2017如期而至,虽然早有准备,但总是难免有点点伤感。不为了什么,只是单纯感慨时光匆匆而已。花相似,人不同。果然我是老了么。。。
至少我觉得自己还走在大致正确的方向上,略感欣慰。
不过也说不准,说不定明年就回老家种地去了呢。。。
本文将继续贯彻落实XX届X中X会上确立的形散神也散的重要精神,有一些吐槽,也有一些最近研究react/redux的心得,还有各种乱七八糟的东西。
CPS变换
最开始听说cps变换是从某个知乎帖子,当时只是不明觉历。最近在研究redux,接触了一些函数式编程相关的思想,机缘巧合下又遇到这个问题,于是研究下。
简单点说,CPS就是一种编程风格。我们调用一个函数后,一般要拿到函数的返回值后再去做各种处理,而cps则将后续的处理逻辑(封装成一个函数)直接传给被调用的函数。有一些“控制反转(IoC)”的味道在里面。
这么说太抽象,还是看例子:
|
|
上面就是一个非常简单的计算阶乘的函数了,但这种递归非常容易出问题。还记得递归的经典反面教材斐波那契数列么?如果用递归法去求斐波那契数列,非常容易StackOverflow。所以各种算法教材中常常强调“迭代优于递归”,我在刷leetcode时用到递归也总是非常小心,因为心里没底。。。
如果将上面的函数改写成cps形式,就会变成下面这样:
|
|
计算结果和普通的递归是一样的,但却难懂了很多。这么写的好处在哪里?细心观察就知道这段程序理论上不需要压栈/出栈,在函数的最后一行,直接开始下一次递归就可以了,不需要保存上一次递归的状态,这种递归被称作尾递归(尾调用的一种特殊情况)。
形式上只要是最后一个return语句返回的是一个完整函数,它就是尾递归。
理论上来说,这段程序即使没有终止条件,无限递归下去,也不会StackOverflow。
编译器通常可以对尾递归做很多优化,甚至可以将尾递归消除。这种优化在ES中被称作proper tail calls,是ES6中的标准,但目前尚没有主流的浏览器实现这种优化,见这里。
cps虽然形式更复杂了,但表达能力也更强,可以基于这个去封装特定用途函数,因为callback的逻辑是由外部控制的。抽象点说,就是用一个高阶函数去生成普通函数。
cps在函数式编程中似乎是非常重要的一个东西。因为很多函数式语言都非常符号化,非常学院派,不提供if/for/while之类的流程控制语句,而这些都可以用cps去实现。所以对函数式语言来说,尾递归优化是标配。
王垠的40行代码据说就是能自动对已有的函数做cps变换?不懂。。。而且似乎还涉及到很多数学上的东西,我一介学渣只能仰望。。。
研究cps的过程中,突然又想到闭包。这也是我一直很模糊的一个概念,每次看定义/示例都觉得已经懂了,但过一段时间之后又觉得自己什么都没懂。。。
通俗点说就是每个函数可以有自己的私有变量?或者叫做自己的状态,外界无法修改。感觉上和OOP中的成员变量很像么。毕竟js中没有private/public之类的变量作用域。但却可以用闭包模拟。
但这种东西呢,感觉上更像是种hack,似乎还容易造成内存泄漏,少用为妙。
一个还可以的闭包教程:http://www.cnblogs.com/frankfang/archive/2011/08/03/2125663.html
一些参考资料:
知乎上的一些讨论帖:1、2、3
其他一些讨论帖:1、2
轮子哥的tinymoe语言,感觉拿来当编译原理的入门不错
尾递归与Continuation
async/await
这是个很好玩的东西。但要搞明白这个玩意还要从js的异步机制说起。
对于刚接触js语言的人来说,印象最深刻的是什么?至少对我而言,是各种callback。这也算是js的一大特色(是不是也可以说是函数式语言的特色)。
如果在java中,我要实现一个“异步取数据并消费”的逻辑,我会怎么做?很大概率是写一个生产者-消费者模型,搞一个BlockingQueue,“多线程”在java中是一个很自然的概念(HotSpotVM会把java线程映射到系统线程)。或者搞个事件驱动,比如经典的EventBus。如果强行用回调实现反而麻烦,必须要定义一个接口,回调还要以inner anonymous class的形式传过来,这种代码写起来/看起来都很别扭。当初用到zookeeper的API,它提供了同步/异步两种风格的接口,异步版本用起来就很是蛋疼。。。
