这算是老本行?终于暂时爬出了前端的大坑。。。
最近NewSQL的概念挺火的,似乎是TiDB又带了波节奏。看到新名词总是想去研究下,感觉就是Spanner+F1的开源版?就像hbase之于BigTable,hadoop之于GFS+MapReduce一样。
但Spanner好些年前(2012)就出了啊,为啥最近才火起来。不过话说回来,GFS的论文也是2003年出来的,但直到hadoop 0.2x(2009年之后)才算真正有了成熟可用的开源版本。
其实前些年火的词是“NoSQL”吧,后来却慢慢不怎么听到了。突然跳出一个NewSQL,还是有点意外的,果然是又续上了么。。。那我也来+1s吧。正好我对分布式系统中的各种概念还有点模糊,顺便研究&总结下。本文正如其名是个大杂烩,不是教程,想到哪写到哪。。。一家之言,仅供参考;如有错误,撒手不管。
毕竟这是很大的一个领域,很多人投入无数精力去研究,而我只能从自己接触比较多的系统入手去总结,管中窥豹而已。
感觉上,NewSQL就是NoSQL + 关系模型 + SQL + ACID么。
另外,严格来说,MapReduce、MPI、dubbo之类的也是分布式系统,甚至Folding@Home、SETI@Home之类的也算是分布式系统,不过这个离我们有点遥远,我们主要关注的还是各种分布式存储系统。
话说,我觉得NoSQL/NewSQL之类的更像是营销词汇,给人一种“RDBMS已死,NewSQL当立”的感觉。。。这些词跟bigdata一样,没有一个严格的外延,所以不要太纠结,更重要的是关注各个系统的原理/架构/适用场景。
单机存储 & NoSQL
其实这节的标题本来叫做“一切从RDBMS开始”,后来想想可能有点片面。
各种单机存储已经发展的很成熟了,很多思想无论是单机系统还是分布式系统,都是相通的。《圣经》说的好:“太阳底下无新事”,很多时候我们都只是在重复前人。
研究一个存储系统,不管它是单机的还是分布式的,我们要从哪些方面入手?
- 数据模型:Key-Value?关系型?
- 对外的API:其实很多时候API是由数据模型决定的
- 数据的存储方式:哪些数据在内存?哪些在磁盘?格式?
- 读路径/写路径:搞明白如何读/写一个数据,就会对系统有一个大概的认识
- 容灾、扩展、维护之类的:运维相关的特性,如何做到HA,如何做到可伸缩等等
- 最后才是一些细节:是否有啥优化措施,适用场景,一些特殊的算法&数据结构等等
关于数据模型,NoSQL时代有很多人总结过了,借用下:
- 文件型(包括对象存储)
- 关系型:比如mysql/oracle
- 文档型:比如mongo
- KV型:这个就多了,很多昙花一现的项目(原因就是KV系统实现上相对简单),目前比较坚挺的似乎就是redis。严格来说zk是不是也是KV?
- BigTable:比如hbase。话说我一直觉得从存储方式上来看,BigTable其实也是KV,只不过多了个scan操作。
- 其他异类:比如neo4j这种基于图模型的。
一般来说,单机存储的标杆就是RDBMS,我们实际中用的最多的就是mysql,它会作为衡量其他系统的一个“基准”。研究一个系统时,很多时候都会和mysql做对比,比如是否支持完整的事务特性,是否支持索引,是否有schema,join的方式(Sort-Merge Join/Hash Join),执行计划的优化(RBO/CBO/谓词下推)之类的。
关于事务,再多说几句(基于InnoDB),这可以说是RDBMS最重要的特性。事务的关键在于并发,所以很多概念跟基于线程的并发模型(比如java)是相通的。简单点我们可以认为一个事务就是一个临界区(critical section)。
java中同步的原则是啥?保持和顺序一致性模型的执行结果一致(JMM中的as-if-serial语义)。同样,事务间的同步,目的也是为了事务并发执行时,和事务串行执行时,结果是一致的,这就是Serializable隔离级别。但实际应用中,我们一般会牺牲一些隔离性的要求来换取性能提升,于是就有了Repeatable reads、Read committed等隔离级别。
隔离级别可能导致的问题:脏读/不可重复读/幻读/丢失更新,这都是老生常谈了,但很多资料没有说清丢失更新有两类。第一类丢失更新:两个事务同时修改一个数据项,但后一个事务中途失败回滚,导致前一个事务已提交的修改丢失;第二类丢失更新:两个事务同时读取和修改同一个数据项,后面的修改可能使得前面的修改失效。
在java中我们是如何同步线程(保护临界区)的?锁和CAS。同样,事务的同步机制也可以简单分为基于锁的和基于MVCC的(其实并发控制是很大的一个领域,有很多方法去实现同步,这两种只是最常用的)。
大部分单机数据库的事务都是基于锁的,可能有一些MVCC的特性(比如InnoDB的非锁定一致性读,真是拗口。。。)。而分布式数据库中MVCC基本是标配,当然也有结合锁一起用的。
不过数据库中的锁似乎比较特殊,可能需要遵循一种两阶段锁协议,简言之就是:1. 所有的读写操作都必须加锁;2. 所有获取锁的动作,必须发生在所有释放锁的动作之前,比如Lock A; Lock B; Unlock A; Unlock B;就是遵循这个协议的,而Lock A; Unlock A; Lock B; Unlock B;就是不遵循的。数学上可以证明,只有所有事务都遵循这个协议,无论系统如何调度,都可以实现串行化隔离级别。
事务还有个优点就是死锁检测,会自动检测到死锁并回滚代价最小(undo最少)的事务。而java中如果死锁,只能重启。
InnoDB中的锁还有个特殊的地方,虽然它是行锁,但它其实是锁在索引上的。在某些情况下它可能锁单行(比如根据主键更新),但更多的时候它会锁一个区间(锁整个B+树节点),这被称作间隙锁(Gap Locking、Next-Key Locking),被用于防止幻读问题。所以如果事务操作时没有涉及索引,是可能导致锁表的。
至于MVCC,也被叫做乐观锁。这只是一种思想,可以有不同的实现。比较常见应该是Timestamp-based Concurrency Control,使用时间戳作为版本号。
InnoDB中的MVCC只是读数据时不用加锁而已(基于undo实现),其实并不是完整的MVCC。
说到MVCC,还不得不提到一个“快照隔离级别”,Snapshot Isolation,简称SI。这并不是一个标准的隔离级别。因为SQL-92标准中定义的4种隔离级别都是针对使用锁的事务而言的,不太适用于使用MVCC的数据库。感觉上是比serializable稍微弱一些的隔离级别。还有更进一步的Serializable Snapshot Isolation,简称SSI,其实就是serializable。
题外话,不同数据库的隔离级别定义很混乱的。。。可能A数据库的RR在B数据库里就是serializable,还有的数据库直接管SI叫做serializable,别太纠结。
另外,虽然ACID的概念已深入人心。但其中的C在不同的地方却有不同的解释。在单机RDBMS中,“一致性”被解释为“在事务前后各种约束不被破坏”,比如一个int型的字段不能变为long的,各种触发器该触发的也必须被触发,unique的字段不能有重复值之类的。但是在分布式系统中,“一致性”就未必是这样了,很多情况下意味着“事务写入的数据是否立刻能被后续的事务读到”。关于CAP的很多争论其实也源于每个人对一致性的理解不同,原文“A service that is consistent operates fully or not at all”,感觉上更像是说对外部而言,一个操作要么发生了要么没发生,不存在中间状态。
