俗务缠身,难得有个僻静的地方可以写些东西。
更新时间成功变为以“年”为单位。。。原因嘛,一是忙,二是懒,三是接收的知识量太多了。夸张点说,每天都能接触一些新鲜的东西。见到感兴趣的,我总是会先记下来,后续再慢慢研究,结果就越积越多。修福报之外也基本就是躺尸,于是blog的更新就完全随缘了。。。不过,抽空一口气写完,还是挺有成就感的。
《深度学习推荐系统》
很赞的一本书,偏算法。周末本来想随便看看,结果停不下来,一个下午+晚上一口气看完,很爽。
与我而言,这本书非常适合,解决了心中的很多疑惑。很大程度上是因为之前已经有了一些基础和了解,只是不成体系。
相比一些老掉牙的推荐系统介绍书籍(说的就是《推荐系统实践》),这本书才是真正紧跟技术潮流,也有一定深度。
InfoQ上还有一个专栏,内容是本书的一些节选。
总结下各种感想,不只是书中的内容。
关于特征工程
前段时间看了特征工程的一些文章。有句话说的很好:数据和特征决定了机器学习的上限,算法和模型只是尽可能逼近这个上限。虽然这个上限是啥,很难定义。
总结各种模型的演化,有两个趋势:
- 更复杂的特征表示 + 自动特征交叉,即所谓的“表征学习”,比如DeepWide中Wide相关的各种优化;
- 网络结构的突破,比如残差网络提升收敛速度、注意力机制、序列模式等等;
现在的很多模型还是在第一个方向上发力,随便改改就能“创造”一个新的模型。。。而网络本身的优化会更难一些。
特征工程的本质就是数据建模:你应该以什么样的方式去定义、理解你的数据,背后是对自己数据、对业务的深刻理解。以前只能靠人工来组合和选择特征,大多就是凭经验,很苦逼。现在的趋势是向自动特征工程转变。
常见手段:
- 缺失值处理:“缺失”本身也是一种特征;
- 数值特征:离散化、标准化与缩放、数据平滑;
- 类别特征:one-hot、multi-hot、序列编码、embedding;
- 多值特征、时序特征:简单做法就是embedding后再pooling;也有更复杂的处理,比如注意力机制;
话说,我一直搞不太清楚sparse/dense特征的区别。从字面来看倒是很好理解,但稀疏/稠密的分界点在哪里?某个特征,有n个0就是稀疏,n-1个0就是稠密?只知道,one-hot后的特征大多是sparse的,embedding都是dense的。
前深度学习时代
经典模型的好处就是可解释性强,易于训练和部署。
借用书中一张图(根据书中插图自己画的):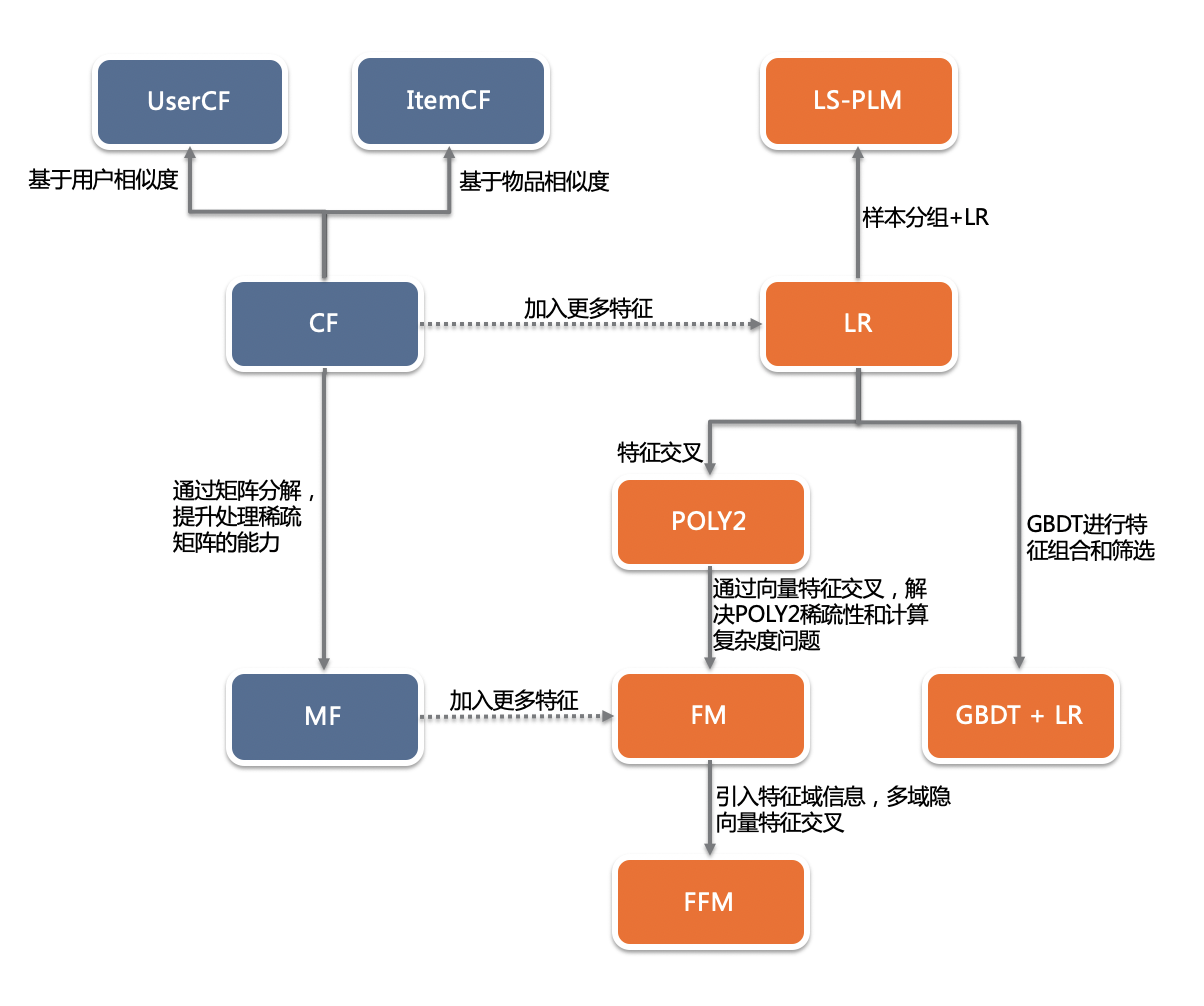
最经典的推荐算法应该是协同过滤(CF),直到现在,ItemCF和UserCF也是最常见的召回策略。
由CF又引申出矩阵分解(MF),将共现矩阵分解为用户矩阵和物品矩阵,本质是找到一些“隐向量”将user和item关联,解决CF中无法处理向量稀疏,泛化能力弱的问题。这里其实也有一些embedding的思想了:用一个低维向量来表示item和user。
话说我第一个知道的推荐算法其实就是CF,那还是hadoop 0.2x的时代,当时好像没啥现成的库,算法同学们在MR里用3个嵌套for循环计算矩阵乘法,印象深刻。。。
矩阵分解常用手段:
- 特征值分解:只能用于方阵;
- 奇异值分解(SVD):要求矩阵是稠密的,复杂度O(mn^2);
- 梯度下降:找到函数的局部最小值;过拟合的问题还是存在的,需要L1/L2正则化;
这个时候的推荐系统,应该叫做“洪荒时代”,还没有“模型”的概念。但其实user和item的ID也是一种特征,CF可以看做是只使用了ID一个特征的算法。很自然的,为了提升算法效果,需要引入更多特征,于是一系列经典的机器学习模型粉墨登场。