如果是在js中,就没得选择了,只能使用callback。因为js的执行是单线程的(当然这是特指浏览器和node,不排除以后某种js的解释器可能用多线程执行,不过难度太大了)。对于单线程的js而言,要想实现并发的效果,就只能依赖于各种异步操作的callback,具体可以去google:Event Loop。好在js的callback用起来很方便(跟java比),因为js是弱类型而且function是一等公民,有了箭头函数之后就更简洁了。
话说,之前不是总有人纠结基于event loop的并发和基于线程/锁的并发哪个效率高么,还搞各种吞吐率测试。应该说最传统的提高并发量的手段就是多线程,突然出现一个单进程单线程的node确实很容易被人质疑。并发模型其实还有很多种的,各有优劣。还有Concurrent vs Parallel的区别,并发也是个大坑啊。。。
再话说,js是单线程的,但并不意味着浏览器是单线程,只是说浏览器中有单独一个线程负责执行js而已。很常见的一个现象:浏览器加载外部资源(图片、css、js)时,是可以并发的;包括我们在js中如果同时发送多个ajax,其实也是并发的。并发的请求数是由浏览器限制的,chrome中有一个参数可以改这个值,具体是那个参数忘了。。。
这又引申出一个问题,如果多个ajax并发,哪个回调会先被执行?个人猜测是跟请求返回的顺序一致的,哪个请求先返回就先放到事件队列,回调先被执行,跟请求发起的顺序无关。
js语言的设计思路导致它只能用callback解决并发的问题。本来也没啥事,但程序复杂了之后,代码一多,大家渐渐发现回调太多了,就是所谓的callback hell。callback本身就是反直觉的,很容易造成程序的结构复杂,难以维护。更蛋疼的是各种回调的嵌套。一个很常见的场景:后端提供了CRUD的接口,我要先ajax请求某个接口,按一定条件查询,得到某条记录的id,再拿这个id去查询另一个接口得到最终的结果,类似下面这样:
|
|
这样的代码,写起来很蛋疼,支离破碎,而且可能有更多层的嵌套,维护起来十分麻烦。看着满屏幕的function,很容易晕。。。于是有聪明人提出了Promise模式。这个东西其实也挺古老了,我最开始听说promise是在jquery中,还有deferred对象。在ES6中,promise正式成为一项标准,不过和jquery的promise用法不太一样。如果用promise去重写上面那段代码,大概是这样:
|
|
由于then()可以链式调用,整个流程清晰了很多,不需要嵌套了,但回调函数还是无法避免。promise只是把传统的嵌套回调变成了链式调用,或者叫fluent style。
关于promise的更多资料可以参考这个和这个,其实还有很多高级的用法。
为了解决promise的的问题,于是有更聪明的人提出了async/await,这被称作js中异步调用的终极解决方案。async/await特性本来想随ES7一起发布的,但没赶上截止日。。。目前好像是stage-3的状态,已经很接近发布了。最终发布的ES7只包含很少的新特性,async/await估计要随ES8一起发布了,不过现在可以通过babel使用。
话说,ES的这种发布模式我觉得挺好的,看看java9都难产多久了。。。
如果用async/await来写上面那段代码,大概是这样:
|
|
可以看出,这个代码的逻辑是非常流畅、非常线性的,完全摒弃了回调的存在,写起来非常舒服,读起来也容易懂,“像写同步调用一样写异步调用”。只是有一些需要注意的地方:
- async必须和await搭配使用,await只能用在async函数内部。async的语义是“这个函数内部有异步操作”。
- await后面的变量,必须是一个promise对象。await的语义是“后面的语句是一个异步操作,先不要继续向下执行,等后面这个promise状态变为resolved后再继续”。
- 如果异步操作出错,只能通过try-catch来捕捉错误并处理,不像promise对象一样可以用catch()方法。对于js程序员来说这可能有点啰嗦,不过对于java程序员来说倒是很亲切。
async/await还是挺好用的,要不怎么号称是“终极解决方案”。不过我比较怀疑,前端的同学们这么能折腾,会不会哪天又搞出一个“超・终极解决方案”。。。
