以前写的一篇文章。
折腾了下windows下的编译、部署、使用。纯粹为了好玩,肯定不能用于生产环境。
在windows中编译hadoop
以2.5.2的代码为基准。系统为32位WinXP SP3(虚拟机)。
前置要求
看BUILDING.txt:
|
|
大多数都好说,有几个要求比较麻烦:
ProtocolBuffer
protocbuffer项目迁到github了,目前好像最新是3.0版。
以前的版本还可以在google code上下载。直接下载编译好的:https://protobuf.googlecode.com/files/protoc-2.5.0-win32.zip
解压后将protoc.exe加入PATH。我是直接扔到c:\windows里了,省事。
Windows SDK
可以去http://www.microsoft.com/en-us/download/details.aspx?id=8279下载。
但这里给出的是在线安装,非常非常慢。还是下载完整的程序自己安装吧。
完整的iso在这里下载:http://www.microsoft.com/en-us/download/details.aspx?id=8442。
注意根据需要选择32位或64位版本。
安装也是一路next。
Unix command-line tools
很多文章推荐cygwin。但是cygwin太重量级了。
我推荐直接安装git bash,它自带一个MinGW32,包含常用的linux命令。
去http://git-scm.com/download/win这里下载并安装。注意安装中有一步询问是否将相关命令加入PATH,选择加入。
其他依赖就很简单了。记得把相关命令都加入PATH。在cmd里输入mvn/protoc/ls等命令验证下。
修改代码
原来的代码直接编译有些问题。
主要参考这篇文章。
原作者说要改3个地方:
- hadoop-common-project\hadoop-auth\pom.xml增加一个依赖org.mortbay.jetty:jetty-util。在2.2.0确实有这个问题。但2.5.2已经修复了。
- 修改hadoop-common-project\hadoop-common\src\main\native\native.sln。将{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Win32.XXX = Release|x64修改为{4C0C12D2-3CB0-47F8-BCD0-55BD5732DFA7}.Debug|Win32.XXX = Release|Win32。总共要修改4行。
- 修改hadoop-common-project\hadoop-common\src\main\native\native.vcxproj,将所有Release|x64替换为Release|Win32。
我估计如果是在64位系统中编译,2、3两步是不用改的。
(我想在Win7 64位下测试下的,但Windows SDK死活安装不上,看日志里有报错vcredist_x64.exe installation failed with return code 5100,google的话能找到这个链接:http://support.microsoft.com/kb/2717426/de。但按这个链接卸载了vcredist也不行。折腾了半天。为这个重装系统也不值得。)
编译
进入Windows SDK 7.1 Command Prompt,开始编译:
|
|
编译成功后在hadoop-dist生成tar包。和linux一样。
一些注意事项
JDK的路径不要包含空格
hadoop的代码所在路径尽量简短。比如e:\h252
执行命令时总是出现一个warn:unable to load native lib。但编译时其实编译了native库的,开debug日志似乎是说hadoop.dll有问题,暂时不明白是怎么回事。
虽然我是32位winxp下编译的,但拿到64位win7中也能用,因为我只是当做客户端来用,访问hdfs,提交job之类的。如果在windows中部署集群估计就不能通用了。