- LR:经典到不需要介绍。缺点在于表达能力不强,无法做特征交叉;为啥特征交叉如此重要?“辛普森悖论”了解下;
- POLY2:特征自动两两交叉;会导致原本就稀疏的数据更加稀疏,而且训练复杂度上升到O(n^2);
- FM:为每个特征学习一个隐向量;特征交叉时使用隐向量内积作为权重,降低训练复杂度;
- FFM:为每个特征学习一组隐向量,分特征域;特征交叉时使用对应特征域的隐向量内积;效果更好,但训练复杂度又上升了;
- GBDT + LR:特征工程模型化的开始,自动生成并筛选特征组合;跟现在的embedding层很像,真正实现所谓的“端到端”训练;
- FM/FFM等只能做二阶的特征交叉,而GBDT无此限制;
- GBDT进行特征转换、LR进行CTR预估,是两个独立的过程;
- LS-PLM:简单点说,就是对样本先做多分类(softmax),然后在每个分类内部训练LR模型,最终的CTR,是每个分类内部CTR的加权平均;
- 脱胎于电商场景:在训练一个女装item的CTR模型时,明显不希望受到男装item数据的影响;
- 从某种意义上来说,已经有神经网络的雏形;
深度学习时代
我记得深度学习刚开始火起来的时候,还被称作“无监督的特征学习”。深度神经网络(DNN)NB的地方就在于可以从原始的特征中学习到更复杂的特征,比如图像识别中那个经典的“点 -> 边 -> 物体”的例子。从这个角度来说,DNN天生就适合用来解决特征交叉的问题。
- 深度学习模型的表达能力更强,能挖掘出更多数据中潜藏的模式;
- 深度学习的模型结构非常灵活,能根据业务场景和数据特点,灵活调整;
同样借用一张图: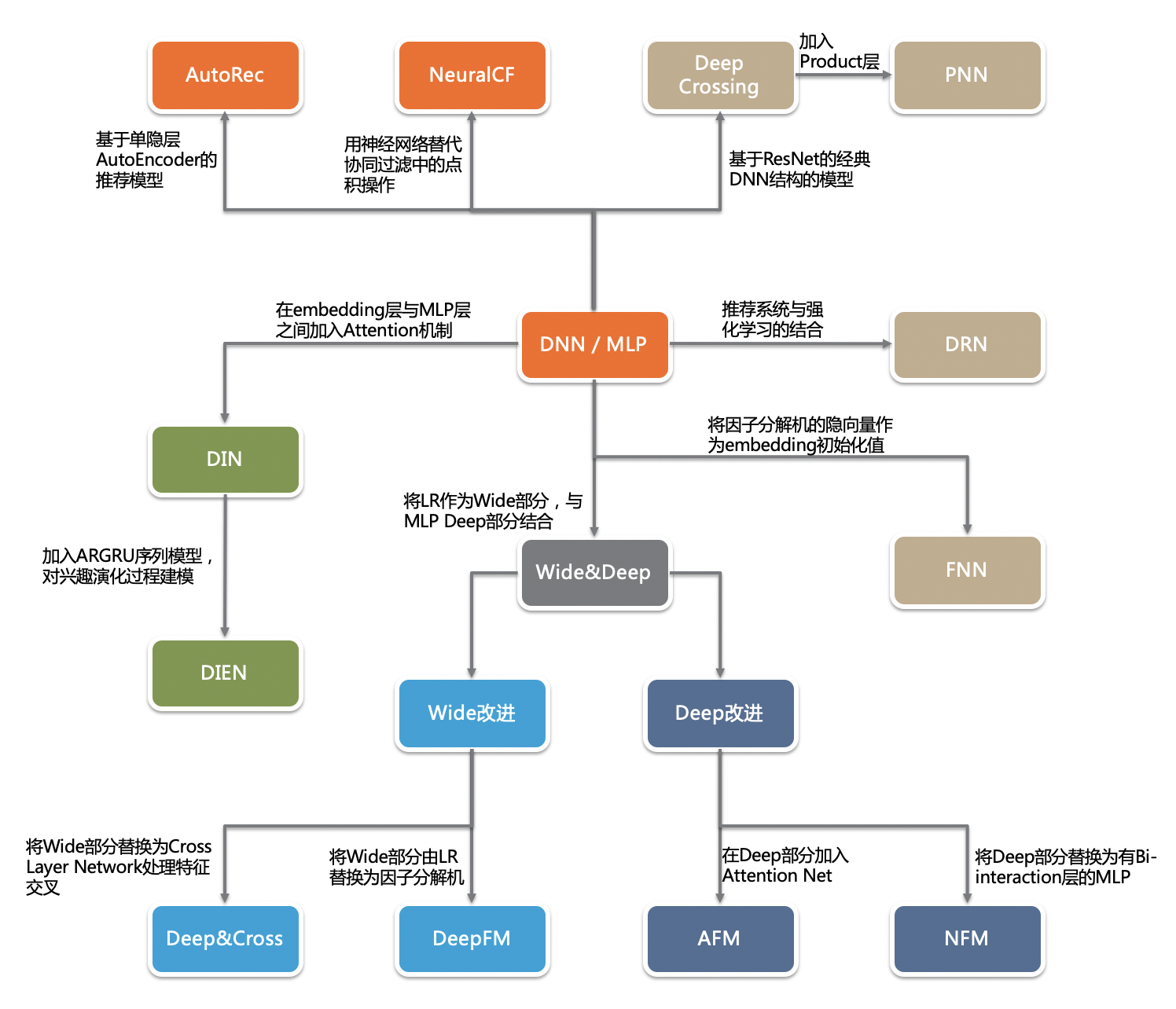
- AutoRec:自编码器,预测用户对物品的评分;单隐层的神经网络,结构上跟word2vec一致;
- Deep Crossing:embedding+多层神经网络的始祖;
- embedding层:稀疏的类别型特征转换为稠密的embedding向量,数值型特征不需要进行embedding,直接进入stacking;emb层一般是简单的全连接
- stacking:拼接embedding和数值特征;
- MLP层:多层残差网络(每两层增加一个短路:shortcut + element-wise plus)
- scoring:一般是LR
- NeuralCF:传统MF的加强版,广义矩阵分解模型;
- 传统的MF中,分解后的item/user矩阵其实就是embedding,但表达能力有限,可以引入DNN生成更复杂的embedding;
- 传统的MF直接用item/user emb的内积去拟合,也可以再套个DNN;
- 所谓的“双塔模型”,可以认为就是由此演化而来;
- PNN:对DeepCrossing的改进,不同特征的embedding不再是直接stack,而是两两乘积(element-wise),用以获取更多特征交叉信息,还有所谓的内积和外积的区别;
- Wide&Deep:可以说是目前影响力最大的模型,google还是NB;
- 记忆能力:可简单的理解为从已有的数据中,发现“规则”的能力。比如,如果特征A=male,那么score=1,这种非常直观的规则;如果是简单的LR,那么这个特征A的权重就会很高;深度学习中,由于特征经过了很多处理,又经过各种交叉,这种“规则”的记忆能力反而没有简单模型好;
- 泛化能力:处理未知数据的能力,或者说,处理稀疏特征向量的能力;
- Wide&Deep模型中,Wide部分负责记忆,Deep部分负责泛化;
- 难点在于,哪些特征进入wide,需要人工选择,抓住业务问题的本质特点:哪些特征是有强“规则”属性的?