其实,async/await只是一个语法糖,它背后的原理是ES6的另一个新特性:生成器。babel支持async/await的原理,其实也是转换为生成器的写法,见这个插件。
生成器
生成器(Generators)也是个很好玩的东西,是随ES6发布的新特性,一些基本的使用可以参考InfoQ的教程。
个人感觉,生成器的本质,其实就是ES6对协程特性的实现,而且从python中借鉴了很多理念。但js/python的协程,貌似和lua/erlang/go之类的协程还不太一样,本来不是为了并发设计的,而是为了方便的迭代,所以才叫做“生成器”,一个例子:
|
|
所以,将“生成器”当作“协程”来用,是一种无心插柳么。。。不过他们的逻辑本来就很相似,就算语言原生提供了协程(比如lua),其实也可以包装下当作“生成器”来用。
那么,啥是协程?几乎所有的语言中,都会有“函数”,或者叫做过程/例程/方法/子程序(function/procedure/routine/method/sub-program),反正就是这么个东西。执行一个函数时,都要保存上下文(压栈),函数执行完毕(碰到return语句或执行到最后)再恢复上下文(出栈)。在这个过程中,函数只有一个入口点和一个出口点,一个函数必须从头开始执行,而且开始后,你必须等待它执行完毕。换句话说,一旦开始执行,这个函数会一直掌握着代码的执行权。
而协程(co-routine),跟函数非常类似,区别在于它可以有多个入口和出口。在协程执行的过程中,你可以在某行代码处打断协程,跑去干别的事,然后再回来继续执行。一般通过yield关键字实现,比如js/python。但也有不是用关键字,而是用特定方法的,比如lua的coroutine.yield()。yield关键字的语义就是“将代码的执行权交给其他人”。从某种意义上上来说,yield关键字有点像goto语句,都会很“强硬”的直接改变代码执行流程。
这个“打断-恢复”就是协程最关键的特性,也是它能被用于处理并发问题的关键。这个过程也是需要切换上下文的,协程从yield的地方继续执行时,必须恢复当初中断时的状态,但未必是像函数一样用栈去实现了,跟具体语言或者协程库的实现有关。相对进程/线程的切换而言,协程的上下文切换代价一般比较低,需要的内存会少很多。
更神奇的是,协程的状态可以被外部“干涉”,可以和外部交换数据,一个例子:
|
|
协程的另一个关键特性就是协程之间的切换都是在同一个线程中发生的。还记得《操作系统原理》中的内核线程和用户线程么?内核线程的调度完全由系统内核负责,用户端只负责执行就可以;用户线程则需要单独提供调度器,系统内核完全不知道线程的存在。协程就有那么点用户线程的意思,用户要自己负责协程之间的调度。
对于js而言,因为它是单线程的,所以协程对它而言“永不并发”。同一时刻只可能有一个协程的代码在运行,最多是代码的执行权在不同协程间切换而已。
协程的调度算法似乎也是个坑,没啥统一的规范。。。通俗点说,我在协程中yield交出执行权后,这个执行权交给谁?是我直接决定交给另外的某个协程(symmetric coroutines,对称协程,调度是平级的)?还是交给我的上层,让上层去决定接下来如何执行(asymmetric coroutines,非对称协程)?这就是调度算法要决定的事情。
就js/python而言,他们的协程都是非对称的,yield时执行权都会返回给上层。
由于协程的调度是在用户端实现的,所以完全可以根据需要写一个自己的调度器,一个例子。
扯了一大堆协程的东西,好像有点偏离主题。。。本来是在说js的生成器的。。。
生成器/协程除了用在迭代中,还可以用来简化js的异步编程,换句话说,解决callback hell。其实思路也很简单:我要执行异步请求的时候(比如ajax),就yield一下,把执行权交出去,让js引擎先去执行其他的代码;异步请求结束后,再把执行权要回来,从yield的地方继续执行。所以最关键的问题是:执行权的交换是如何做到的?有点类似调度器了。目前看来一般有2种方式:
Thunk函数
Thunk函数是一个很古老的概念了,从函数式编程中发展而来的,似乎最初是为了惰性求值,参考这个。但现在Thunk函数的概念已经很宽泛了,似乎很多辅助性的函数都可以被称作Thunk函数(thunk函数一般都是通过代码自动生成的)。