说回NoSQL。对于NoSQL而言,一般有几个特点:
- schemaless:还记得一有新需求就要改表结构的黑暗时期么。。。
- 反范式:不过说实话即使很多OLTP也是反范式的,关键看需求
- 不支持完整的ACID
- 有限的索引支持:最重要的标准是“是否支持二级索引”。我以前一直奇怪为啥叫做二级索引,那有没有三级、四级索引?后来才知道,这是相对于RDBMS中的聚集索引(Clustered Index)而言的,Secondary Index翻译成“辅助索引”更好一点吧。。。不会那么容易误解。
NoSQL一般都要非常小心的选择使用场景,用起来其实不是很方便,每种NoSQL系统一般只能在自己的“最佳实践”里才能发挥作用。而且对系统的侵入性很大,因为缺少一个统一的API层(JDBC之类的)。在业务建模时也必须要从NoSQL角度出发去思考。我以前见过直接把RDBMS的思路套到hbase上,一建表就搞十几个列族那种。。。
题外话,有种说法是“hbase支持单行事务”,这其实指的是BigTable中单行数据的读写是原子的,hbase中并没有显式的事务概念。了解这个特性非常重要,因为很多基于BigTable的事务方案都是在这个特性上做文章。
如果用ACID的标准去衡量hbase:https://hbase.apache.org/acid-semantics.html
常见套路
总结下各种分布式系统中的常见套路。就像前面说的,很多思想和单机系统是相通的。
WAL & Checkpoint
WAL(Write Ahead Log)可以说是大多数分布式系统的基石。
WAL本质就是一种日志(log),也有叫做message/journal的。通俗点说,WAL就是操作记录,在写数据时,先写日志,再写实际的数据,当二者都成功后才通知客户端写操作成功。这其实不是什么新鲜概念,在所谓的Journaling file system中早就有类似的做法了。mysql中的binlog,InnoDB中的redo log,严格来说也都属于WAL。
在单机系统中,WAL一般用于系统崩溃后的恢复。比如InnoDB中写数据后只更新内存中的buffer pool,如果在脏页刷新之前系统崩溃,没有刷新到磁盘的数据就丢失了。这时就可以使用redo log来恢复数据了。hbase中也有类似的用法。
当然WAL也有其他用法,比如InnoDB中的redo跟事务的原子性也有关(commit record)。
但在分布式的环境下,WAL有一个更重要的作用:维护整个系统的一致性。它不仅仅是紧急时刻用来恢复数据的一个“备用手段”了,而是系统的核心。原理也很简单:同样的原始数据,经过相同的操作序列后,会得到同样的结果。而操作序列就是用一连串的WAL来表示的(必须是有序的)。换言之,在同一份数据上回放同样的日志。最常见的场景就是维护主从节点间的数据一致,比如mysql replication。各种分布式一致性协议(paxos/zab/raft),也都是在WAL有效的前提下才成立的。
hdfs中的editlog就一种WAL,通过共享操作日志,使ActiveNN和StandyNN保持状态一致,实现HA;hbase中直接就叫做WAL了,但只是用于数据恢复,跟一致性没啥关系,因为hbase将数据一致性“委托”给hdfs了;redis中的replication,是通过所谓的“命令广播”去实现的,虽然不是基于日志,但思想是类似的;redis的AOF持久化也是同样的道理,持久化的其实是一系列操作日志。
spark中的failover也有类似的思想:某个节点挂掉后,它不会尝试恢复那个节点持有的数据,而是从原始数据重新transform一次。
WAL还有一个额外的好处:写日志一般是顺序写的,很少有随机读写。在使用机械磁盘的情况下,这个特性非常重要。但也要看具体的实现,比如InnoDB中的redo文件就不一定是顺序写的,因为除了要在文件尾部追加,还可能要更新文件头部的一些元数据。
理论上来说,WAL可以无限增长。但实际中这显然是不可能的,磁盘空间是一个原因,更重要的是如果不限制WAL的大小,系统崩溃时回放WAL可能就要很久,很长时间无法对外服务,那就没什么意义了。所以WAL一般会结合所谓的Checkpoint机制来控制日志的大小。首先要为每条日志生成一个唯一的id,InnoDB中称作LSN(Log Sequence Number),hdfs中称作txid,hbase中称作Sequenece Number。触发checkpoint后,某个id之前的所有修改会全部持久化,小于这个id的日志就可以丢弃了。
触发checkpoint一般有几种情况:
- 定时触发(InnoDB中的MasterThread,HDFS StandbyNN中的StandbyCheckpointer)
- 日志数量达到某个阈值:比如超过x条日志未合并
- 日志大小达到某个阈值:比如日志量达到xx MB
WAL也是有局限性的,no silver bullet,可能引入一些其他的问题:
- 多了一次写操作,效率上肯定会有影响。InnoDB使用一个redo log buffer来优化性能,写日志时先写buffer,然后异步刷新磁盘。但这又会带来可靠性的问题。
- WAL保证数据的可靠性,谁来保证WAL的可靠性?理论上来说WAL应该是写入后立即持久化的,但很多时候我们会为了性能做一些妥协。要是每写一次数据就调用一次flush+fsync,虽然这是最保险的办法,但这系统也基本上可以定义为“不可用”了。。。很多时候我们会把选择权交给用户,比如InnoDB可以让用户配置何时刷新redo log buffer。如果想要最大的安全性,就要配置为每次事务commit都刷新并fsync。
- 共享存储:保证可靠性的另一个方案是使用共享存储,将日志的可靠性交给其他人去保证。比如hdfs中的journal node、hbase中基于hdfs实现的WAL,或者直接用kafka。这会带来一个额外的好处就是日志与系统解耦,即使Master所在的机器挂掉也不会影响日志,对于维护数据一致性有很大好处。
- 临界状态。一个很简单的问题:一个写操作,写日志成功了,但真正写数据前机器挂掉了。那对客户端而言,这个写是成功了还是失败了?要不要重试?这其实不是WAL的问题,就算写数据成功了,但向客户端返回数据的时候也可能因为网络原因导致客户端没有收到。(我就搞一个防火墙规则过滤你返回成功信息的数据包,你能咋地。。。)只不过使用WAL时写操作不是原子的,这个问题可能更严重。这个时候其实客户端处于一种“两可”的状态,看系统的设计思路。不过一般选择都是重试,这就要求使用方保证操作是幂等的。(题外话,关于幂等:日志的回放不一定是幂等的,看设计,但幂等会有很多好处。InnoDB中的redo因为记录的是数据页的变化所以是幂等的,但binlog就不是幂等)。
为啥在各种分布式系统的架构中kafka这么重要?很大程度上是因为它提供了一种可靠、有序的日志分发手段,这是它和传统mq最大的不同。想用传统的mq做日志分发也可以,但会有各种限制,比如顺序问题。kafka就像润滑剂一样,我以前就说过,“设计系统碰到困难时,试着扔个kafka进去”。说的更专业些,它提供了数据集成(Data integration)的能力。就算不用kafka,自己开发中间件,最后肯定也会演化成类似的东西。