- Deep&Cross:在wide部分增加更多特征交叉能力(cross网络);这也比较容易想到,就跟LR->FM->FFM的发展过程一样;
- DeepFM:用FM替代原来的wide部分;
- FNN:用FM参数初始化embedding层权重,加速emb训练收敛速度,也为emb预训练提供了借鉴思路;
- NFM:与PNN的结构非常相似,也是得到embedding后,再利用FM的思路,进行特征交叉;
- 注意力机制:这也是最近很火的议题,关键在于如何抽象用户的兴趣。
- 多值/序列类特征,一般的做法是embedding后sum polling,但这其实丢失了很多信息;比如用户收藏的商品id集合作为特征,对这个用户的某次点击,“贡献度”是不同的;更好的做法是加上一个所谓的“激活单元”;
- DIN:引入激活单元;其实也是一个小型的神经网络;
- DIEN:引入序列信息的处理,兴趣抽取 + 注意力机制;大概就是从用户的历史行为序列中抽取兴趣(GRU,类比RNN和LSTM),得到用户每个行为对应的兴趣状态向量,再叠加注意力机制;
- 但DIEN一看就感觉有些过于复杂,train/serving估计都很麻烦;后续有资料提到,线上可以将serving和兴趣抽取部分拆分部署,还抽象出所谓的UserInterestCenter,serving时直接取兴趣向量即可;但训练时还是端到端的;
- 书中还提了一下强化学习,怎么感觉就是模型的实时训练呢?可能训练方法不太一样,不是传统的梯度下降;
疑问:理论上,所有特征的emb直接concat后进入全连接层,就可以算是一种特征交叉了,可以学习到各个特征之间更隐式的关联。但DeepFM、NFM之类的做法,就是在concat之前,借鉴FM的思路先做一次特征交叉,可能会更有针对性吧。
纵观各种模型的演化过程,有一个趋势就是越来越贴近业务。为啥DIN/DIEN等模型看着很美好,但其他人都用不起来。因为只有在阿里的电商场景下,才适合这种数据模式,才有足够丰富的数据。没有一个模型能胜任所有业务场景,no silver bullet。
embedding是个好东西
简称emb,其实就是用一个低维的稠密向量表示一个object,这个object可以是任何东西:词、商品、用户、节点等等。emb表示可以揭露object之间的潜在关系,有那么一点“本体论”的感觉:透过现象看本质。摘录一句话:“基于内容表征的推荐算法往往在推荐的公平性有着更大的优势,它关注的是商品以及用户行为中的内容信息,而非协同过滤算法所关注的用户行为带来的关注度”。
word2vec可以算是emb相关研究的起源,大概就是结合语料,根据当前的词,预测前后n个词的概率。有skip-gram和CBOW两种模式,常用的似乎还是skip-gram。网络很简单,单隐层: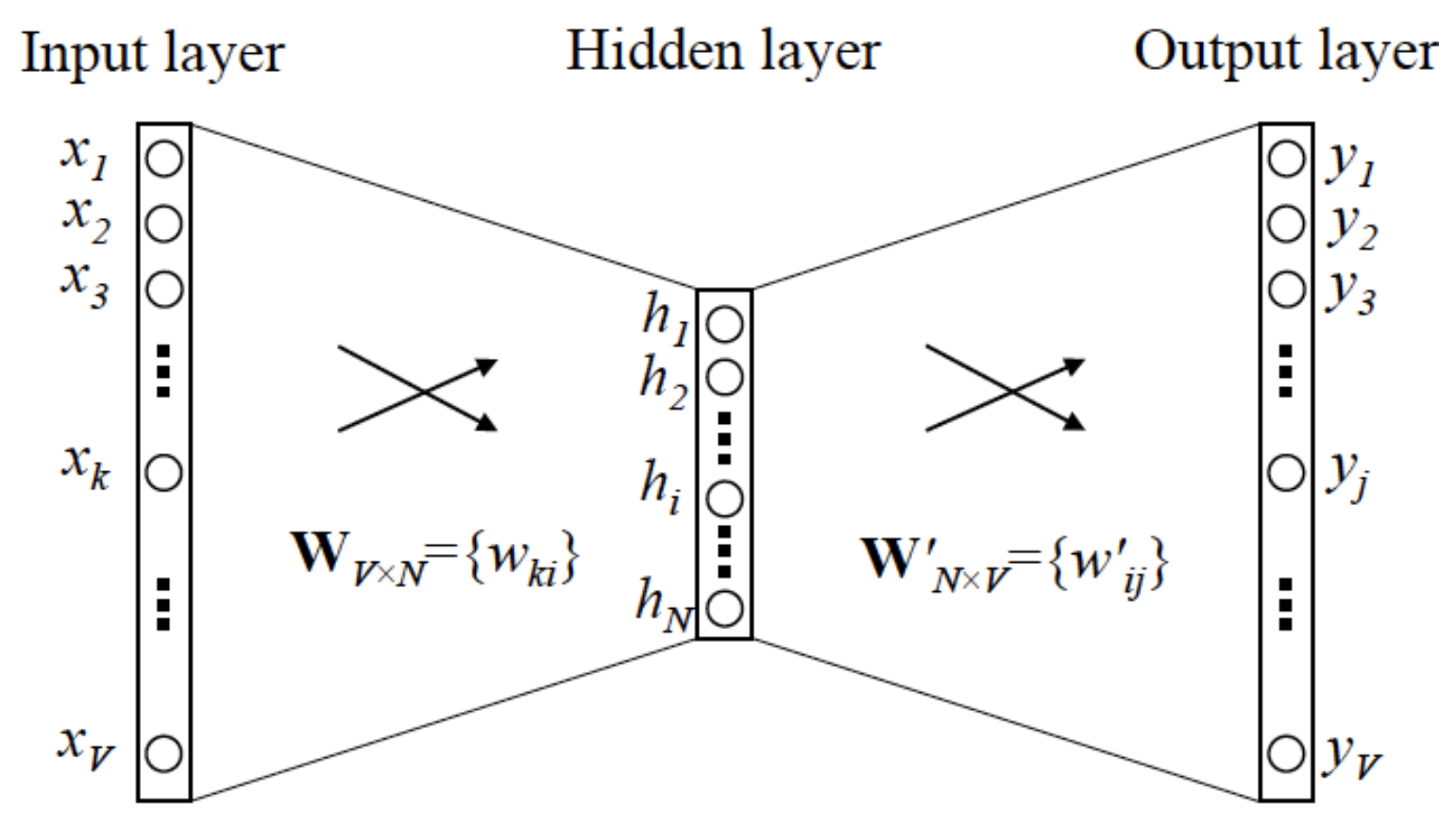
训练过程就是根据滑动窗口,找到所有出现的word pair,输入/输出都是词的one-hot向量,最终训练得到的网络中的权重即是look-up matrix。训练时还有一些优化手段,负采样之类的。
不过我有些疑问,这个训练过程似乎没有用到词的前后顺序等信息?跟NLP常见的隐马尔科夫之类的思路不太一样。
广义上来讲,word2vec不只用于NLP,可以为一切“序列”生成emb:
- item2vec:在推荐领域的应用,利用物品序列生成emb;
- graph embedding:为图中的每个节点、边甚至子图生成emb;因为item2vec只能利用序列数据,不能利用item之间的关联(词之间的前后关系?),而graph能引入更多结构化信息;
- DeepWalk:比较基础的方法,随机游走生成序列,再套用word2vec;
- node2vec:在deepwalk基础上,通过控制跳转概率,让emb抓取更多的结构性或同质性信息;
- EGES:如何融合多种emb(比如根据行为的、根据图谱的),简单说就是构建多个graph,训练多个emb,加权求最终的emb;可以部分解决冷启动问题(即使是新的item,也可以通过一些手段生成emb,比如类目);
graph embedding也是最近非常火热的主题了,但其实相关的研究很早就有了,最近只不过是借着深度学习的东风又火了一把,衍生出了专门的图神经网络(GNN)这一学科。借助深度学习,大规模的、异质图的emb学习,相关研究进展很快。
从工程的角度来说,emb的好处在于:
- 存储方便:相对于图、网络、树等复杂的层次结构,emb就是简单的float array,可以直接存储原始数据,也可以编码后存储;
- 计算方便:最常见的计算是emb相似度,借助局部敏感性hash等方式,可以做到大数据量的快速召回,业界也有Faiss等库;
- 局部敏感性hash:欧氏空间中,高维空间中相近的向量,映射到低维空间,也必然是相近的;高维空间中,相距较远的向量,映射到低维,可能相近;将所有的emb映射用同一个随机向量映射到1维空间,然后分桶即可。还可以使用多个hash函数进行映射;
emb在推荐系统中的应用:
- 最常见的,用于召回阶段,向量召回的算法和serving架构都已经非常成熟了;
- 预训练好后,作为其他模型的特征输入;
- emb本身就是十分重要的特征;也可以将emb计算相似度后作为下游的特征;
- 理论上,端到端训练是最优的,但计算量过大(emb层的参数占整个模型90%以上),所以一般都用预训练方式;
- emb一般也比较稳定,更新频率不需要太高;
- 现在还有所谓的model-bank:其实就是先训练好global的emb,下游的模型直接基于emb+自己的private信息去训练;
其他
如何合理设定优化目标:召回阶段和排序阶段的优化目标应该是一致的,比如都是CTR或都是CVR。尤其是现在很多系统还有多目标优化,比如淘宝OCPC的论文中提到,优化目标是广告主的CVR+平台的GMV;阿里的ESMM模型也会同时优化CTR和CVR,称作pCTCVR。
冷启动问题:
- 基于规则:热门或专家知识;
- 根据有限信息做粗粒度的推荐;
- 注册信息、第三方数据、item content;
- 基于已有的item进行估算:比如EGES、GraphSage等;
- 主动学习,引导用户输入;
- 迁移学习:冷启动的问题本质在于数据不足,可以将已有的其他领域的数据或知识,用于本领域的学习;
- 探索与利用:经典的explore/exploit问题,也被称作多臂老虎机(MAB)问题;
- 在传统的MAB问题中,所有老虎机对用户一视同仁,所以不是个性化的;常见解法:e-greedy、tompson sampling、UCB等;
- 基于上下文的MAB:加上各种超参数,一定程度上解决个性化问题;
- 传统的MAB解法无法与DNN结合,强化学习算是另外的一种思路;
- 除了用于冷启动外,也可用于挖掘用户新兴趣、增加结果多样性;
评估方式:
- 离线评估:常用的就是AUC(P-R曲线);
- 离线仿真:难点在于如何回溯数据,往往要做一些快照机制;
- 线上AB:直接对比业务指标;
- interleaving:与传统AB的盲测不同,将所有的版本都暴露给同一组用户;能测出用户对不同算法的偏好度,但并不是算法的真实表现,需要和AB搭配使用;
工程上:
- 深度学习现在基本是TensorFlow一统天下了吧?传统的模型训练还有spark mlib,mahout什么的已经是故纸堆了;
- 简单的模型用PMML,复杂的DNN模型tf serving;我也基于TF写过java/C++的inference,还挺简单的;
- lambda还是主流,kappa还是不成熟;
- 题外话:kappa这种架构,有种为了追求完美统一而强行使用的感觉。我们打工人还是讲工程效率的,lambda不完美,但能用,而且搭起来快,就先用着。我天天用着老掉牙的ibatis,我说啥了。。。
碎碎念
推荐系统天生就是一个强data-driven的系统,关键不在于模型和算法的选择,不能拿着锤子找钉子。根源是对数据、对业务的理解。我看到的算法同学,从来没有凭空在那边“炼丹”的,都是深入业务,选择特征/算法,不停验证猜想。有人说推荐系统就是揣摩人心,还有些道理。
工程和算法的区别也没那么明显了,往往要算法能力 + 工程能力双肩挑。
深度学习依旧热门,但已不是新奇的利器,在慢慢变成基础设施。
仔细想想,为啥需要模型这种东西呢?应该是为了泛化。如果我的计算能力足够强大,直接对user ✖️ item算一遍笛卡尔积,是不是也就不用inference了?
