一个新项目冒出来,mongo/redis/riak/neo4j/cassandra/hypertable/couchbase,还有各种不知名的项目。
还是我太久没关注。。。
似乎只有mongo和redis活的还不错。
题外话
这篇文章写了近2周。
近一万字,我特么都没想到写了这么多。。。
借着总结这本书的过程,沿着书中的脉络,也总结了自己的一些想法,想到哪写到哪,比较随意。
夸张点说,我个人关于hadoop的所有理解,都总结在本文中了。
以后没事再来翻翻。碰到一些架构上的问题时也可以做个参考。
我看技术类书籍的习惯,喜欢在书上写写画画,文中很多内容其实是当时的笔记。
如果不能直接在书上写,一定要开着xmind,一边看一边总结。
个人觉得这样是比较好的读书方法。