关于日志,有一篇经典的文章:The Log: What every software engineer should know about real-time data’s unifying abstraction,但这篇文章里所讨论的log是更广义的,整个data pipeline都是基于log的,或者叫做“log-centric architecture”。
参考资料:
https://www.zhihu.com/question/30272728/answer/56373661
replication
为了保证数据的可靠性一般都要使用数据冗余机制。在单机的情况下,我们可以使用RAID;在分布式的场景下,一般有两种方式:多副本(replica)和纠删码。
多副本很好理解,也是最常见的一种冗余方式,就是一个数据copy多份,典型的比如hdfs的3副本,对读可以做很多优化(优先读某个副本/本地读),问题在于也需要3倍的磁盘空间。纠删码比较少见,但这个东西很有意思,大意就是将一组数据分成n个数据块+m个校验块分别存储,只要丢失的数据块小于m个,那数据总能完整恢复。优点在于节省空间,但是数据恢复时会比较耗cpu和带宽。
似乎各种开源项目里很少见到纠删码,大多是基于副本的。估计只有各个云存储厂商才会使用吧,毕竟可以节省成本。。。接下来的讨论也都是关于副本的。
说到副本,就不得不提到一致性。这方面的资料已经很多了,最终一致性的概念也已经深入人心,但大多数资料没说明白:在分布式系统中,“一致性”一般分两种。
- 副本间的一致性,保证各个副本的数据是同步的
- 整个系统的一致性,或者说是事务的一致性,不能有中间状态,比如经典的转账例子
我们常说的ACID中的一致性指的其实是2,paxos/raft之类的分布式一致性协议针对的其实是1。很多人讨论一致性时会把两种情况混淆起来,就会很难理解。
顺便提一句两阶段提交(2PC),它和paxos/raft的目的是不一样的。2PC可以适用于上面说的两种场景,理论上用来保证副本一致性也可以,但一般没这么用的,更多的还是用于事务的一致性。
接下来讨论的都是针对副本的一致性。
强一致性/弱一致性的概念就不赘述了。强一致性还有两种:顺序一致性和线性一致性。最终一致性是弱一致性的一种特例,最终一致性又有读写一致性、会话一致性、单调读、单调写等变种(其实这种说法并不准确)。不要太纠结概念。很多概念看着吓人,说白了其实很简单。
一致性的问题其实很常见,只是很多我们没有意识到而已。比如多核CPU间要保持cache的一致性(缓存嗅探)、同一个CPU中不同级别cache也要保持一致性。最终一致性也不是新鲜东西,DNS、CDN、各种缓存,反正各种带有TTL的系统,基本都是最终一致性。
保证副本一致性的方法被称作Consistency Protocols,学术界已经研究了很多年了。大体上可以分为两类:
- Primary-back:也称作passive replication/primary-based protocols。大概意思是副本间有主从关系,写数据时只写主副本,主副本负责应用修改到其他副本(可能同步也可能异步)。
- State-machine:也称作active replication,所有的写操作暂存到某个独立的数据源,副本之间没有主从关系,分别去应用修改。
借用一个图: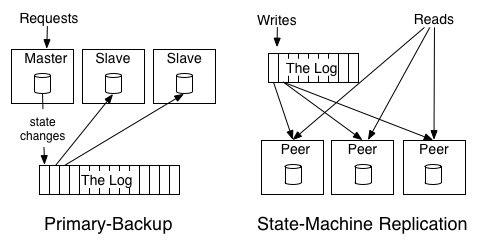
注意上图虽然是用log在副本间执行写操作的,但其实也可以选择其他方式。
从实际情况来看,大多数系统都是primary-back,毕竟这种实现相对简单。这会引入几个问题:1. 如何确定主副本?2. 如何发现主副本异常?3. 主副本异常如何切换?这其实就是一个系统的HA(High Availability)方案,没啥标准答案,只能说八仙过海各显神通。
从副本修改的时机来看,replication又可以分为同步和异步的。
所谓同步,就是要更新所有副本之后,这个写操作才算成功,换句话说是强一致性的(所谓的Write-all-read-one,又称作ROWA)。一个例子就是hdfs pipeline,一个packet必须要写完所有副本并ack后才继续下一个。这可以算是一种“多写”的策略。可能是客户端去更新所有副本(State-machine),也可能是主副本去更新其他所有从副本(primary-back)。
异步基本都是基于WAL的最终一致性,比如上图中的log队列。在不使用共享存储的情况下,其实挺鸡肋的,这个东西在一致性要求不强的场景下作为读写分离还可以,但你要是把它当作HA方案,只能祝你好运了。。。比如mysql replication,就算主挂了,你敢直接让从服务器作为主么。。。
副本的分布策略也是个大问题。如果所有副本都在同一台机器上,哪还有啥意义?关键还是看你对数据可靠性的要求有多高。hdfs中没有跨机房的概念,分布策略一般是一个在本地,一个同机架,一个跨机架。其他系统也会有类似的策略,比如所谓的“两地三中心”。
题外话,为啥大多数系统是3副本?网上有人从各种角度论证3副本的优越性。。。我倒觉得这可能只是个先入为主的观念而已。如果是用了paxos/raft倒是还说得通,毕竟奇数个节点有利于表决。
另一个问题:副本的“粒度”。可能是机器级别的replication,比如mysql和redis;也可能是数据块级别的replication,比如hdfs中的block。有人称这两种情况为同构系统和异构系统。在大规模的分布式系统中,一般都是后者,数据恢复、新增副本都有很大优势。
相比手工实现replication机制,使用各种一致性协议更为靠谱,其中最著名的就是paxos了。Chubby的作者说这个世界上只有一种一致性算法,那就是paxos,其它的算法都是残次品。关于paxos的资料已经非常多了,不再赘述。这货以其难懂(很多时候我们都是自以为懂了)和难以实现而出名。。。还有各种变种。但在过去很长时间内它是唯一选择。整个算法的流程初看很简单,似乎按这个思路写个实现也很容易,但你很难证明它是“完备”的,在各种异常情况下都是正确的。
Zookeeper借鉴了paxos的思想,使用了一种称为Zab的协议。原文:“The main conceptual difference between Zab and Paxos is that it is primarily designed for primary-backup systems, like Zookeeper, rather than for state machine replication.”。
在新出现的各种系统中(比如etcd),Raft是更主流的选择。它的功能和paxos大体等价,但更易于理解和实现。这里有一个非常赞的可视化教程:http://thesecretlivesofdata.com/raft/
这些一致性算法都是基于Quorum机制实现的,通俗点说就是所有节点必须是已知的,一项决议要想通过就必须得到“大多数”(一般是过半)节点的同意。可以看出2PC也是类似的,只不过需要所有节点的同意。但Quorum只是一种“特例”,有些时候参与的节点是无法事先得知的,比如后面会说的区块链。这种场景下要达成一致,只能用其他办法。
另外,很多资料中会说paxos/raft是“强一致性”,个人觉得这是一种误解。paxos算法只需要过半节点的同意,一项决议就能通过。如果你每次都去读master,当然是强一致性,但这就失去分布式的意义了,副本纯粹作为backup;如果允许去读其他副本,那就有可能读到旧的数据,是最终一致性。相关分析见这里。