搜索/推荐/广告/投放
这一年多来,接触了不少系统。搜索、推荐、广告、投放这几个词经常在眼前晃悠。在组织架构上,这几个相关的系统也一般是在同一个大部门中。我一直在思考他们之间的区别。
为啥说他们很相似呢?因为他们的本质都是“流量分发”:一个用户进来后,给他展示什么样的结果(item)。广告banner可以是流量分发,微信朋友圈可以是流量分发,酒店中的小卡片也是流量分发。无非就是分发的“目的”不同,导致分发的“手段”也不同,进而系统架构上演化出各自差异。
说实话,流量分发已经不是什么新鲜事了。只不过流量红利的大潮过去后,对分发效率提出了更高的要求。之前看张小龙的演讲:在这个信息过载的时代,你看到的内容大都是被动的,所以流量分发类的系统才这么重要。而你看到的内容,决定了你是一个什么样的人,会有什么样的想法,技术在引导甚至控制人们的生活方式,细思极恐。。。这个时候我们已经不是“人”,而是“流量”。有句话怎么说的,“技术没有感情,资本没有良心”。我们经常忽略了,每个userId背后都是活生生的人。“待人以人”,何其难。
扯远了。
搜索:这里所说的搜索系统,跟传统意义(谷歌/百度)的搜索还不太一样,更像是“一个带query的推荐系统”,比如电商中商品搜索。搜索 vs 推荐可以看做主动获取信息 vs 被动接受信息。当然把网页看做candidate item也未尝不可。技术上有相似之处:倒排、分词、文本相关性(TF-IDF/BM25)之类的。但电商搜索有很多完善的结构化信息,而web搜索面对的是大量半结构化数据,质量参差不齐,所以技术演化方向上也有些不一样,比如PageRank,比如商品搜索可以对item做更多的语义化理解(认知图谱),召回的机制也远比传统意义上的“全文检索”复杂的多。
进而,SEO的手段也不同。不过,“砸钱”这个手段还是通用的。。。
话说,web搜索也一直在尝试提升结构化程度:schema.org。
投放:这个词的含义也比较泛,这里指的是电商类体系中“招选搭投”的投放系统。一般来说他应该是推荐、广告等系统的上游,负责将推荐出来的item真正透出。技术上来说,没有固定的形态,有些投放系统包含了展位/预算/疲劳度等广告逻辑,有些纯粹就是一个“通道”(串pipeline的)。门槛不高,相对于搜索/推荐/广告,技术属性更弱一些,每个业务都可以根据自己的需要快速搭建一个,直观体现就是公司内部各种投放系统林立。而且由于他跟业务比较近,往往要吃掉很多的业务逻辑,比如广告类的运营内容投放,和基金类的产品内容投放,逻辑就完全不一样。他的难点也在于对各种业务逻辑的抽象,而不是算法或数据。
真正要对比的,其实是广告和推荐。我一度觉得他们本质上差不多,都是会用到各种CTR模型,各种深度模型也是他们受益最大。但仔细想想,还是区别挺大的,“远远看着是清明上河图,其实画的是北京堵车”。
目标不同:
- 广告系统的目的在于攫取最大的利润(资本为了利润啥事都干得出来),是一种盈利模式;
- 推荐系统的目的在于改善用户体验,提高留存和黏性,偏产品运营,可以说是一种增长策略;
参与者不同:
- 广告系统中是三方博弈:用户、广告主、平台(媒体);
- 某种意义上讲,用户跟广告主是天然对立的,平台就是要在二者间尽量平衡,不能完全偏向用户,又要保证广告主的利益,还要建立长期的流量生态,平衡短期效率和长期繁荣;对于一个健康的商业模式来说,各方的目标应该是一致的;
- 通俗点说,就是要割韭菜,但是又不能割的太狠。。。
- 所以才会有eCPM、竞价、GSP等机制(基本都是google发明的);如果完全按点击率排序,广告主利益受损;如果完全按价格排序,用户利益受损;而eCPM综合考虑了各方利益,不仅包含了经济维度的出价,还包括了广告质量维度和用户契合程度;
- 根据eCPM的分解决定哪部分是由谁来预估是广告市场各种计费模式(CPC/CPM/CPS等)产生的根本原因;
- 广告系统还面临另一个问题:如何提升流量的竞争热度,比如冷门的时间段。如果所有的广告主只竞争热门的流量,毫无疑问平台的利益会受损;
- 推荐系统就很简单了,就是用户和平台两方,用户利益至上;
- 所以简单的按照CTR或CVR排序即可;
话说,现在各种计费模式,最火的还是OCPX类的吧。感觉就是先试投一段时间,以优化转化为目标训练模型,然后系统自动出价?确实对广告主而言,出价是个难题,出的低了没流量,出的高了又亏钱。决定你的出价的不是你自己,而是和你一起竞争的其他人。。。
从系统架构角度:
- 广告系统要复杂的多,毕竟是涉及到钱的。什么ADX、DMP、DSP、RTB之类的就不说了,单是广告投放的主流程上,就有排期、定向、保量、疲劳度、平滑消费等等复杂的逻辑;
- 广告系统会有一些特有的概念:排期、计划、单元、创意等等;
- 某些投放系统可能会借鉴广告的一些机制,但目的不完全一样;
- 推荐系统就聚焦的多了,召回 + 几轮排序 + 重排;
- 为啥要分多轮排序呢?因为越靠后的轮次,用的特征越多、越实时,模型也越复杂;
- 广告系统对RT要求是非常高的;而推荐系统相对宽松,甚至可以做成异步,还能结合端智能玩出更多花样;
- 从分发流程上,二者可能有些相似:本质都是“user + context -> item”,会有召回、模型打分、排序等过程;
从数据和算法角度:
- 对推荐系统而言,数据和算法才是核心;而广告系统没有那么强的数据驱动需求,他的“功能”已经是很强的价值;
- 或者换一种说法,缺少数据的广告系统还是能run的,而缺少数据的推荐系统基本就是个摆设;
- 广告系统能拿到的item特征、user特征,都相对较少;毕竟广告中的创意大多是“文案+图片”,跟商品之类的丰富结构化信息完全不可比;
- 平台没有广告主的数据、不知道这个创意适用于哪类用户,只有广告主自己知道;用户特征也是同理;但最近也有一些广告平台允许广告主自己上传一方数据;
- 在缺少item特征的情况下,广告系统十分依赖所谓的定向机制,尤其是look-alike,其本质就是“根据item找user:这些item投给哪些人更合适”;类似协同过滤的u2u2i;
- 推荐系统则是“根据user找item:当前用户推荐哪个item更合适”;
- 广告系统和推荐系统都会用到CTR预估模型,模型结构可能也类似,但目的完全不同:
- 广告系统中的pCTR,是有物理意义的,是真实的点击率预估,参与后续的eCPM计算;
- 推荐系统中的pCTR,往往只是用于作为分类算法的一个截断阈值;
大概就能想到这些吧。其实有时也很难区分,我就见过一些“四不像”的系统。。。
万物皆图
最近接触了一些图数据库和图神经网络(Graph Neural Network,GNN)相关的东西,总结下。
图数据库