个人理解,对js的生成器而言,Thunk函数就是“接受一个callback为参数,做一些操作,并在最后执行callback”的函数。例如:
|
|
是不是和之前的cps变换中Continuation的概念很像?其实很多概念都是相通的。
Thunk函数能做什么?由于Thunk函数的最后会调用callback,如果yield(给出执行权)时返回一个Thunk函数,就可以利用callback在Thunk执行完毕后把执行权再“要回来”。一个例子:
|
|
如上,我们定义好生成器了,如何执行呢?所以还需要一个程序去调度它,或者叫做“驱动程序”:
|
|
打开console即可看到效果。说实话这段代码挺难懂的。。。估计过一段时间我自己都不懂了。。。关键是要理解“代码执行权”的交换过程。但一旦看懂就会觉得很神奇,“卧槽这也可以”的感觉。
有了这个run函数,我们就可以“像写同步调用一样写异步调用了”。看下那个robot的生成器,完全屏蔽了异步调用的复杂性,也不用再跟回调打交道了。当然这个thunk+run的机制,可以做的更复杂、更通用一些,比如加上错误处理之类的。其实有很多人已经做好了类似的库,用的最多的就是thunkify+co,不过这两个库是用于node的,不知道能不能用在浏览器端。
仔细观察下,这个function* + yield的语法就跟async/await很像了。
Promise对象
用生成器处理异步请求的另一个方法就是Promise对象了。其实核心原理还是一样的,就是“异步操作结束后代码执行权的交换”。只不过Thunk函数是用执行完毕之后的callback实现的,而Promise是用自带then()方法,毕竟如果then()方法被触发了,就说明异步请求已经结束了。而且Promise是ES自带的对象,会更通用一点。
如果用Promise对象改写上面的那个机器人的例子,大概是这样:
|
|
基本原理和Thunk是一样的,不再赘述。
这种情况下,function* + yield就和async + await完全等价了。所以说async和await只是生成器+promise的一个语法糖,好处在于更规范,毕竟是从语法层面上去支持。生成器+promise总是有点奇技淫巧的感觉。。。
其他
生成器其实还有很多高级的用法,比如yield*。
很遗憾的一个地方是生成器不能配合箭头函数使用,见这里。箭头函数和普通函数还是有很多不同的,哪里用箭头函数,哪里用普通函数,似乎还有很多争议。
箭头函数的一大好处就是自动绑定this,否则就只能手动绑定或使用const that=this之类的hack。。。
但async/await却可以配合箭头函数使用,真是奇怪。。。
参考资料
http://coolshell.cn/articles/10975.html
https://www.zhihu.com/question/20511233
https://gold.xitu.io/entry/581d9f8cda2f60005df771fe
http://stackoverflow.com/questions/2641489/what-is-a-thunk
http://web.jobbole.com/85901/
Javascript是单线程的深入分析
redux是个好东西
对redux也是久闻大名了。之前我就说过react组件之间要共享状态,就只能写一些很恶心的代码,结果这居然是react官方推荐的做法。。。但我还是觉得很蛋疼。
那时我虽然没用过redux,但知道他要解决的是什么问题。不过实际研究了下redux后,发现实现上和我想的还是有些不一样。
这不是个redux教程,只是总结一些感想。
借用一张图片: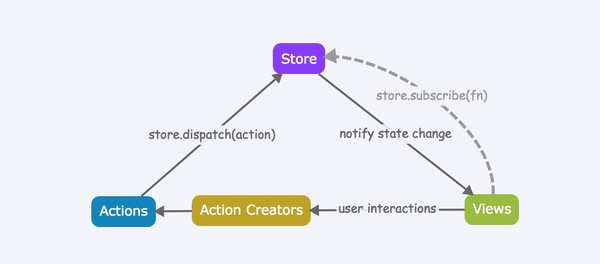
其实redux的核心非常简单,概念上无非是store/reducer/action,操作上也就是dispatch/subscribe,都很好理解。一些tips:
- reducer必须是个纯函数。纯函数是非常非常重要的概念,action creator也必须是纯函数。纯=没有副作用/没有状态/对同样的输入肯定会得到同样的输出。