说到副本,不得不提Amazon Dynamo的NWR模型,这个很有意思。它将选择权交给了用户,把各种麻烦也交给了用户。。。N代表副本的数量,W代表一次写操作必须更新的副本数,R代表一次读操作必须读到的副本数。如果N=3/W=3/R=1,就是hdfs的模型了。如果W<N,可能出现写冲突,必须要用户手动解决。
参考资料:
拜占庭将军问题:如何在多个节点故障的情况下达成一致,很好玩,还会引申出所谓的拜占庭错误
https://www.zhihu.com/question/23167269
https://www.zhihu.com/question/19787937
https://en.wikipedia.org/wiki/Consistency_model
http://web.eecs.umich.edu/~farnam/498/handout5b.pdf :详细介绍了各种consistency protocol
Using Paxos to Build a Scalable, Consistent, and Highly Available Datastore
https://segmentfault.com/a/1190000004474543
http://coolshell.cn/articles/10910.html :注意这里有些观点是错误的
http://hedengcheng.com/?p=970 :登博的blog
http://hedengcheng.com/?p=892
分布式事务与一致性算法Paxos & raft & zab
解读NoSQL技术代表之作Dynamo
sharding
所谓sharding其实就是数据分片。现在分库分表中间件都应该是各个公司的标配了吧。。。这其实也不是什么新鲜概念,只不过是分布式环境下的分区表而已,分区策略也还是那些:基于range、基于hash、基于list。mq中也有类似的partition、routing key等概念。
最常用的还是基于hash的,比如redis中的slot(这和一致性hash中的虚节点很像)。但分布式系统中更常使用的是一致性hash,解决re-hash的问题,这也算是标配了。相关概念不再赘述。
sharding的方法很多,可能是手动的也可能是系统自动的。我曾见过直接在代码里计算分片,然后手动操作对应的库的,甚至读写分离也是通过代码手动做的;也有写在DAO层的;也有写在JDBC层的;还有用单独的query server去实现mysql jdbc driver的。反正是各显神通,不能一概而论。
不过呢,对用户友好的方式还是尽量让操作透明。用户应该纯粹把系统当作一个黑盒,不要去考虑内部的实现。
sharding的目的是为了扩展,最理想的情况下,系统应该能够线性扩展:整个系统的吞吐量和机器数成正比。加机器真是最简单的“优化”手段了。。。
但分片不是万能的,对于一些热点数据,还是可能集中在特定的几个分片(数据倾斜)。这个时候就要想其他办法,比如缓存,或者更换分片策略。
话说常有人纠结什么是水平切分,什么是垂直切分,我倒觉得不用太在意这些概念。关键还是看系统是怎么设计的,有些系统里根本没有那么多模式。
题外话:分片数为啥一般是2^n?同样的问题,为啥HashMap的Entry大小也是2^n?因为这样取模运算可以等价为按位与:a % (2^n) = a & (2^n - 1),提高运算效率。所以扩容时一般也是按2倍扩容。
参考资料:
http://blog.codinglabs.org/articles/consistent-hashing.html
http://www.infoq.com/cn/articles/exploration-of-distributed-mysql-cluster-scheme
超时
只要是通过网络的调用,结果就可能有三种:成功、失败、超时,这个超时,就和数据库里的null一样,非常头痛。很多系统设计时会忘记处理超时的情况,然后在线上就会出现各种诡异的问题。。。比如HA方案中最常见的脑裂。。。
超时的问题在于,你不知道一个节点是真的挂了,还是只是网络出了问题。如果你认为它挂了,开始迁移它上面的数据,万一它等下又缓过来了呢,就可能会造成数据不一致的问题。
租约机制(lease)可以部分解决这个问题。其实这和OAuth中的token类似,是一个有时效性的“凭据”,最初是用于分布式cache。每个节点必须定时向Master更新自己的lease,如果lease失效,就停止对外服务。Master也可以确定节点彻底失联后才开始迁移数据。lease的可靠性在于它只依赖单次网络通信。租约也可以用来实现其他功能,比如hdfs用租约来实现单一写+多读(soft limit/hard limit机制),有点类似读写锁。
租约的问题在于它的有效期是基于时间的,所以各个节点之间时间误差不能太大。否则可能出现某个节点认为租约有效而其他节点认为无效的情况。
超时还可能导致一种“临界状态”:就是上面说过的,写操作在服务端完成了,但返回成功信息时超时了,客户端没有收到,这咋整?换言之需要客户端去处理超时的逻辑。这种时候没有啥固定的处理办法。。。还是要看系统怎么设计。可能是通过其他手段去验证是否成功(比如客户端重新读一次),也可能是直接重试。
缓冲池
缓冲(buffer)的目的就是为了协调cpu和磁盘的速度差距,在各种系统中也非常常见,甚至都算不上一种“机制”,而是自然而然的选择,比如InnoDB的buffer pool、MapReduce的io.sort.mb、hbase的Memstore。
其实这也不是啥新鲜概念,操作系统本身就大量使用了缓冲区,比如socket的发送/接收缓冲区。
buffer在不同系统中的作用可能完全不一样。以InnoDB为例,buffer pool可以说是整个系统的核心,负责对各种页的管理。这和操作系统的分页管理有点像了,会有各种page-in/page-out等逻辑,一般要搭配LRU/LIRS算法;和netty中的内存池也有点像(chunk)。写数据时只会写内存,然后异步刷新脏页。如果不使用buffer而每次都直接写磁盘,性能会被磁盘拖累。但也可能导致一个问题,就是服务启动后需要预热。有些sql第一次执行很慢,第二次执行就会很快,就是这个原因。
hbase的Memstore,更是兼有随机写转化顺序写的功能(LSM Tree)。
至于MapReduce的io.sort.mb,就纯粹是排序用的一个临时空间而已。
另外,有人会纠结buffer和cache的区别。直观上来看,buffer是系统必要的一部分,buffer中的数据丢失会导致各种问题;而cache只是一种优化手段,有没有都无所谓,大不了回源重新读取。更详细的讨论见这里,不过对这种事情的理解呢,千人千面。
题外话,“池化”也是非常常见的一个优化手段,线程池、连接池、内存池、对象池,都是一个道理,减少执行某个操作的开销。
Master-Slave
为啥大多数分布式系统都是主从结构的?个人感觉,这是为了分散各种“状态”。
以前我就说过,状态是万恶之源。系统设计的关键就是明确有哪些状态、状态如何管理,各个节点之间共享的状态越少越好(share nothing),这对整个系统的可用性、扩展性都有巨大的好处。极端一点可以将所有状态都放到共享存储中(比如Zookeeper),然后把节点做成无状态的。