以前,提到图,我想到的还是邻接矩阵、dijkstra、DAG之类的,这是从数据结构、算法的角度去看。但如果从数据本身的角度去看,相比传统的table schema,图其实更适合用来做数据建模,它表征的才是数据之间最本质的“关系”。现在的各种RDBMS,使用join的方式来关联各种数据,其实是非常笨拙的。无论OLTP还是OLAP,无论batch还是stream,join都是一个过于重的操作。那为啥我们还要这样去组织数据呢?换句话说,图数据库为啥不能代替RDBMS?还要啥雪花模型、星型模型啊,反正就是一张图,直接查呗。
我猜,很大程度上是因为大多数场景中,RDBMS已经“够用”。TP就不说了,很少做关系类的查询。即使是AP,大多数的查询也并不复杂,而且相关的优化手段已经研究的比较透彻。
图还有一个好处,由于它的组织方式非常自然,有助于发现数据之间的隐藏的关联。这有点像所谓的数据互联,或者数据孤岛问题。我们总是说要将所有的数据聚合到一起,1+1>2,挖掘跨领域的价值。但传统的“数据仓库”、“数据湖”之类的做法,并不能解决这个问题,他们只是把数据“放在一起”,或者说是一个统一的“数据源”。让你想找到数据的时候,可以从中随时找到、访问到,比如新加个特征之类的。而这些数据之间的关联,如何从这些数据的关联中发现信息,进而决策,完全是未知的,还是要依赖专家经验,这是一个“后验”的过程。正如《设计模式》《重构》不能完全解决代码的混乱问题,因为他们只是从技术的角度去看,还必须结合业务角度的领域建模。
图就不太一样,基于图中已有的关系我们可以做一些“推理”(从known facts中发现new facts),尤其是巨量的、异质的图,更容易挖掘出额外信息。比如知识图谱相关的研究,还有最近非常火、号称人工智能3.0的“认知智能图谱”。有人说“没有图谱的AI都是耍流氓”,虽是玩笑,也有些道理。
不是说基于数仓就不能做推理,而是数仓的这种数据组织方式天生就不适合,基于数仓搞等于人为给自己加难度。人生苦短啊。。。
数据的组织方式真的会影响使用者的思考方式,要不为啥思维导图这么流行呢。另外看看现在多少业务系统设计变成了“mysql表设计”:先有ER图,再有业务逻辑,这就是被RDBMS毒害了啊。
YY下,就像HTAP同时支持行存和列存一样,会不会未来出现一份数据多份存储,同时支持table view和graph view。spark中好像已经有了,但DB中还没见到。
RDBMS有SQL,图数据库也有gremlin,借用一张图: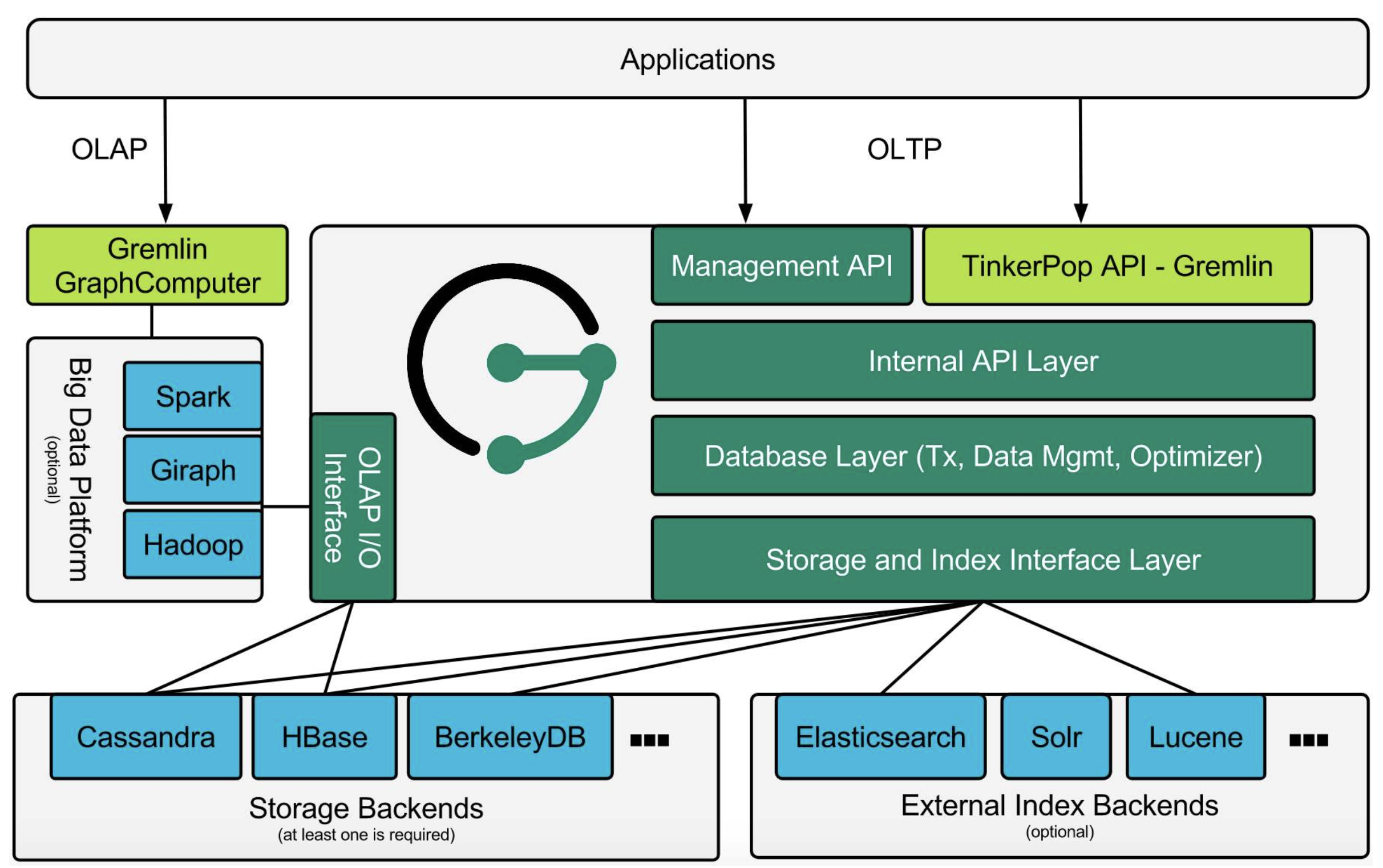
仔细一想,这图画的还是挺标准的:
- 大多数DB提供的都只是TP的能力;
- 通过外部的计算框架(spark之类),提供AP能力;
- TP和AP共享同样的后端存储;
- 特殊的地方在于,索引也用外部实现;这种用法也挺常见,典型例子就是用ES实现hbase的二级索引;
对于图计算:
- OLTP:基于遍历方式,一般只访问少量数据,速度快;其实就是多度查询+简单的filter和aggregate;
- OLAP:基于BSP模型(或GAS模型),一般要访问全图数据,计算复杂,一般是并行的;
- 常见计算模式:最短路径、最大连通图、PageRank、数三角形等;
- 常见推理模式:节点分类、属性填充、相似节点查找、链接预测、社区发现等;
有些特殊的计算模式(比如全图遍历),走两种方式都可以。
参考资料:
关于pregel:
分布式图计算模型Pregel详解
Pregel(图计算)技术原理
pregel模型,有点像design pattern中的visitor模式,又有点MPI的感觉(一种相当古老的分布式编程框架),带有非常明显的MR时代的痕迹。
Aggregator跟MR中的counter有点像,提供了一种全局通信、监控和数据查看的机制。
关于GraphX:
Spark图计算GraphX介绍及实例
资料有点老,又懒得看官方文档。点分割和边分割的区别很有意思。
基于图的推理
https://mp.weixin.qq.com/s/2D2hrnNcTlXsxuWaDcSJRQ
GNN
对于GNN我只知皮毛,听了些分享而已,但graph embedding是真好用。。。虽然相关的研究在深度学习之前就开始了。
图神经网络(GNN)是跟传统的DNN、CNN等不同的一种特殊网络:
- 网络的结构,包含着重要的信息;
- 节点和边,有自己的类型和属性;
知识图谱也算是一种特殊的GNN。常见的GNN还是大规模的、异质的用户行为图,或者user-item二部图。
经典的深度学习方法能够有效的处理原始的输入,比如语音、图片、文本,但对于上面的图结构信息,就不是很有效了。
似乎现在大多数的用法还是生成embedding:
- 无监督学习:相近的点就是有相似的emb;
- DeepWalk就是这种。主要问题是缺乏泛化能力,每当一个新节点出现时,它必须重新训练模型以表示这个节点。因此,不适用于图中节点不断变化的动态图;
- 有监督学习:其实就是分类。常用算法GraphSage;
- GraphSage 每个节点由其邻域的聚合(aggregation)表示。因此,即使图中出现了在训练过程中没有看到的新节点,它仍然可以用它的邻近节点来恰当地表示。
- GraphSage其实可以是无监督也可以是有监督,就是loss function的设计不一样;
GNN的训练方法还可以有各种升级:噪声处理、融入时序信息、自监督等等。
从工程上来说,GNN训练的难度在于如何并行。这里要基于一个假设:节点v的k跳邻域,包含生成节点v的k层GNN表示的充分必要信息。据此将整个图拆分并分发任务,典型的share-nothing。
参考资料:
https://zhuanlan.zhihu.com/p/105605774
https://zhuanlan.zhihu.com/p/62629465
https://zhuanlan.zhihu.com/p/136521625
再谈DDD
之前我也写过一些DDD(领域建模)的东西,但写完就忘。。。这套理论还是太抽象了,落地很难。但最近发现,从“重构”的角度去理解DDD,会更简单一些。如果上来就直接看DDD的各种概念,肯定就晕了。
首先要区分:应用架构 vs 系统架构
- 应用架构:你的代码如何设计,如何提升可读性、减慢腐化的速度,如何支持未来的需求,减少维护的成本;
- 这里要考虑的:类的设计、层次结构、命名、POM模块的拆分和依赖关系等等;
- 系统架构:不同系统之间的交互逻辑、职责划分;
- 这里要考虑的:请求链路、数据流、异常处理、HA等等;
DDD之类所谓的架构,指的都是应用架构。
面条代码大家都见过不少:
- 常规业务系统的分层架构:DAO/Service/Controller;所有的业务逻辑都写在service中,作为“上帝之手”操作各种DO,动辄上千行;如果不是把这个系统从头做起来的人,很难理解全部的逻辑;