reducer(previousState, action) => newState,这就是reducer的作用,每次都应该返回一个新的对象。为什么这个函数叫做 Reducer呢?因为它可以作为数组的reduce方法的参数。MapReduce中的reduce也正是来源于此。也许以后可以批量处理action?感觉不太可能。。。- Store是全局唯一的状态存储,只能通过dispatch去修改,对应用而言store是只读的
- 状态变化时会触发listener,但不会传什么参数,需要自己去查store
- reducer在 default 情况下一定返回旧的 state。千万不要返回undefined。。。血泪教训。
- 注意全局的初始状态
- action应该是个不可变对象。尽量减少在action中传递的数据。
Object.assign()和{...state,}应该是同样的效果。但要注意深拷贝和浅拷贝的区别。Object.assign()貌似是浅拷贝,有些时候会有潜在的bug。bindActionCreators/combineReducers有多种使用方式,根据传入参数的类型不同(object/function)区分。当然结果上没啥区别,爱用哪种看心情
另外注意redux其实跟react没啥关系,可以应用到其他任意地方,因为它本身只是一个“可预测的状态容器”。我曾经见过把redux用到微信小程序上的。
redux的设计借鉴了很多函数式编程的思想,非常抽象,非常学院派,概念简单,功能却很强大。而且它的实现里大量利用了js的函数式特性,在我看来可以做到很多“黑魔法”一样的事情。如果看了它的源码,就会叹为观止,我都怀疑自己会不会js了,我可能是学了假的js。。。比如bindActionCreators/combineReducers之类,只会用,凭空想很难想到它是如何实现的,看了代码之后都觉得实现非常精妙。而且redux的代码量非常少,建议大家都看看。
如果java的思想去做类似的事,有些是根本实现不了,有些就算实现了代码也会很别扭。。。
也许这就是函数式语言的特性吧,很适合开脑洞,能做出很多精巧、让人拍案叫绝的东西。
另外,对于react-redux而言,它使用了一种被称作“高阶组件”(Higher-Order Component)的技巧,使用connect()方法包装原有的组件使状态被redux托管。这种技巧还是很有用的,antd的Form组件中也有用到。
redux的一个“缺点”就是让你的程序更复杂,更难懂。更复杂的程序就意味着更容易有bug。如果不了解redux的原理,也很容易搞出问题来。“如果你不确定是否需要redux,那就不要用”。千万不要为了符合所谓的“业界标准”而引入redux,要看实际的需求。
但我对redux还是有一些遗留的问题:
- 为什么reducer不会跟特定action关联
我最开始以为redux是一个类似于EventBus的publish-subscribe模型。每个reducer只订阅特定类型的action。换句话说,每个action只会触发一个reducer的代码。
但redux目前的实现却是触发一个action后,这个action要在所有的reducer中都“过一遍”,因为redux是不知道哪种reducer处理哪种类型的action的,也就是没有一个“注册”的过程。
我们在写reducer时会拆分成一个个小的reducer,每个小reducer都只处理特定action,最后用combineReducers合并为一个大的reducer。但这也只是为了编码上的方便而已,处理action时没啥本质区别。
为啥redux会采用这种方式呢?也许是因为比较简单吧,但如果action的种类太多,真的不会有性能问题么?这种方式还有个问题,如果某两个reducer会处理同样type的action,可能会隐性的bug,而且不好排查。只能在编码时注意。
理论上来说publish-subscribe应该效率会更高一点,因为有着“先验知识”,可以针对性的处理。但也要考虑到DeadEvent的问题。
- newState会有一个merge的过程么?
store中保存着preState,当有action触发时,会经过reducer得到一个newState,newState和preState会有一个merge的过程么?还是直接丢掉preState?
现在redux的实现是直接丢掉preState。这样如果action非常多,就会有非常多的无用对象,会不会有gc问题?