Master-Slave的本质就是一个“分工”,不同的节点分成不同的角色,维护不同的状态。比如hdfs,元数据由NameNode维护,block report由DataNode维护,DataNode不需要也不应该得知元数据相关的状态。这可能带来额外的问题:
- 单点故障:Master不能是单点,需要使用各种HA方案
- Master瓶颈:每次读写都要经过Master,它的qps限制了整个系统的上限,可以适当使用客户端缓存解决
- 容量限制:Master是否能存下所有的状态?如果不能,还要进一步拆分,比如hdfs federation
如果是去中心化的系统,所有的节点是平等的,那么每个节点都必须得知其他所有节点的状态(一般是通过心跳),这可能导致巨大的网络开销,限制了系统的扩展性(加一台机器都可能导致带宽需求成倍增长)。而且很多时候并不需要全局的状态。
去中心化的一个例子就是redis集群。所有的redis节点都是平等的,需要向其他节点push自己的状态,但redis做了一些优化,每次心跳不会向所有节点push,而是随机挑选5个,再加上“久未联系”的节点(上次心跳至今超过某个阈值)。但这不是治本办法。我不知道这套机制在实际的生产环境中运行的如何,但感觉肯定有坑。。。
除了Master-Slave,也有所谓的Master-Master结构,不过感觉很少见。这种系统的问题就是如何解决写冲突,一般都只能让用户手动解决,就像git/svn一样。
其实最关键的原因是:Master-Slave结构工程上实现起来简单。。。
不过呢,从一个强迫症的角度来说,明显去中心化的网络才是“更美”的,比如区块链,比如P2P,比如DHT,比如那啥主义。。。
HA
HA是对分布式系统的基本要求,有时也称作fault tolerance。
关键的几个问题(其实上面已经说过了):
- 如何在节点间同步状态(Active和Standby)
- 如何发现节点挂掉
- 如何切换节点
没什么标准方法,不同系统的实现可能完全不一样。
状态的同步,参考上面replication章节。
发现节点挂掉,一般通过心跳+超时机制+lease。有了zookeeper后,也可以简单的利用zk的ephemeral node,但这种情况下zk的session超时时间就要谨慎设置,否则很容易踩坑。hdfs的NameNode HA比较奇葩,通过定时的rpc调用去发现节点挂掉(zkfc)。关于hadoop HA机制的更多细节见我以前的文章。此外也有用keepalived+VIP的,这种方案在nginx中似乎很常见。
至于节点的切换,服务端一般是通过心跳,客户端可能是通过类似配置中心(比如zk的通知机制)或者直接重试(比如hdfs的客户端)。
其他
一些零散的想法:
- 即使是非常小概率的异常,集群规模一大,也可以称作是必现的,所以设计时不能忽略任何可能的异常情况
- 仔细考虑服务降级,要考虑好哪些是强依赖,哪些是弱依赖,要认为所有外部依赖都是不可靠的,包括网络。我见过一些应用,redis挂了,就不可用了。。。有时候防御式编程也是不得已的。这方面Netflix的猴子非常出名。
- 没有银弹,必须要trade-off,不存在one fits all的系统
- 不管什么架构,首先出问题的一般都是IO,无论是网络IO还是磁盘IO
- 不管什么架构,不管你怎么设计,似乎总能找出一些极端情况,击溃“不丢数据”的传说。hadoop的HA设计的那么美好,实际跑起来不也是一堆坑。。。当年我可是没少半夜起来处理故障,又想起了被hadoop支配的恐惧。。。
- 太理论的东西了解下就行,不要过于执念
- 跟无锁编程类似,事务中也尽量用CopyOnWrite、MVCC等方法优化性能
- 其他常用手段:列式存储+数据压缩
- 其他常用数据结构:Bloomfilter、LSM Tree(hbase/LevelDB)、Timing Wheel
分布式事务
这一直是个老大难问题。因为没有什么标准的解法,很多时候要看自己的需求。
之前有人总结过涉及分布式事务的各种场景,借用下:
- 分库导致的:或者说,同一个系统中的事务,比如跨多个mysql库,比如Spanner中跨多个paxos group
- 跨多数据库:比如跨mysql和oracle
- 跨数据库和其他组件:跨各种中间件的调用,典型的是数据库+mq(事务消息)
- 微服务架构下,跨多个服务的调用:实际中这种情况更常见,尤其是现在“X-as-a-Service”理念盛行的情况下
对每种场景,都有完全不一样的做法。甚至在不同的场景下,“事务”的含义都不太一样。
其实RDBMS中早有考虑过分布式事务(XA事务,这个名字很奇怪),两阶段提交(2PC)也是源自XA的。简单点说就是所有参与节点先做本地事务(prepare),然后决定是commit还是回滚。这可以说是分布式事务的一个参考标准,大多数资料里都会讲2PC,但实践中用的貌似不是很多。2PC的问题在于协调者是单点,而不能很好的处理超时和各种failover,可能阻塞,各个角色之间需要的交互次数很多,效率相对较差。虽然有后续的3PC改进了部分问题,但也是不治本。
但2PC更重要的是一种“思路”,实现的时候可以想办法去优化,比如Spanner中就大量使用了2PC。
注意不要把2PC和之前的副本一致性算法(paxos/raft之类)相混淆,他们要解决的问题不同,paxos一般用于保证同一数据块多个副本之间的一致,而2PC用于保证在不同数据块上的操作的原子性。在实践中我们谈到“事务”时,大多数时候也是更关注原子性。
其实2PC不只用于分布式环境下,很多场景下都可以。比如mysql中利用XA事务实现存储引擎和binlog的一致,称作内部XA事务。总之只要需要原子性的地方,都可以考虑2PC。
说到分布式事务,就不得不提到ebay的BASE架构(虽然我觉得这个BASE是为了对应ACID强行凑出来的词。。。),中文版见这里。虽然这个文章很古老了,但仍有借鉴意义。它的核心价值在于提出了利用消息实现的最终一致性,一般被称作消息事务,也有点像WAL。具体的操作逻辑原文讲的很清楚,不再赘述。
ebay是使用本地事务来保证“业务操作” + “发送消息”的原子性的,在实际中,一般是直接用mq,但如何保证原子性就要自己考虑了。
BASE架构的问题在于:1. 如果消费者处理消息失败怎么办?可以引入适当的重试机制;2. 但是如果想回滚之前已经提交的本地事务,就必须要人为介入了;3. 消息的处理如果不是幂等的,消费时需要严格的exactly-once语义(大多数mq都只能保证at-least-once),这限制了很多场景;4. 消息的顺序如何处理,有些场景要求消息必须是有序的。
总之就是:能解决问题,但是否适用还是要看自己的需求。
其实仔细想想,分布式事务的关键在哪里?如果说事务的本质就是并发,解决并发问题一般有两个手段:锁和CAS,那2PC就是基于锁的实现,而锁是基于悲观策略的。这是一个兜底的方案,它保证结果一定是正确的,但一般都比较低效。更常见的做法是:所有节点直接做本地事务,认为发生冲突的概率很小,一个事务很可能成功(乐观策略),如果有任意本地事务提交失败,则触发全局的回滚。这一般被称作事务补偿,也是一种最终一致性实现(可能被用户看到中间状态)。补偿策略的关键:1. 如何确定一个本地事务是否成功?2. 如何回滚?这两个问题如果是基于DB的还好说,但广义的分布式事务未必是跟数据库相关的。