- 业务逻辑、校验逻辑在多个地方重复,好一点的会抽出一个static utils类,差一点的就是每次都实现一遍;改一个逻辑要修改好多地方,还容易遗漏;
- 使用utils来封装业务逻辑也不是一个很好的选择;
- 同理,如果有外部某个依赖变化(比如第三方接口升级、DB表加字段),又是要改很多地方;每次改动还有巨大的回归工作量;
- 由于大量直接调用DAO和第三方接口,可测试性差,难以写UT;
造成这些问题的原因,就是代码缺少层次化的抽象,导致可读性、可维护性都很差。这种时候,我们一般会想到重构,但重构也是要讲究策略的。无论是94年GoF的Design Patterns,99年的Martin Fowler的Refactoring,都是通过一系列的设计模式或范例来降低一些常见的复杂度。但是问题在于,这些书的理念是通过技术手段解决技术问题,但并没有从根本上解决业务的问题。而业界通行的各种“法则”(比如SOLID,比如迪米特法则,比如DRY)又过于缥缈,只是一种“指导思想”。
DDD则是从“业务”的视角,尝试给出的一种比较通用的解决方案,或者说最佳实践,让代码有更强的业务表达能力,更好的沉淀领域知识,解放研发生产力。“DDD最大的好处是将业务语义显现化”,别总想着数据库(对不起我又吐槽了一遍)。
虽然DDD也是挺难落地的,可以说这种架构设计就是一个“逆熵”的过程,天生就是反人性的,面条代码更符合人的直觉。
注意:
- 用了DDD,代码会变多,性能未必好(毕竟增加了各种POJO的转换),但是在实际复杂业务场景下,DDD带来的价值是功能性的单一和可测试、可预期,最终反而是整体复杂性的降低;同时也会提升代码可读性,业务逻辑已经融入代码(比如类的拆分、命名,而不是一堆DO的字段和magic value),代码即文档;
- DDD并不是这类问题的唯一解,也未必是最优解,只不过很流行。而且DDD本身也是在发展的,DDD(蓝皮书)、IDDD(红皮书)之类的。
- DDD本身的实施细节也是有争议的,比如所谓的充血模型和胀血模型;只能说别在意那么多形而上的东西,抓到耗子就是好猫;
那么,我有个巨大的面条式service,如何拆分呢?直接说结论的话:
- 用Entity封装单对象的有状态的行为,比如业务校验;
- 用Domain Primitive封装跟实体无关的无状态计算逻辑;
- 用Domain Service封装多对象逻辑;
- 用App Service编排最终的业务流程;本质上,AppService还是“上帝之手”,但是它要操心的业务逻辑少了许多;
这里面涉及到很多DDD的术语和思想,直接看结论不是很好懂,不过核心还是基于对业务流程、use case的理解。
DDD的架构主张
所谓的六边形架构、洋葱架构:
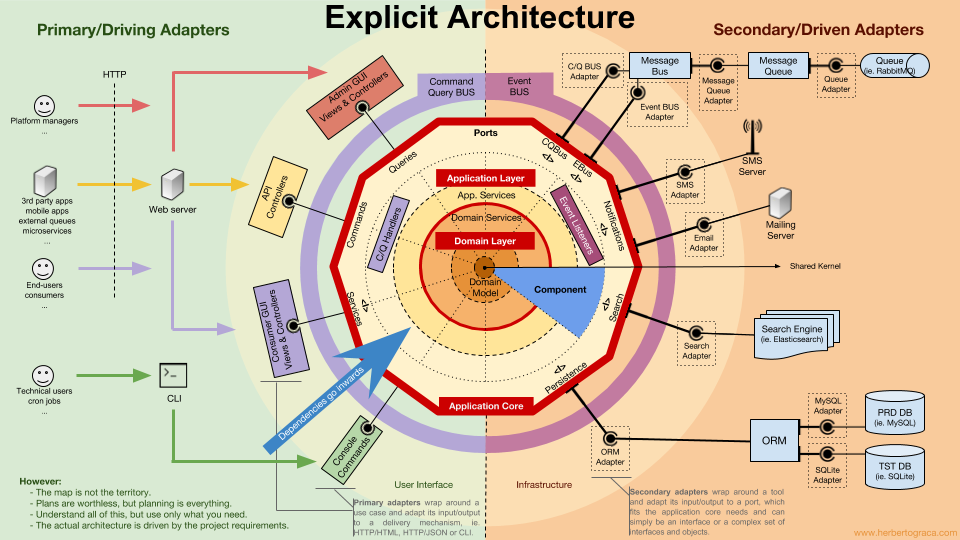
- domain layer:包括核心的领域服务和领域模型,大部分的业务逻辑都在这里实现,必须是完整可单测的;
- app layer:依赖domain layer的接口或抽象类,做流程的编排;
- infra layer:提供基础的第三方服务接入、持久化等;领域模型的持久化,又是另一个很头疼的问题了;
- user interface:本质上和infra是一致的;
在DDD架构中,能明显看出越外层的代码越稳定,越内层的代码演进越快(因为业务逻辑都在domain layer中),真正体现了领域“驱动”的核心思想。
DDD其实就是构建domain layer的一套方法论。
如何构建domain layer
这里开始就很抽象了。
战略层面:就是比较虚的概念,知道就行,跟实际的代码没关系:
- 通用语言(UL):很多时候语言的苍白无力让人无奈。。。其实就是需求分析时、统一思想和用语的过程;
- Domain:需求讨论、分解后,划分出不同的边界和范围;这里又有很多方法了:用例建模法、四色分析法、时间风暴法;
- 领域的划分是一个很玄学的过程,需要所谓的产品专家、领域专家深度参与;还有所谓的子域、支撑域等概念;
- 限界上下文(BC):由domain引出来的概念,每个domain内,有自己的domain model,这些model只有在这个域内才有意义;
- 比如电商体系中,用户这个概念,在权限管理领域、在交易领域、在支付领域,需要的属性、行为都不一样;很可能是每个领域都有自己的用户model;
- 怎么解这个问题?常见的方式:共享内核(一个巨大的model,包含所有需要的字段);依赖关系(通过继承的方式增加一些字段);防腐层(做一些适配和转换);
- BC是一个抽象的概念,并不会落到代码中的具体某个类;即所谓的“战略建模”概念;
- BC通常可以用做微服务的划分标准;
- 谁来做上下文之间的mapping?一般是app层;
战术层面:教你如何写代码
- Entity:有唯一标识的、有状态的、有行为的POJO
- Entity是从业务流程中抽象出来,并不是凭空而来的;比如订单(Order)可以作为一个Entity;它的行为一般是改变自己的状态,其实就是对业务规则的封装;
- 和Data Object有关系,但并不等同;
- 生命周期仅存在于内存中,设计时不需要考虑序列化和持久化;
- Value Object:不可变对象,无唯一标识的POJO
- 典型的比如各种DTO;
- 一般不带行为;
- Domain Primitive:一种特殊的Value Object,可以带一些无状态、无副作用的行为(封装业务规则);
- 并不是来自最初的DDD理论,而是后来者的创造;
- 典型的DP:用户的手机号,是用一个String来存,还是一个PhoneNumber类?手机号是有特定的校验逻辑的;
- DP是有一点反直觉的,还是手机号校验的例子,我是建一个PhoneNumber类,然后写个isValid方法?还是写个utils类,写个isValidPhoneNumber方法?从OO的角度看来,前者是更佳的;
- Aggregate:有些时候,多个实体、值对象放在一起,才能完整表示一个业务概念;比如订单中有主订单与子订单概念,主/子订单对应不同的Entity对象,但是他们必须是一起出现、一起操作。
- 跟UML的聚合关系有些像,是“部分”和“整体”的关系,“部分”不能脱离“整体”单独存在;
- 聚合也是为了封装业务逻辑;比如子订单价格变化时,主订单的价格也要变化;
- 同样也都是内存操作;但聚合是用于持久化的最小单元;由此引出所谓的聚合根的概念:比如订单ID;
- 在聚合边界之内,对象之间可以直接引用;在聚合边界之外,只能通过聚合根引用;
- 代码中往往并不会有所谓的“聚合类”,而是某个Entity类就可以充当聚合(也就是所谓的聚合根)
- Repository:负责聚合的持久化;
- 负责和具体的持久化实现解耦,所谓它的方法名一般不会用select/insert之类,而是会用find/add等;