其他一些事项见BUILDING.txt
windows客户端使用
这个客户端可以在windows下读写2.5.2、2.2.0的hdfs。可以向2.5.2的yarn提交任务,不能向2.2.0的yarn提交任务,见MAPREDUCE-4052。(有人给出过解决方法,但只是临时方案,比较麻烦)
在32位WinXP SP3和64位Win7中测试通过。
设置JAVA_HOME
为避免一些不必要的问题,JAVA_HOME的路径不要有空格。
下载jce的jar替换JAVA_HOME/jre/lib/security中的同名文件。如果是OpenJDK不用替换。
修改HADOOP_HOME/etc/hadoop/hadoop-env.cmd:
|
|
kerberos认证
首先安装kerberos的win客户端:http://web.mit.edu/kerberos/dist/kfw/3.2/kfw-3.2.2/kfw-3-2-2.exe。现在有4.x版本的了,但我还是觉得这个3.2的用着方便。
设置c:\windows\krb5.ini的过程不多说了。
认证首先要有keytab文件。
win版的kerberos似乎有些问题,必须手动设置一下票据缓存的位置,否则hadoop认证时会失败。而且在win7下和winxp下输出也不同。
Win7下的输出: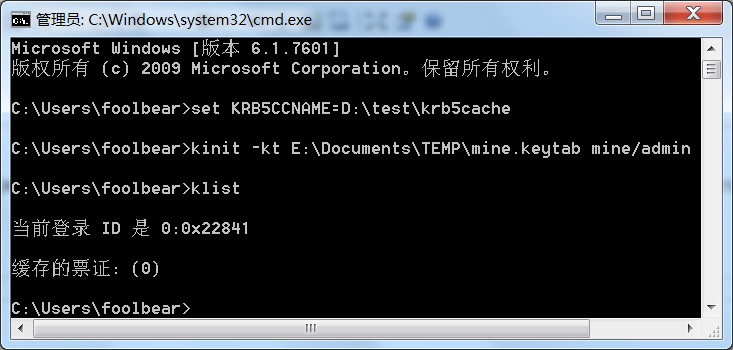
WinXP下的输出: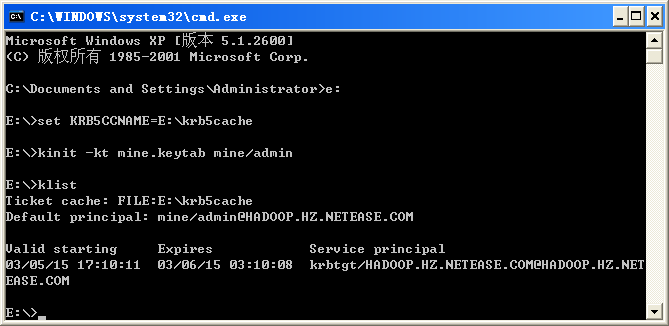
KRB5CCNAME环境变量可以设置为任意文件名,有权限就行。
无论如何,如果kinit命令没有出错,就可以认为kerberos认证成功了。
访问hdfs和yarn
大多数命令都跟linux下是一样的。
执行ls命令验证下: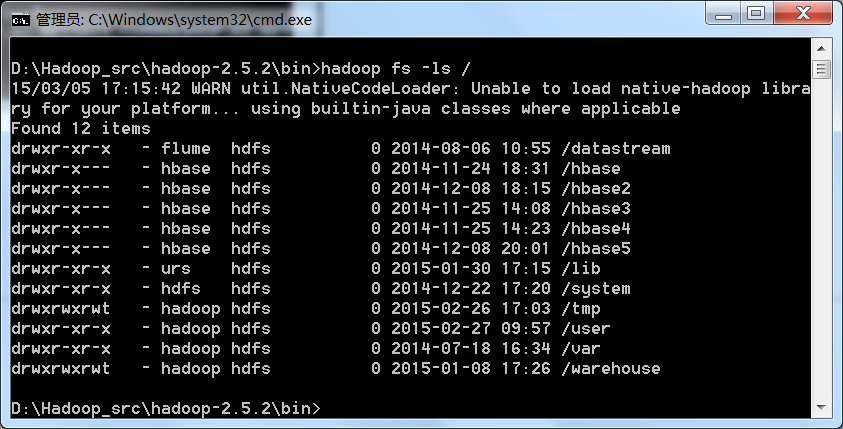
提交一个wordcount任务: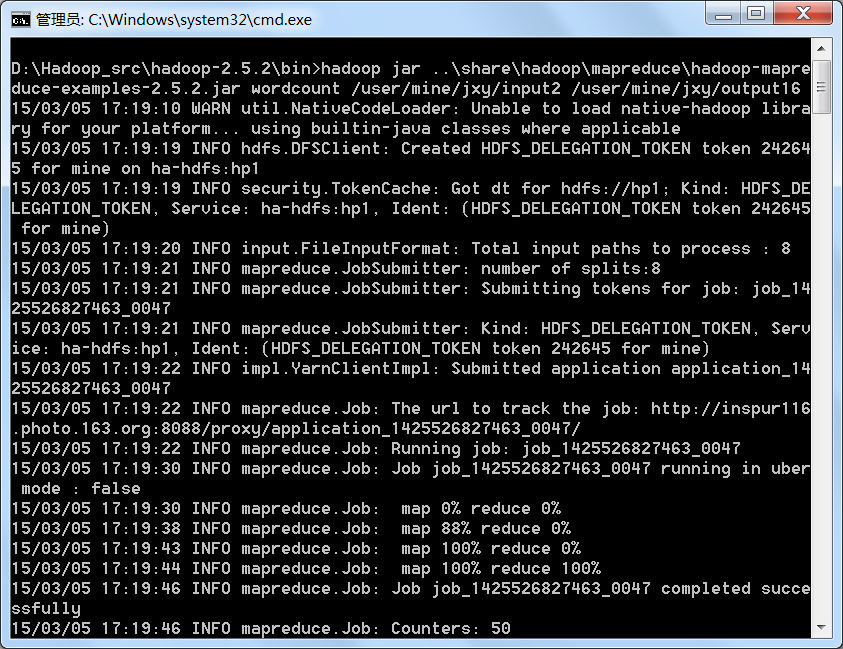
一些注意事项
win客户端不能-text lzo文件,似乎没有windows可用的lzo库。google的话能找到一个链接:http://gnuwin32.sourceforge.net/packages/lzo.htm,可以在win下安装,但试过不好使。
Unable to load native-hadoop这个warn,没找到办法消除。我已经编译了hadoop.dll,但还是有warn。可以set HADOOP_ROOT_LOGGER=DEBUG,console开下debug日志,看下具体的错误。暂时没法解决。
注意core-site.xml中的hadoop.tmp.dir设置,默认是/tmp/hadoop-${user.name},会在硬盘上自动建个文件夹。
在eclipse中读写HDFS
其实跟windows没啥关系。只是我一般用win下的eclipse,写到这正好想起来,顺便记下。仅供调试使用。
其实也可以用于Linux下,一样的道理。
关键问题就是如何获得必要的Configuration对象。正常情况下把core-site.xml和hdfs-site.xml放到classpath里,再conf.addResource(“hdfs-site.xml”)就可以了(core-site.xml会自动加载)。
但其实不是所有属性都是必要的。测试时完全可以在代码里手动设置,不用配置文件。
代码:
|
|
推荐还是尽量使用HA的配置吧。
加上maven依赖即可运行:
|
|
这种方法只能用于测试,把配置在程序中写死是很low的。
其实除了第一步设置winutil.exe的位置,其他代码在linux下是通用的。
题外话:
上述配置中的hp1/nn1/nn2等名称完全是客户端的,其实可以是任意字符串,只要能对应上就行,比如:
|
|
改成这样的配置也可以正常运行。因为hp1之类的名称只是逻辑上的概念,不会真的存在一个叫hp1的机器,客户端API会自动根据配置替换成实际的地址。
不过一般用户不用关心这个,直接抄我们配置好的hdfs-site.xml里的就好。