这方面比较出名的是TCC模式,这个模式从何而来已不可考,似乎是从阿里传开来的(我能吐槽下中间件的命名方式么:TCC/TXC/XTS/GTS傻傻分不清楚)。TCC模式可以认为是2PC的威力加强版,try阶段直接完成本地事务提交(减少阻塞),后续看情况决定调用confirm还是cancel。这种方式相当于强制程序员在每个事务之前事先写好回滚逻辑(还要保证confirm和cancel是幂等的),然后交给系统去执行。如果每次调用都按这个模式来,毫无疑问会增加很多工作量,不同业务逻辑的回滚代码是不可复用的。
更智能的方式是系统自动决定如何回滚。要做到这点,调用链路上的所有中间件都要进行改造,不管是数据库、MQ、还是RPC。每个服务也都要事先确定好自己的回滚逻辑:订单服务失败如何回滚、支付服务失败如何回滚,细化到每个接口的程度。换句话说,每个系统都要事先确定自己的补偿逻辑。
鄙厂的TCC实现中,只打通了DB层,是通过在各个业务库新增一张log表来实现的,记录本地事务和对应的分布式事务的执行情况。回滚时可以调用手动指定的sql,也可以指定某个方法。在整个调用链路中(dubbo),加了事务注解的方法都会自动加入到分布式事务中来,还挺好用的。
其他厂应该也有类似的中间件,原理都差不多。
本地事务失败时,也可以加上一定的重试机制。毕竟全局回滚的代价还是挺大的。
但TCC和2PC都有一个问题没解决:需要一个全局的协调者。这似乎是没法避免的,只能尽量提高协调者的可用性。万一协调者挂了就悲剧了。
有一种做法是本地事务失败时,失败的那个参与者发个消息,然后其他参与者看情况决定是否回滚。这样就不用协调者去触发回滚逻辑了,在一定程度上可以解决协调者的问题。但这要求所有系统增加处理失败消息的逻辑,相当于把处理逻辑分散了。
至于MVCC,一般只能用在上述四种场景中的第一种,即只能用来在一个独立的系统中实现分布式事务。毕竟跨多个异构系统的话,版本号如何确定?强行用MVCC的话反而麻烦。
最后,我们还有一个终极大招:人工处理。。。
题外话:我本来以为TCC是2PC的另一种表述,try=prepare,confirm=commit,cancel=rollback,其他资料中也确实有人持这种观点,并不认为TCC是一种补偿机制。不过这样还有啥意义呢。。。根本原因在于TCC不是一个严格定义的名词,不要太纠结。
参考资料:
http://weibo.com/ttarticle/p/show?id=2309614012527083212086
http://weibo.com/ttarticle/p/show?id=2309403965965003062676
https://www.zhihu.com/question/21612832
http://blog.jobbole.com/108569/
https://zhuanlan.zhihu.com/p/25933039
http://jm.taobao.org/2016/11/24/2016-1111-GTS/
https://gist.github.com/weidagang/1b001d0e55c4eff15ad34cc469fafb84 :主要看注释
Megastore & Spanner
这两个东西放在一起说说,只是总结一些个人感想。google的论文缺少了很多细节,很多地方只能靠脑补。
其实GFS->BigTable->Megastore->Spanner是有迹可循的:BigTable基于GFS实现了强一致性、索引、semi-relational等特性,Megastore则在BigTable上实现了更友好的API、paxos复制、多行事务等,最后的Spanner则是集大成者。
Megastore: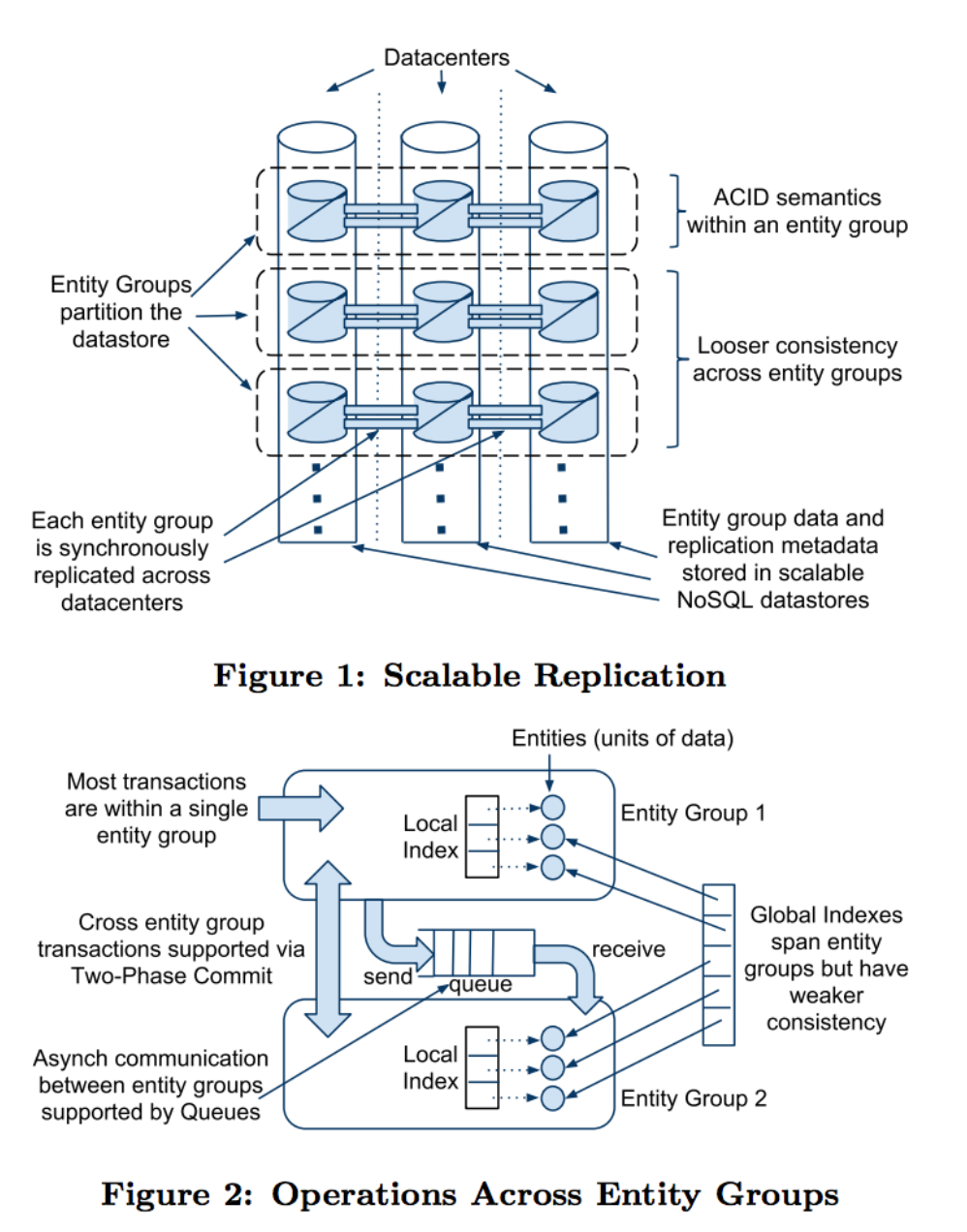
熟悉BigTable/hbase的话,就会觉得Megastore很精妙:
- Megastore的大部分功能都只是“客户端库”,最后会映射为底层的BigTable操作。自身几乎没增加什么额外的状态,复制服务器、协调者、witness等角色也只是辅助性的。
- 利用BigTable单行操作的原子性,保证同一个entity group中多行事务的强一致性。基本原理就是将redo日志保存在单独一行内,写redo成功就算事务提交。那如果整个系统只有一个entity,是不是就可以说BigTable也支持多行事务了?似乎没毛病。。。但这样估计日志量要爆炸。。。entity group模型从某种意义上来说也是为了日志的sharding。
- 由于使用了redo,所以副本的数据未必是最新的,读数据时可能需要“回放”(catch up)
- 跨group只能实现基于消息的最终一致性或基于2PC的强一致性
- 基于paxos的数据同步机制,感觉是第一次出现在这么大规模系统中。相比传统的Master-Slave同步,paxos的好处就是可以故障自动切换。而且加了很多优化,local read之类的。
- 不过我有一点疑问:BigTable不是将数据副本委托给底层的GFS?这个paxos的“副本”到底是啥。也可能是hbase让我先入为主。有资料说是用于在不同集群之间同步redo的,如果是跨多个BigTable集群部署,确实可能。
- 由于BigTable中的数据自带版本号,所以Megastore天生就支持MVCC的并发控制。个人猜测:每个客户端写数据时,redolog先写本地buffer,提交前检查版本号和事务开始时是否相同,不同则回滚。相同则使用paxos协议提交日志。
- “使用paxos协议提交日志”,这说起来简单,但实现起来肯定巨复杂。如果竞争一个分布式锁然后提交,是不是也是同样效果?分布式锁一般也都是基于paxos实现的。
- 读和写都可以从任意副本开始(原文: Any node can initiate reads and writes),这个很方便。读数据时,协调者用于决定读哪个副本。但每次写都必须同步到所有副本(强一致性),难道不会慢么。
- Megastore支持local/global两种索引,但也是没有跳出BigTable的限制,还是在rowkey上做文章。我很好奇是怎么在数据和索引之间保持一致的,local索引还还说,只是同一个entity group内的一些索引行;global索引则是单独的一个索引表。如何实现跨表更新的原子性,论文里似乎也没说,估计也是2PC吧。之前常见的二级索引方案,大多都是离线更新索引的。
个人感觉,Megastore最大的意义在于揭示了BigTable是还一个非常底层的抽象,在它上面还可以有各种各样的应用层,比如Phoenix之类,正如hive之于MapReduce。
Spanner: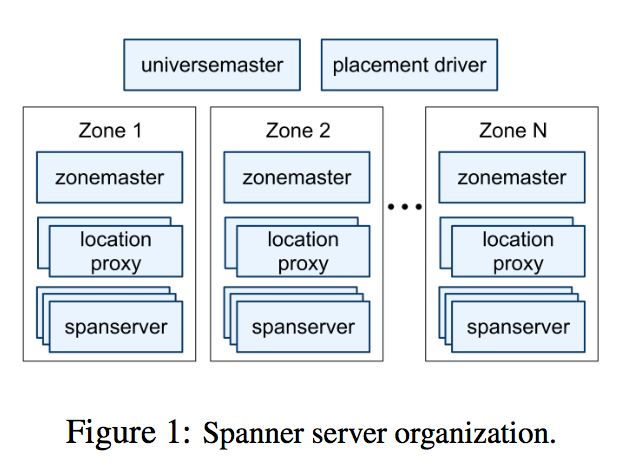
Spanner刚出来的时候,大家都惊为天人,毕竟全球规模的扩展性+关系模型+强ACID前所未见,很多人觉得这已经突破CAP了(google还有专门的一篇论文说这个,作者就是提出CAP理论的那哥们,中文版)。Spanner中的很多机制都继承自Megastore,比如paxos复制、关系模型等,但在此基础上做了很多创新。GPS+原子钟实现的TrueTime API,脑洞真是大。。。关键人家还有能力把脑洞变成现实。。。
- 原文:At the highest level of abstraction, it is a database that shards data across many sets of Paxos state machines in datacenters spread all over the world.