- Domain Service:封装同一个领域内涉及多个model的操作或动作,避免暴露到上层;
- 识别领域服务,主要看它是否满足如下特点:服务执行的操作代表了一个领域概念,这个领域概念无法自然地隶属于一个实体或者值对象;被执行的操作涉及领域中的其他对象;操作是无状态的;
- 防腐层:一个比较特殊的概念,比如在接入各种第三方服务时,做一层适配;
概念就是这些,但想写出好的DDD风格的代码,还是挺难的。只能说,在各种代码屎山里多摸爬滚打,慢慢就能体会DDD可贵之处了。。。
疑点
所谓的CQRS,我感觉有点扯淡。之所以出现这种模式,根本原因在于领域模型并不适合用于查询。比如我只想查主订单的信息,但领域模型只提供getById这种方式,查出来的是一个聚合,强行带了很多我不需要的信息,效率会很差;于是提出了所谓的命令和查询分离模式。至于后来所谓的事件驱动、事件溯源,还引入了所谓的domain event,都是附带的了。
所以也有人认为,所有的查询都应该绕过domain层,直接和数据库打交道。
事件驱动本身就是常见的模式,跟DDD关系不大。正如系统设计中MQ是常见的解耦方式。
Repository的设计,是个大难题。由于Entity在设计时并不会考虑持久化,全是内存操作,那么我在真实写入DB时,到底有哪些数据是变化的,哪些没变?比如我的Aggregate Root(DB中对应表A)中有一个List<OtherEntity>(DB中对应表B),更新的时候表A肯定是要update的,但表B可能要update或insert,如何区分?我见过一些做法是在repo层做snapshot + diff,感觉有些重,也不自然。简单粗暴的方式,就是将表B中所有相关的记录删除+重新insert,不过效率不高。
云原生微吐槽
云原生(cloud native)这个词,不知不觉又火了。我这么喜欢凑技术热闹的人,当然得了解下啊。
如果望文生义的话,所谓的云原生,感觉就是后端架构天然适合云,不用再搞什么“上云”、“登月”之类的。如果说的具体一点,什么样的应用才是云原生的?那就要搬出CNCF的十二要素了。但如果去看其技术实现,似乎和现在没啥区别啊,不就是docker、mesh、微服务、k8s等等。
所以说,我感觉这就是一个营销词汇。但云计算领域怎么这么多营销词汇啊?这明明是一个强技术驱动的领域。一般只有同质化太严重的时候,才需要去包装各种概念来忽悠外行。
列举一些概念:
- 微服务:解决了单体应用的问题,不用关心其他人的模块,独立发布;
- 但带来了服务调用/服务治理/分布式事务/可观测性(logging/metric/trace)等问题;
- 如何拆分微服务?连带着DDD也又火了一把;
- mesh:进一步将通信层拆分出去,服务调用、流量管理等问题可以不用关心了,都走sidecar;
- 还有所谓的db mesh:访问db都不直连了,也是走sidecar;
- serverless:更模糊的一个词。理念就是用户不用再关心backend,直接提供业务实现就好;
- 无论底层是虚拟机or容器,用户都是不可见的;
- FaaS只是serverless的一个特例;现在大多数所谓的serverless实现还是基于容器的;
- BaaS:处于PaaS和SaaS之间,将后端诸如消息服务、认证服务、存储服务等能力以SDK和API的形式提供;
- 感觉就是另一种形式的中间件么,将能力下沉到平台层,而不是以jar包的形式集成在业务代码中;
- 想想每次升级中间件版本时的蛋疼;
- 典型的BaaS能力:cache和消息队列;
- CaaS:以容器为核心,介于IaaS和PaaS之间;但说到底不就是k8s么;
- DaaS:数据即服务,什么鬼啊?我看一些架构图里,把spark/flink之类算作DaaS,我一个搞数据平台出身的人很无语。。。
但纵观各种架构的演进过程,核心理念是不变的:让开发人员专注核心业务逻辑,快速演进,不要关心各种基础设施;将之前各种在应用层考虑的东西,落到框架层去解决。“与其进行顶层设计一揽子的解决方案,不如相信演进的力量。好的架构不是能大包大揽的一次性解决你所有的问题,而是给了你这种可能性:低成本的演进、试错,去达到一个理想的状态。”
一步步的,你只要关心自己的业务逻辑,越来越接近无状态应用。
甚至,业务逻辑都不用太关心了,各种中台SDK已经帮你包装好了,关心可变的部分就好。
会不会发展到最后,没有所谓的甲方/乙方,程序开发完全变成了表意的:上帝说“要有光”,于是有了光。这才是抽象的极致嘛。
这就是计算机科学:整合再整合,抽象再抽象,然后你的东西就过时了。。。
公司内部也经常出现这种:你做了个系统,我就再做个系统把你包掉。。。这是我的抽象层次更高呢?还是只换个皮呢?
所谓的创新大多都只是这种“整合”,真正能做出突破性贡献的人(Geoffrey Hilton这种)还是太少了。
Building Blocks
这个词还是从《Concurrency in Practice》中学来的,一个拗口的翻译是“构建块”,其实就是一些可复用的代码/做法/逻辑。
最近也看了不少业务系统,发现从技术的角度看,有些共性:
- 一个任务执行框架:简单点就是pipeline,复杂点就是DAG;
- 这里的DAG还不同于大数据语境中的DAG,就是个单机的执行框架;
- 一个分布式的调度框架:简单点就是分布式crontab,这种中间件也不少;
- 大多数业务系统不会去做复杂的分布式协调逻辑,虽然机器动辄几千台,但都是“平等”的/无状态的;
- 不同于大数据语境中复杂的依赖调度;
- 可能有缓存机制:比如LoadingCache+Redis的多级缓存;
- 可能有规则引擎:比如做实时的策略干预,做的复杂点还可以基于rete network;
- 流程编排引擎:所谓编排,就是用配置的方式“串流程”,配置代替硬编码;
- 编排这个词,有些被滥用了;
- 事件总线;
- 状态机;
- 复杂点的,还可能有自己的DSL;
这些东西吧,可能是middleware/framework/library,但感觉有些“共性”,我只能统一称之为building block。
往往各种building block拼拼凑凑,再叠加一些业务逻辑(DDD),就能搭出一个系统了。大多数业务类系统很难超出这个范畴。
更进一步,如果从能力的角度去解析这些系统:
- 产品能力:后台配置/管理/干预/分析;
- 系统能力:对外提供什么样的服务;请求流程是什么样的;
- 数据能力:数据pipeline是什么样的;消费哪些数据,提供哪些数据;
- 监控/容灾/运维等非业务能力;
把这些能力抽象出一个个小方块,再拼拼凑凑,就能画出一个看起来很复杂的架构图了。
大多数业务系统的架构也就是这么来的。
再进一步,打工人的PPT抽出一个个小方块,拼拼凑凑,就变成老板PPT。。。
Hooray for the layers of abstraction!