所有用到不可变对象的地方,其实都可能有类似的问题。
- 如何设计状态是个大麻烦
虽然state本身只是一个普通的js对象,理论上可以有任意复杂的结构,但为了方便使用和维护还是要遵循一些原则。个人感觉应该尽量“扁平”,尽量不要嵌套。
一些文档中提到的设计原则:尽量使state可以轻松的转化为JSON;尽可能地把state范式化,不存在嵌套;把所有数据放到一个对象里,每个数据以ID为主键;把state想象成一个数据库。
另外,react组件有自己的状态,但store中又存在全局状态。哪些状态做成全局的,哪些做成局部的,都要仔细考虑。
同理,拆分reducer也是个麻烦,哪些reducer要管理哪些状态。
目前我的做法是每个组件一个reducer,维护每个组件的全局状态。整体的state就是所有组件的全局状态组合起来,类似这种:
|
|
不知道这样做好不好。
- 会不会有并发的问题?
换句话说,store.dispatch()是同步还是异步?如果同时触发多个action,处理顺序会错乱么?之所以想到这个问题,是因为react文档说setState可能是异步的:
setState() does not immediately mutate this.state but creates a pending state transition. Accessing this.state after calling this method can potentially return the existing value.
相关分析见这里。我猜react这么设计可能是为了提升Controlled Components的性能?毕竟Controlled Components用起来很蛋疼,用户每输入一个字符就render一次完全没必要。。。
现在dispatch的实现是同步的,也就是说一个action必须reduce完毕才能开始下一个action。而且js本身就是单线程的,应该不会有race condition。但代码中却有一个isDispatching变量,和这样一段代码:
|
|
理论上来说,这个错误应该永远不会触发啊。不可能同时处理两个action。所以这个isDispatching是啥意思。。。
- 状态变化如何反应到组件上?
换句话说,如何做数据绑定?总不会是像angular一样的dirty-check。。。
从代码上来看,每次状态变化后,会立刻调用所有listener(同步调用),这时listener就能感知到状态变化了。这里有一个问题:每个listerner所关心的状态是不同的,为啥要所有listener轮询一次呢?如果能知道哪些状态变化了,再触发对应的listener,是不是效率更高?这还是一个为啥不用publish-subscribe模型的问题。。。
不过那样就需要redux去做diff算法了,必须知道状态中哪些字段变化了,反而让store变得更复杂。也许跟redux追求简单的设计哲学不符吧。
话说,高效diff两个对象,好像Immutable.js中提供了一种专用的数据结构?
但对于react-redux而言,根据我的测试,每次store的变化都会触发所有组件的re-render。。。即是说,真正的listener是App组件(最上层组件)的render方法,每次状态变化都会导致App re-render,进而导致所有子组件re-render。。。这样真的不会有性能问题嘛?有些组件根本就跟store里的状态没关系(没有用connect方法包装),根本就没有必要re-render吧。
我本来还在想,redux根据什么知道哪些组件需要哪些状态?根据什么检测到状态的变化导致特定组件重新render?结果它直接简单暴力的全部re-render。。。看来还是我想多了。。。但这样真的有性能隐患的,大量无用的re-render会的导致频繁的dom-diff。虽然我们可以通过pureRender/PureComponent/Immutable.js之类的手段去优化shouldComponentUpdate方法,去避免这种系统能损失,但总归增加了额外的工作量和复杂度。
归根结底一句话,redux为啥不用publish-subscribe模型啊。。。
另外说下中间件,redux的中间件有点类似JavaEE的filter,也是继承了redux一贯的简洁风格。中间件可以用如下的形式来表示:
|
|
所以可以按自己的需要很方便的写一些特定的中间件。
另外要注意下中间件的次序。
redux中最常用的中间件应该就是redux-thunk和redux-promise了,二者都是用来做一些异步操作的。细心些就会发现,这我们上面说的用生成器做异步操作的两种方式(thunk/promise)正好是对应的。这其实算不上什么巧合,因为对于异步操作,redux和生成器关心的问题是类似的。生成器关心的是“异步操作结束后如何要回代码执行权”,redux关心的是“异步操作结束后如何触发新的action”。所以他们的解决方法也都类似。
重点说说Thunk中间件。redux中的thunk相当于一种特殊的action creator。普通的action creator直接返回action对象,而thunk会返回一个function(入参是dispatch),我们就可以在这个function中做异步操作,异步操作结束后重新dispatch了。store.dispatch时如果发现入参是function,就会执行它。原理其实非常简单,代码:
|
|
一个例子:
|
|
参考资料:
Redux DevTools Extension:调试redux必备