- 每个zone可以认为就是一个datacenter,部署了一套BigTable集群。在同一个datacenter里,zone也可以用来做数据隔离。
- Spanner的数据模型类似BigTable,但又不太一样。似乎是越过了BigTable层,直接操作数据,少了一层API调用。tablet的概念和BigTable类似,但每个tablet中的行未必是连续的。directory的概念和Megastore中的entity基本一致,多个directory可以同属于一个tablet。每个tablet的所有副本组成一个paxos group。
- 论文中说底层的存储模型是
(Key: string, timestamp: int64) -> string,还强调和BigTable不同,我咋没看出来。。。 - 如何将数据对应到tablet,元数据的结构和管理,如何回收不需要的版本,这些论文里都没说。。。只能靠猜
- 和Megastore一样,写也是强一致性
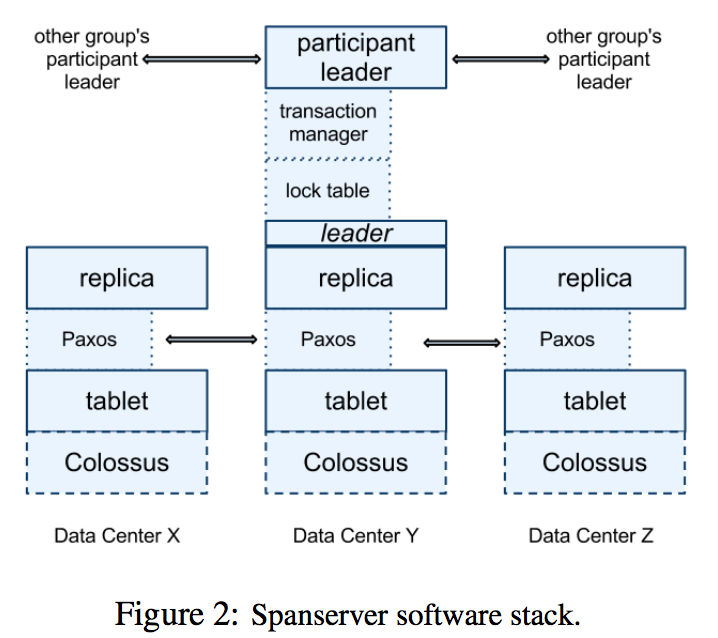
- Spanner中的事务是为了所谓的long-lived tranction设计,所以它没有采用类似Megastore中的乐观机制(多个事务如果同时提交到一个paxos group,只有一个事务能提交成功,另一个事务会重试,即使这两个事务实际上没有冲突),而是用了传统的两阶段锁(所以按SQL标准而言隔离级别是可序列化?),每个paxos group中都会有一个lock table(用于记录每一行是否被锁定)和transaction manager(简称TM,用于2PC)
- 论文中详细讲了跨group时的2PC过程,却没有讲单个group中的事务是如何处理的,估计是当作2PC的一种特例处理
- 论文中一再提到“外部一致性(external consistency)”,我却找不到这个词的准确定义。个人感觉就是一个写提交之后,修改对后续所有的读可见。
(这里的“之后”、“后续”都是很模糊的词,更严格的表述应该用TrueTime) - paxos无处不在,不只数据会被复制,锁的状态、TM的状态都会被复制
- 只有读写事务才需要锁,只读事务(估计要API中显式声明)/快照读是不需要锁的,但也是可能阻塞的
- 只读事务,其实就是系统自动分配时间戳的一个快照读
- Spanner认为过度使用事务造成的性能下降的恶果,应该由应用的开发者承担,而不能因为性能问题,就不提供事务支持。
- 多个paxos group参与的2PC,这工程难度,想想就蛋疼。。。
- TrueTime API主要是一个
TT.now()调用:返回一个时间区间[earliest, latest],保证触发这个调用的“真实时间”必定在这个区间之内- 使用时间戳来做concurrent control不是新鲜概念,但大多数都没有处理好时间的误差。Spanner是第一个能在全球范围内做到这点的(原文:Spanner is the first system to provide such guarantees at global scale.)
- 时间戳会用作数据的版本号。原文:The timestamps reflect serialization order
- Spanner保证同一个group内,事务的时间戳都是单调递增的,即使是切换了leader。个人感觉,这就像一个全局的事务id生成器,但是效率和精度都好很多
- 写数据(Read-Write Transaction):注意使用两阶段锁时,读也要加锁。先写客户端buffer,所有写完成之后,发起2PC。这里就很有意思了:coordinator leader会为整个写操作选择一个时间戳s作为事务id(也可以认为是数据的版本),这个时间戳必须大于所有participant leader提交prepare record的时间,还必须大于
TT.now().latest,然后coordinator leader会写一条commit record,但不会立即通知participant也commit
(2PC的第二阶段),而是要等到TT.after(s)为true,换句话说必须保证s已经是“过去时”,然后才会通知所有participant也commit。这时数据才会对外可见。 - 为啥写操作要这样设计?猜测是为了保证外部一致性,防止因时间误差导致一个读操作读取到不该读的值。
- 读数据(Read-Only Transaction)时:首先必须给读事务分配一个时间戳s。最简单的就是取
TT.now().latest,但如果读到了一些比较落后的副本,可能必须等副本的数据追上来(细节论文没说)。Spanner对此做了一些优化,如果读的是单个group,并且这个group内没有未提交的事务,可以优化为s=最后一个已提交事务的时间戳。 - 看过读写流程后,发现一个问题:如果分配给一个写操作的时间戳是s,但这个写操作真实提交的时刻是在s之后,关键这个“之后”是多久?除了2倍的TrueTime误差,paxos提交也要一些时间的。如果假设这个写操作在s+10时刻才提交成功,那我在s+1时刻的一个读操作,是否能读到s的数据?我纠结了挺长时间,一度怀疑Spanner是unrepeatable-read。。。后来又仔细看了下论文,发现有解释,在这种情况下Spanner会认为副本not sufficiently up-to-date,会阻塞读操作直到事务结束的。。。但又是没有细节。总之,外部一致性不容打破。
- “未来读”(指定了一个将来的时间戳的快照读)应该是没什么意义的。。。
- 之所以想到“未来读”,是因为论文中还提到一种事务“Schema-Change Transaction”,可以做在线DDL,要指定一个未来的时间戳t,不知道这个t的作用是啥,随意指定的还是有啥算法?
- 猜测Schema-Change Transaction也只是更新元数据,不会动实际的数据
- Spanner的论文中多次吐槽了Megastore(原文:its relatively poor write throughput)。。。
- 感觉Spanner中的读和Megastore的current read好像没啥差别。。。除了TrueTime实现的更精准的版本号
- 不知道Spanner支持二级索引不。。。论文里一句都没提,不过Megastore都支持了。
Spanner的事务处理似乎是借鉴了Percolator的,后者使用一个oracle来生成全局递增的时间戳。Spanner的开源实现中,也有类似的做法。关于Percolator事务机制可以参考这个文章,原理和Megastore类似,也是利用BigTable单行的原子性。但redo不是写在专门的某行(Megastore中的entity行),而是在写入的行里挑选(不知是不是随机)一个作为primary,其他行保留一个指向primary的类似指针的东西。这种模式如果写入频繁估计会大量冲突的,估计也会被Spanner吐槽“poor write throughput”。。。
话说大家都喜欢拿BigTable的单行事务做文章。。。
最近关于Spanner的新闻就是Cloud Spanner了。Cloud Spanner只支持SQL查询,写操作是自定义的API,那估计原版的Spanner也是这样。
另外google又发了一篇Spanner的论文(sigmod2017):Spanner: Becoming a SQL System。从名字来看似乎是一些user interface上的改进?