数据的价值
老生常谈了。data->information->knowledge->wisdom这条路,也不是新鲜概念了,但落地上还是很多困难。业务数据应用的最后一公里,到底有多长?如何解决数据 -> 应用的鸿沟?
有人说用了数据库、用了一些配置系统便是“数据驱动”了,我感觉我们不在同一个频道。。。
最近我发现公司内部有一个神奇的title:“数据解决方案架构师”,于是了解了下。这是一个跨领域的职位,“利用底层数据、工具与平台,通过数据分析和洞察找到业务上可运营可优化的机会点,以数据模型、标签、产品、SOP等方式提供端到端的数据解决方案,实现因我而带来的数据增量价值”。看起来,还是要贴着业务打,对业务流程的理解、对业务痛点的分析和拆解才是根本,数据/工具/平台只是手段而已。本质还是运营,但是更懂数据,能发现新的运营机会和更高效的运营手段、提升决策效率,典型的,比如growth hacker、比如SEO。
就像“互联网+”一样,数据往往提供的也是一个“+”的能力。
一般工作流程:业务理解->目标分解->设计方案->方案验证->上线评估->产品化沉淀。
业务效果 + 技术/产品沉淀,两手都要抓。大多数业务系统也都是这么个套路。说的极端点,没有沉淀出场景/解决方案/数据资产的系统,都不合格。
如何定义一个数据运营问题?
- 目标:可量化、可拆解,将目标分解为各个因子分别去提升;
- 策略:可描述、可执行;
- 效果:可量化、可观察,建立过程监控指标;
从某种角度来说,和BI有些像。BI到底是一个平台型的团队,还是垂直的团队?是否要为业务结果负责?话说回来,现在也没啥纯粹的BI团队了,大多数都是数据+算法的混合角色。
回到老本行,从平台开发的角度来说,如何帮助数据发挥价值?
- 数据的标准化:或者说,建设数据底盘。
- 真正有价值的一定是数据本身,而不是数据处理技术;
- 多样化的数据组织和探索形式:单一的schema设计往往是不能满足需求的;
- 比如上文中提到的图;
- 需要长期坚持并且不断根据业务形态调整,形成一套数据构架的方法论;
- 很多尝试性的工作,不确定性高;很苦逼,正如以前的人工特征工程;
- 数据的实时化:这是比较容易想到的;
- 稳定的数据资产服务;
- 合理的产品化流程:比如很多系统都有异动检测,但不应只是给出建议,更要有方便的手段让运营去验证,直接把AB流程、决策流程集成到产品中;
这些都是我能提供的技术/产品能力,再向下拆解才会是spark、flink等等。
基于此,无论是运营、解决方案架构师、还是BI,才有可能去做更多的数据探索和价值挖掘。
各种读后感
RALM: 实时Look-alike算法在微信看一看中的应用
特征工程对数据做了一些抽象,有相同特征的item就会被认为是“一样的”。抽象就不可避免会丢失一些信息,毕竟选择太多特征会破坏泛化性能。但对此也有一些争议:这篇文章认为,这些损失可能导致模型过热。文中提到“整个model对item后验数据十分依赖,导致推荐结果趋向于CTR表现好或者PV表现好的item”,我猜测是因为他们将一些统计性的指标也作为了特征,比如历史CTR。如果只使用item本身的“固有属性”,理论上似乎不应该有长尾?毕竟CTR才是命脉,再烂的内容,哪怕是标题党,只要有人点击都会推。换成用户感兴趣的冷门小众内容,也许CTR不会降,但要冒风险。所以文中用的措辞是“在保证CTR的前提下,加强长尾内容的分发”。不过将look-alike引入推荐系统还是一个很好的思路,感觉可以用来部分解决冷启动问题。“如果能完整的用受众用户的行为来计算item的特征,可以说是最完整的item历史特征的建模”。
- 先尝试性曝光,积累几百级别的种子用户;
- 用这些种子用户的feature,代替item的feature,来和其他用户做look-alike;本质还是找相似用户;
阿里定向广告最新突破:面向下一代的粗排排序系统COLD
所谓“我们重新思考了模型和算力的关系,从两者联合设计优化的视角出发”,言下之意:“现在算力已经足够强了,再加上一些优化,即使是粗排,也可以上复杂模型”。所以这篇文章里所谓的粗排,和精排已经差不多了。
对于一些历史方式、问题的总结还不错。
到底需要多少轮排序?没有定数。。。
谈谈推荐场景中召回模型的演化过程
推荐系统技术演进趋势:从召回到排序再到重排
很赞,总结的很全。
关于召回:“总体而言,召回环节的有监督模型化以及一切Embedding化,这是两个相辅相成的总体发展趋势”。
知识图谱是所谓的图模型召回的特例,优点是可解释性。
- 知识图谱:静态知识;图模型:用户行为 + 物品;
- 知识表示:显式表示(schema或SPO三元组)和隐式表示(embedding);
多业务融合场景下的推荐算法实践与思考
不够高大上,但确实是一线的实践
- 最重要的是理解业务,无论是洗数据、搭模型、还是简单的应用一些策略,这都是前提;
- 文中没有介绍什么NB的模型,而是基于业务理解,提出了很多策略上的优化,但确实有效;
- 推荐热点问题,文中没有在召回阶段解决,而是在重排阶段解决(热门的往后排),感觉这种方法也许有一些效果,但有限;
商业DMP数据管理平台的架构与实践
感觉有点做歪了,糅合了很多特征服务平台的事情。
圈人、洞察、再营销,都是基础操作。
从流量到增长,营销产品有何趋势
所谓的第一方DMP:“客户可以基于自有数据去分析洞察自有人群,也可以基于腾讯广告开放的数据能力,用自己的算法定制人群标签,并且通过腾讯广告DMP在腾讯的广告系统里进行定向投放”。
广告中oCPX到底是如何进行优化的?
facebook的oCPM,是以点击去竞价,但结算还是以CPM方式。
而淘宝的oCPC,就是以点击结算(当然还有GSP机制),而且优化目的在保证或提高广告主ROI的情况下,最大化平台的GMV。
简单点说,就是对转化概率高的优质流量,提高出价;对比较差的流量,降低出价;出价的逻辑受 预测点击率/真实点击率 的比值影响。
念念不忘,必有回响
写到最后了,还是要走波心的。
“Struggle to live”,直译的话是“挣扎求生”么?我更愿称为“用力活着”。当你浑浑噩噩的过了一周、一个月,甚至几个月,总有一天会突然醒悟,后悔为什么要这样浪费生命,被巨大的自责淹没。
无论是好是坏,至少别给自己留下后悔的机会。很多事情事后看来也许是个错误,但如果能回到当时的“上下文”,还是会做出同样的选择。
一年之前,我肯定难以想象自己现在做的事:推荐、图、算法、embedding,每天面对的都是巨大而无形的问题。以前我做事,心中是有一张大图的,我知道应该做成什么样子,跟现实的差距在哪里,不光自己笃定,还能向其他人输出,也从来不怕和别人battle。现在么,直白的说,没那么笃定了,但愿意去尝试和摸索。
说到底,哪有那么多确定的事呢?以前的笃定更多是因为事情简单。
我大概就是搞平台的人里,业务sence最好的;也是业务团队里,平台积累最深的。。。我以前说我是造铲子的,结果现在越来越接近直接挖坑的。。。技术的深度和广度很重要,但像NBA赛场一样,如何将天赋兑现,才是最重要的。
但不管怎样,数据的“主线”还在,无论碰到什么样的人和事,围绕主线的思考也从来没有停止。最怕的是被环境裹挟,丧失了独立思考的能力。好在,我还能写些文字。
题外话,在大公司里见识了太多的人,我已经学会如何区分真假大佬:真正的大佬NB在于他们的思考能力,甚至不是落地的能力。看清楚前因后果,看清楚可能的问题,先人一步。不管这种思考的深度是来自于天赋异禀,还是过往经验。做个比喻的话,有点福尔摩斯的哥哥迈克洛夫特的感觉。
这种能力对外的表现:话不需要多,但说的都是一针见血,而且再复杂的道理也能用通俗的语言解释出来,让所有人听懂。
为啥要学会这种区分呢?为了避免踩坑。见过一些人,语速很快,各种专业名词信手拈来,不管自己说的对不对,不管别人懂不懂,总是先争取发声的机会,给人一种貌似很NB的错觉。结果,要么就是你听不懂,晕晕乎乎;要么就是听懂了,但仔细一想,毫无逻辑。
唠唠叨叨扯了这么多,都是有感而发,但其实人类的悲欢并不相通,比如马老师在愁着如何花钱,而我在愁着如何挣钱。各自努力,各安天命吧。
