看到一个很奇特的系统,虽然这个名字有些搞笑。。。
原文:https://www.cidrdb.org/cidr2024/papers/p46-atwal.pdf
官网:https://motherduck.com/
DuckDB是一个嵌入式的OLAP数据库,官方的slogan是:a fast in-process analytical database。某种程度上类似SQLite,但适用的场景不太一样,似乎是为了增强原有的单机数据分析场景,例如R、SPSS、Pandas等,让分析师们能用SQL Like的方式来操作数据。
这样的一种产品定位,有必要做成云服务(SaaS)么?“扩展性”这个词,似乎天生就与“嵌入式”相悖。唯一可能的场景是:有大数据集在云上(S3),拉到本地处理太过麻烦(带宽才是最宝贵的资源,而且上传/下载的带宽往往是不对称的);处理后的结果又要和本地数据进行进一步计算,并且希望在整个过程中能保持用户体验的一致性;同时数据可以在不同用户之间方便的共享。MotherDuck就是瞄准了这样一种场景。
看了下创始团队,跟DuckDB似乎是两拨人,虽然有合作。创始人似乎是以前google搞BigQuery的。
简言之,MotherDuck就是Serverless DuckDB,但跟通常的分布式数据库不太一样,一些设计选择值得思考:
- avoids scale-out:这是有些反直觉的,云数据库可以不需要考虑scalability;MotherDuck给出的理由是,通过分析发现,超过95% 的数据库大小小于1TB,超过95%的查询涉及数据小于10GB;相比scalability带来的复杂性和额外开销(scheduling、shuffle等),scale-up/down是更合理的选择;
- Hybrid Query Processing:查询可以横跨local client与云上,这就是DuckDB的特色了,不是嵌入式数据库的话还真做不到这点;个人感觉这也是从适应数据分析师的使用习惯上考虑的,降低云服务的门槛;换句话说,云只是local client的补充;通过引入一个特殊的bridge算子实现;
架构
无论如何,MotherDuck必然有一个client端的DuckDB实例;即使是使用WebUI,DuckDB实例也会以WebAssembly的方式运行在浏览器中:
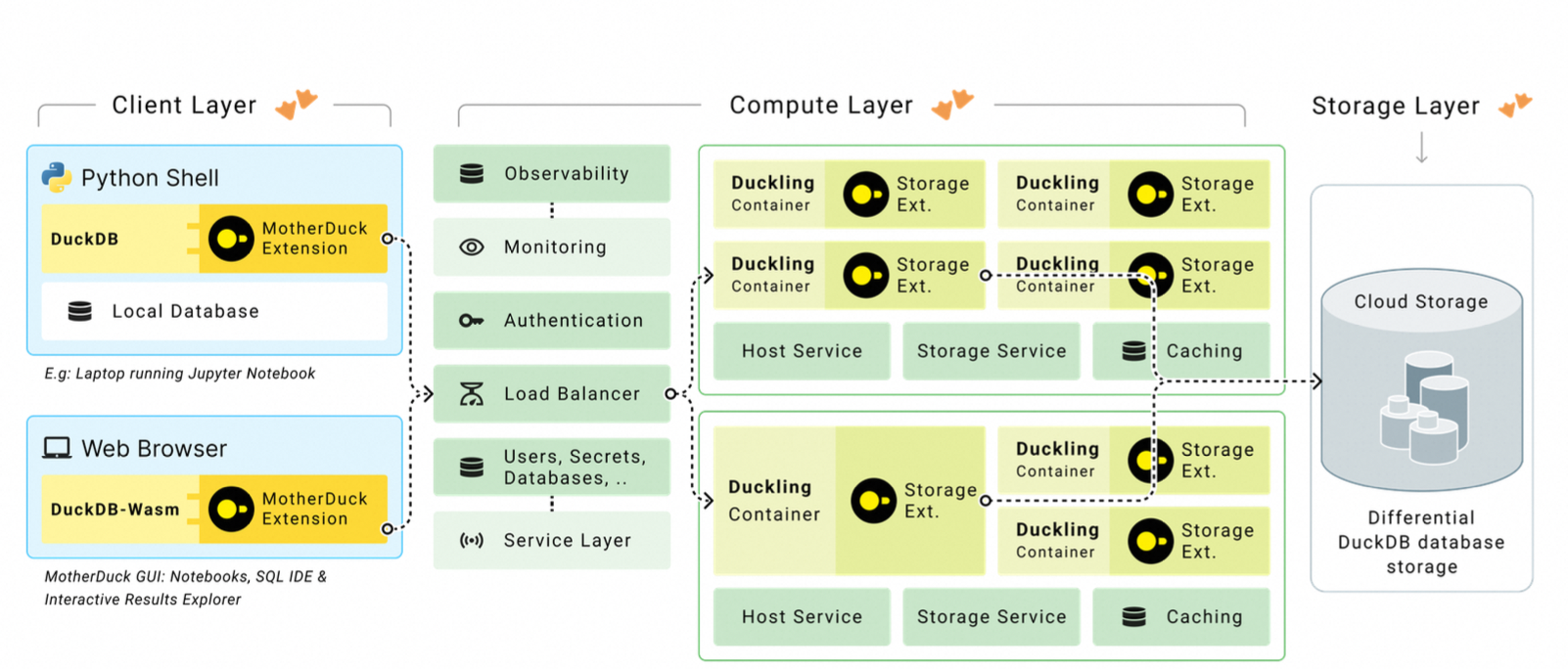