题外话:以前的google总是发表一篇论文证明自己的NB,然后退到一边静静观察;最近却越来越喜欢直接参与开源项目,热衷于制订行业标准了。比如Kubernetes、Apache Beam、TensorFlow。
参考资料:
https://research.google.com/pubs/pub36971.html
https://research.google.com/archive/spanner.html
http://blog.csdn.net/techq/article/details/7039208
http://blog.nosqlfan.com/html/1195.html
Google Spanner原理 - 全球级的分布式数据库
https://www.zhihu.com/question/61245513
http://www.infoq.com/cn/news/2017/02/Google-Cloud-Spanner-hit-CAP
TiDB
其实Spanner的开源模仿者很多,谁能做好了就是下一个hadoop。模仿的最大难题就是如何实现TrueTime,但很多应用达不到google的规模,所以可以使用一些替代手段。
目前提到比较多的就是CockroachDB和TiDB了。关于TiDB,PingCAP老大这篇文章讲的很好,逻辑非常清晰。里面一句话非常赞同:“Infrastructure领域闭源的东西是没有任何生存机会的”。
话说前段时间朋友圈被PingCAP成功融资的消息刷屏了。。。
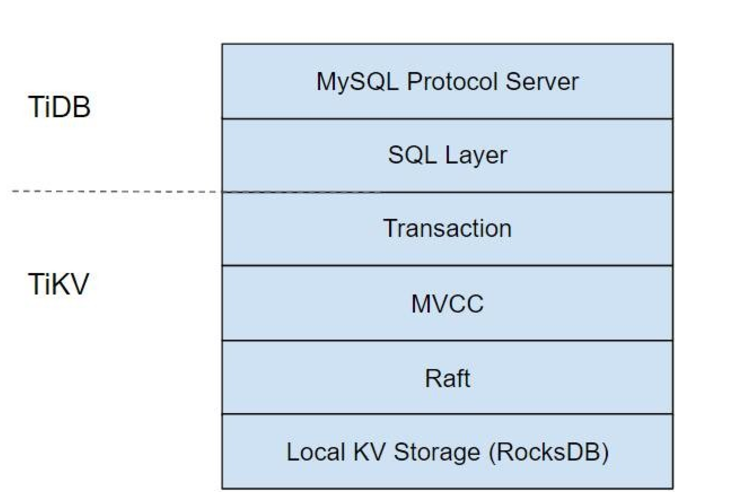
- 分层架构十分清晰,选择直接支持mysql driver真是太明智了
- TiDB底层存储基于RocksDB,是facebook基于LevelDB修改而得
- 一行的数据都是存在一个KV Pair中,不会被切分,这点和BigTable很不一样。这会限制一些超“宽”的表的使用。
- Raft实现来自etcd,将原来的go实现用Rust重写,但TiDB的其他部分都是go。。。选择Rust似乎是因为GC。
- TiDB事务模型也是基于Percolator,依赖于一个单点的服务TSO生成单调递增的事务id。但做了一些修改,不会直接在原始行中记录锁信息,而是一个单独的meta行。
- TiDB补充了Spanner中非常多的细节,比如元数据、索引。基本思路是还存在底层的KV中,但设计不同的prefix存不同的数据。
- 基于KV实现的SQL引擎已经有很多研究了。最关键的是如何生成分布式的执行计划,还有如何处理join,如何做谓词下推之类的。具体的我就不是很懂了。
参考资料:
PingCAP官网有很多第一手的资料
知乎专栏:TiDB 的后花园
区块链
为啥会想到区块链(Blockchain)呢,因为这也是一个所谓的“分布式共识”问题,这其实也是分布式领域的一个经典问题了。核心在于如何保证某个变更在网络中是一致的,是被大家都承认的,同时这个信息是被确定的,不可推翻的。
一些名词:
- 交易(Transaction):一次操作,导致状态的一次改变,如添加一条记录;
- 区块(Block):记录一段时间内发生的交易和状态结果,是对当前状态的一次共识;
- 链(Chain):由一个个区块按照发生顺序串联而成,是整个状态变化的日志记录。
通俗点说,区块链就像是一个全局唯一的链表,网络中的每个节点都想向链表里添加数据,但最终只有一个节点能成功。这就和paxos/raft关注的问题有点像了。不过paxos关注的是“尽快”达成共识,每个acceptor都会优先支持提案号更大的proposal。而区块链的做法似乎又有不同。
paxos/raft达成共识都是基于所谓的Quorum机制,即一次提议必须经过大多数节点的认可才算通过。而区块链中的节点更多,网络情况会更复杂,也很可能有网络分区,不能再用类似的办法了。每个节点在提出proposal(姑且称之为proposal,声称自己算出了某个区块,即挖矿)后,会向其他节点广播,不管他们是否确认,自己都会基于这个区块继续计算。其他节点可能会认可这个proposal,也基于此继续计算;也可能他们本地的链更长(每个节点只认最长的链),而忽略这个proposal。所以区块链中的“共识”是有可能被撤销的。。。也就是所谓的“分叉”。而paxos中所有节点一旦达成了共识,结果就不会改变。
这其实是一种很讨厌的“不确定”的状态,一个节点不知道自己算出的区块到底会不会被整个系统认可。以比特币为例,A转了一笔钱给B,但B要过一段时间才能使用这笔钱(需要至少经过6个区块的确认,大概一个小时,因为被撤销的概率很小了)。但似乎从数学上可以证明,整个系统最终会达成一个一致的状态。
为了减少这种分叉的情况,一个方法就是提高proposal的门槛。如果一个系统里每个人都能随意提议,要达成共识就很难。具体到比特币而言,就是Proof of Work机制:每一个节点如果想提出proposal,必须进行大量的数学计算(挖矿),算力越高提议的可能性就越大。所谓的计算其实和暴力破解没啥区别:先生成一个随机数,然后计算h = hash(上一个块的hash + 这段时间的交易记录 + 随机数),如果h小于某个特定值(系统会动态调整这个值以保证大概每10分钟挖出一个区块,所以系统的总算力越大,挖矿就越难)就认为计算成功,这个区块是合法的,可以向其他节点广播了。否则就只能换一个随机数然后重试。挖矿成功后会得到系统奖励的比特币,也可以得到区块中所有交易的手续费。所以说,比特币的价值是通过计算力背书,而不是像传统的纸币是政府信用背书。
但我还是有些想不通:
- 如果整个系统不发生交易,是不是就不会有新区块了?换言之,一个区块中可以不包含任意交易记录么?
- 如果发生了网络隔离,比如30%的节点失联10个小时(之前不是就有过挖断海底光缆的情况),这30%的节点会在自己的“小圈子”里计算出很长的一个链。但网络隔离恢复后,这个链上所有新增的区块都要被抛弃?所有交易也都作废?那别人转给我的钱到底啥时候可用。。。这是“51%攻击”的一种特例么?
去中心化的系统,相比Master-Slave,实现/分析一般都更复杂,会觉得有很多“不确定性”,但也更有意思。设计的好的话,这种系统一般都会更健壮。
题外话:其实我只是个一边看着显卡涨价,一边看着游戏玩家们哭天抢地的围观群众。。。
参考资料:
比特币白皮书
区块链技术指南
https://yq.aliyun.com/articles/65264
https://www.zhihu.com/question/27687960
https://www.zhihu.com/question/37290469
其他
杂七杂八的其他资料:
Raft论文译文
http://kabike.iteye.com/blog/2182036
Time, Clocks, and the Ordering of Events in a Distributed System
https://docs.oracle.com/cd/E23824_01/html/821-1455/a00intro-21293.html
http://www.cnblogs.com/mmjx/archive/2011/12/19/2290540.html
http://duanple.blog.163.com/blog/static/709717672011330101333271/
话说,之前的评论系统挂了。。。换成了disqus,以前的评论都丢了,虽然也没多少。。。
我的react后台项目停滞挺久了,真是抱歉。。。最近确实各种事情比较头痛。。。以后尽量多分一些精力吧。