关于action格式的社区规范:
https://github.com/acdlite/flux-standard-action
https://github.com/acdlite/redux-actions
其他一些react/redux的文档:
http://cn.redux.js.org//docs/introduction/index.html
https://github.com/react-guide
https://github.com/camsong/redux-in-chinese
http://stackoverflow.com/questions/36085726/setstate-in-reactjs-is-async-or-sync
Immutable 详解及 React 中实践
React移动web极致优化
前端是个大坑
我虽然一直戏称自己是二手前端,但其实对前端也研究了不少了,尤其是跳了react的坑之后。
千言万语汇成一句话:前端是个大坑。而且比我目前跳过的任何坑都深。。。如果对自己的“抗折腾”能力没自信,千万不要入坑。
虽然已经有无数人吐槽过了,但我还是忍不住要吐槽下。。。槽点多不可怕,关键是总是有新的槽点出现,这就很蛋疼了,再专业的吐槽也遭不住啊。
- 总是有各种稀奇古怪的新东西
昨天还说promise要一桶浆糊,今天就说async/await是终极解决方案了。
昨天还是react集万千宠爱,今天就开始一股脑吹捧vue了。
还有fetch,这货用起来还一堆问题,timeout都不支持,就已经有人在叫着ajax已死了。
npm还没搞明白,又跳出来一个yarn。
同构应用?怎么突然开始流行这个概念了?
服务端渲染?感觉又是一个大坑。
WebAssembly、WebComponents,这都是什么鬼?
总结下就是:心累。。。不过新技术很多,至少说明这个领域一直在发展,我还算可以接受。
- 缺少规范
在研究redux的时候,工程结构又让我纠结了好久。。。有人说reducers代码放一个单独的文件夹,actions放一个单独的文件夹,但也有人说放在一起。然后把组件强制分为“显示组件”、“逻辑组件”?显示组件里才有render方法,只从props里读数据并显示;逻辑组件里只有一个connect方法。。。不蛋疼么。。。
更别提webpack的各种坑爹配置了。
总之就是每个人都有自己的做事方法,缺少一个统一的规范。在合作大型项目的时候,真的不会有问题么?本来么,没有规范大家商量出来一个就可以了,各方妥协下,但总是有人认为自己的方式就是比别人好,我也只能呵呵。。。这应该说是有傲骨呢还是情商低呢。。。
以后前端领域会不会细分出来一个角色:“Dev Environment Administrator”,专门负责维护开发环境,各种配置都丢给他去搞。。。就像现在的SA一样。
- js果然还是不适合协作?
同一个组件我有6种写法你信不?
|
|
这6种写法居然是一样的效果你敢信?一毛一样啊。让我想到孔乙己的“回字有4种写法”。。。你要是对ES6不熟,看到这一堆货肯定直接懵逼。
如果了解过一些python vs perl在语言哲学上的区别,就可以知道js和perl类似,也是典型的many ways to do one thing。换句话说,可以玩出非常多的花样,非常灵活。我在写js的时候就特别激进,会尝试使用各种新特性,一遍遍的重构代码;但我写java的时候就很保守。。。说实话很多java8甚至java7的特性都还没用过。。。毕竟生产环境也只是jdk7而已。
但对于协作而言,这种灵活性就可能导致问题。每个人的思路、代码风格都千差万别,有些人就很喜欢用function component,有些人就喜欢用普通的class。
在这种情况下,统一的编码规范或者说是“最佳实践”非常重要。啥是最佳实践?不同的人去实现同样的功能,他们的实现是类似的,达到这个效果就可以。毕竟大型协作项目中要的不是炫技,不是各种hack,而是可读性、可维护性。这种哲学在python中其实是非常常见的,python可以说直接从语言层面给出了最佳实践。
比如对于react组件,我就倾向于不要使用函数式组件,全都用class去定义。这样虽然会有冗余代码,但代码很“规整”,更清晰。
- 啥时候能不用写css啊
对css实在是无力吐槽了,折腾起来太麻烦了。布局居然有好几种方式:float/position/flex之类。我前段时间还特意把css布局的教程从头到尾看了一遍,以为已经是天下无敌了,结果过段时间就全部忘掉了。。。
这玩意如果不是天天用,根本记不住。只能是头痛医头脚痛医脚,哪里显示有问题就打开chrome慢慢调试。所谓的调试也是在凭感觉乱搞,display:block不对?那就试试display:inline-block;position:absolute有问题?那就试试position:relative,要不再加个float;边界有问题?那就left/right-margin/padding统统搞一遍试试。。。
作为二手前端,css是最让我头疼的东西了。据说很早以前写css和写js的人是分开的?设计师做好页面写好css再让程序员去填写逻辑。不过那可能是静态网页时代的做法了。。。
题外话,我之前一直疑惑npm run start和npm start有啥区别,后来发现原来start和test对npm而言是特殊处理的。。。见这里:In addition to the shell's pre-existing PATH, npm run adds node_modules/.bin to the PATH provided to scripts.