- 控制面:常规的元数据管理、鉴权、监控等;
- 计算层:动态分配的duckling容器,每个容器中运行一个DuckDB实例;容器可能随时发生scale-up/down,也会在没有负载时自动关闭,具体的策略没有讲;
- 存储层:这个就比较常规了,对象存储 + 本地SSD Cache;可以是parquet、CSV、JSON等格式;
- 当然除了cloud storage,也可以从本地加载数据;
- 支持快照、TimeTravel等特性;应该是扩展了DuckDB原有的存储格式,但没有讲细节;
从逻辑视图上来说,MotherDuck的数据是以database的形式来组织的,本地的database只能被local client关联,云上的database可以被多个duckling容器以只读模式关联,但只能被一个duckling读写;
此外,由于必然有一个client端的实例,result cache就变得比较简单。文中提到基于Web UI的各种自助分析(pivot、filter、agg等),其实都是基于一个client端的临时表:
|
|
相比服务端的result cache实现,复杂度降低很多。
Hybrid Query Processing
早在MapReduce时代,就有“移动计算比移动数据更经济”的说法。所谓的Hybrid Query Processing,关键也正是这一点。早些年还流行过“端云一体”,比如推荐引擎的推理模型可能是运行在手机端而不是服务端,大道趋同。
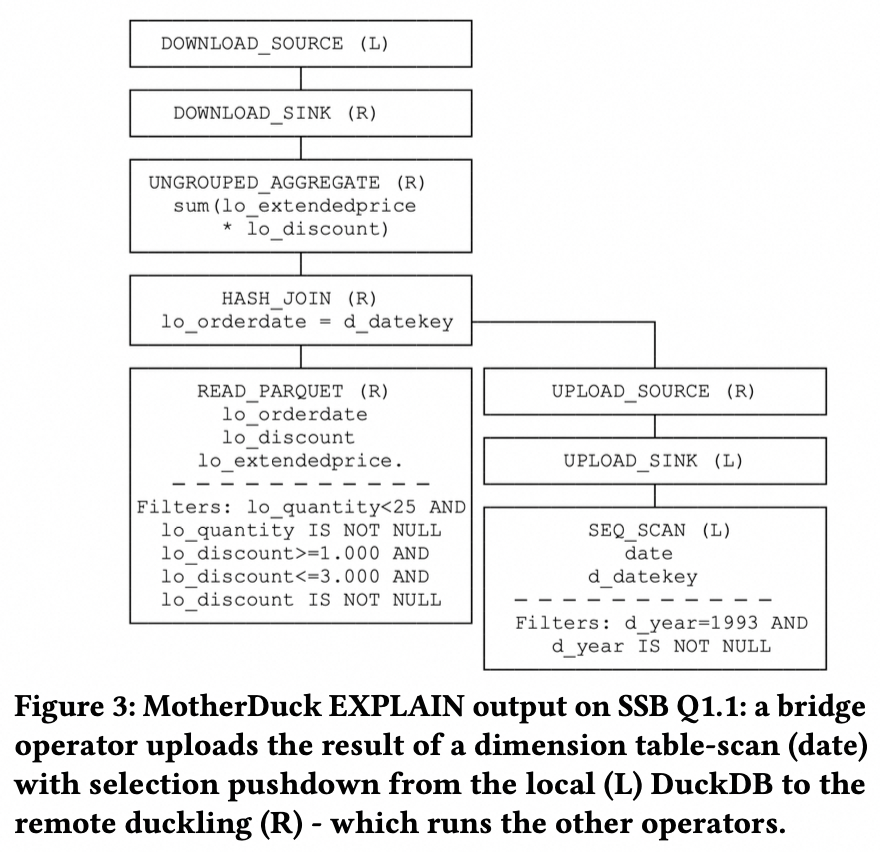
文中给出了一个执行计划的例子,数据从本地上传到云上,云上完成join操作,结果再下载回本地。从计划上来看,所谓的bridge似乎和传统的exchage有些类似?个人猜测:
- 所谓的bridge仅用于local和remote之间的数据传递;与MPP不同,并不存在duckling数据再bridge到另一个duckling的情况;毕竟scale-up解一切,也不需要MPP了;
- bridge也不会涉及数据的重分布,就是原样的传递;但文中特意提了下,bridge可以保证sink/source端的顺序一致,a feature expected by dataframe library users;
- 这就有个问题了,某些情况下,是否直接将本地的文件上传到云端后计算更简单?还是取决于local的计算能力,现在一些笔记本的计算能力真未必比ECS差;