这tm也是个隐藏很深的坑。。。
杂七杂八
google协程的过程中,顺便了解了很多并发相关的事情。如果不考虑多核(并行),只考虑单核下分时间片执行(并发)的情况下,并发最大的代价就是上下文的切换。所以并发模型的演进(多进程->多线程->Event Loop->协程)其实一直致力于减少上下文切换的开销。参考:1/2。
其实并发是个很复杂的问题,还涉及到指令乱序/重排、内存可见性等等蛋疼事,可以看下《七周七并发模型》。
看某篇文章时突然想到,到底啥是架构?
我一直觉得“架构”是个很容易有水份的词。架构本质上是一种抽象,它的抽象能力必须足够强大,才能承载各种各样形态的具体业务。如果业务超出了你的架构的抽象能力,要么对系统做“大手术”,要么削减业务(有点削足适履的感觉)。
说的通俗点,什么是好的架构?就是迥然不同的业务逻辑,系统的底层却是完全相同的。搞零售的和玩期货的,用的是同样的底层系统;每天一单的普通个人店铺,和峰值十万单的大V,是同样的底层系统;一口价和团购,用的还是同样的底层。从这种角度上来说,DNA-蛋白质这套系统,算是个好架构吧。。。不过这个与其说是架构,更像是“语言”。
但是如果抽象过度了,架构也就没啥用了。借用一张“神图”:
这张图是很久之前在微博上看到的,好像是在讲云计算什么的。这张图的“神”就在于,你可以在所有的分布式系统、云计算、甚至是什么组织结构、神经系统之类上面套用这张图,反正就是一个中心节点+一堆子节点么。。。如果你敢跟老板说这就是你的系统的架构图,信不信分分钟被打出去。。。这张图生动的告诉了我们,什么是“正确的废话”。
所以,架构对业务的抽象,必须限定在一定的范围内,至少要让人看明白吧。越抽象就会丢失越多细节,如何把握这个“度”,才是我们应该思考的。
另外注意要划分清楚系统的边界(业务边界),不可能有一个系统能承载所有的业务的,要知道哪些该做/哪些不该做。
一般而言,当我们接到需求时,首先要从业务的角度出发去看,梳理清楚所有的业务规则,保证整个业务流程是通畅的,能走通的;然后再去考虑如何去实现业务逻辑,如何让各个业务规则的实现不要互相干扰并且便于扩展。也就是先有需求再有架构。
尤其不要依赖于具体的技术实现,这对以后的系统改造也会方便很多,比如php迁移到java之类的。
但很多人看到需求总是会直接联想到代码。。。这其实是有问题的。。。
另一个很容易犯的错误:代码依赖于具体的数据库/应用服务器实现,比如依赖于mysql+tomcat,也会为日后的扩展埋下隐患。
总结?
怎么写了这么多。。。最近乱七八糟的研究了很多东西。其实我本来是想学下redux的,不知道怎么回事就开始研究async/await、生成器了。。。
发现我如果学什么东西,一不小心就会变成DFS。看到一个新的概念就会去google,然后偏离主题。。。最后才想起来自己本来想学啥。这样会不会栈溢出啊。。。
之前搞的React后台意外收获近100个star,受宠若惊,也帮助了一些人。看来不能拖更了。
数了下2016年只写了9篇blog。。。比我想的少很多。
好长时间没有刷算法题了。。。我的leetcode题解也坑了好久。
果然懒惰才是我最大的敌人啊。。。