- bridge可以简单的看做一个“生产者-消费者”模型,为此还引入了相应的流控机制;
- 用户可以手动指定每个table scan的运行模式(MD_RUN = REMOTE / LOCAL);
- 优化器的优化目标是:最小数据传输成本;这跟大多数优化器都不太一样;
DEMO
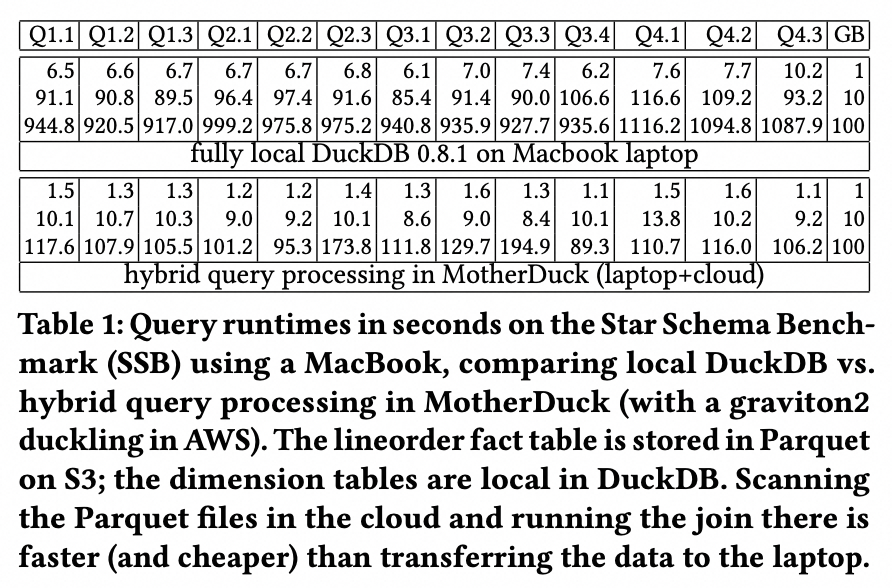
这个测试case也是很有意思:巨大的事实表在云上、较小的维表在本地。相比将事实表拉到本地来处理,必然是将维表上传到云上更优,无论是从执行时间还是成本的角度来考虑。但这其实发挥不出local client + cloud的优势,因为并没能利用上local的算力;如果local很弱,还不如全在云上计算。
比较合理的case是local和cloud都要处理大量复杂计算,但又需要对结果进行一些关联。例如local侧进行一些自有业务敏感数据的分析,cloud上进行一些公开数据集的分析之类。正如官网自述:
- DuckDB:turns your laptop into a personal analytics engine;
- MotherDuck:scales your laptop into the cloud;
总结
总体看下来,关键就两点:1. empower users to use more client-side resources;2. simplifying cloud data system architecture by using a scale-up approach;具体效果不好说,产品似乎也还未上线,官网也是那种涂鸦风,真的不是toy project么。。
附录:Scalability! But at what COST?
文中提到的这篇文章,也比较老了。大意是很多系统看着扩展性很好,但实际上并没有经过充分优化(甚至不如一个单线程实现),扩展性好 ≠ 性能好。
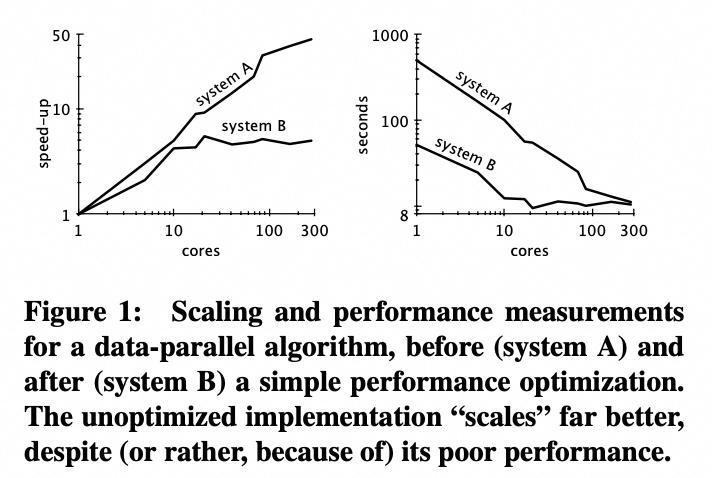
当初MapReduce有类似的争议:MapReduce: A major step backwards。现在看来,更多是一种权衡吧,编程范式的简化必然导致无法达到极致性能。这篇文章也并不是否定所有分布式系统,而是希望在作出各种设计选择前,更多方面考虑一下。
