生命不息,吐槽不止。
题目与内容无关。
电商架构
只是开发相关的部门。
我一直对电商公司的架构缺少个整体的了解,近日一个同事给我讲了讲,感觉清晰了些,大概整理下。
随便画个图: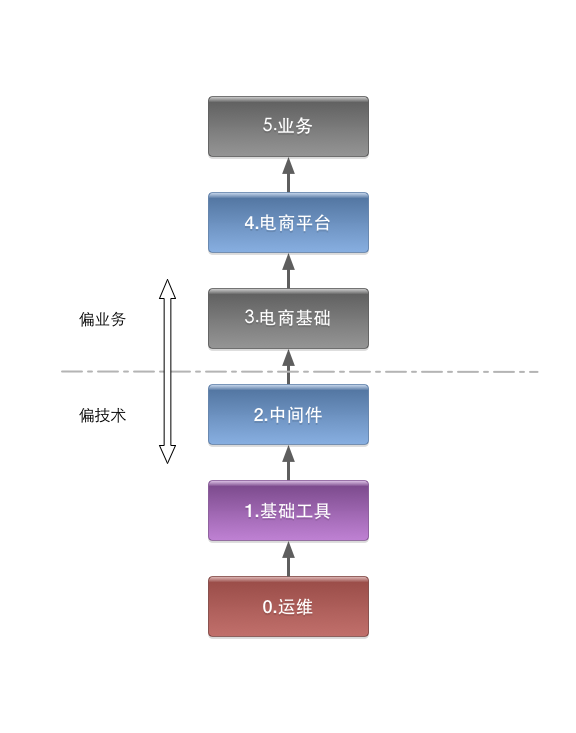
有点像OSI的七层模型。。。但这个图很不严谨,只是个大概的分类。
偏向技术:
0.运维-关键字:SA/机房/监控和报警/docker/云主机,一切的基础,就是传说中的op。
1.基础工具-关键字:git/nexus/持续集成/文档中心/jira/自动部署,这块我们叫做技术保障部。可能也有叫做dev op的。
2.中间件-关键字:MQ/日志收集/db分库分表/搜索、算法、推荐?这是最大最模糊的一块,不是传统意义上的java中间件,凡是跟业务不直接相关的都可以丢到这里。
这三块也许应该叫业务支撑部门,很少有业务逻辑,更多关注技术。
偏向业务:
3.电商基础-关键字:商品中心IC/店铺中心SC/用户中心UC/交易/安全/支付,电商业务中的基础服务。
4.电商平台-关键字:选品/投放/运营工具/自动化建站,为实现业务需求提供平台化的工具,提高效率;直接和运营打交道。
5.具体业务-这里才是真正实现业务需求的地方。
有个假设,每一层只会跟下层打交道,只对上层提供服务。比如中间件不会来调用电商基础的接口,电商基础也不会去调用电商平台的接口。
以前,我大概是工作在第0层的,跟第2层也沾点边。现在工作在第4层,变化还是挺大的。
感觉嘛,以前可以专心研究技术,去研究源码,可以搞自己感兴趣的东西,像在学校一样。也跟网易的氛围有关系。但是没有业务,就没有话语权,在一些事情上就会非常被动。
现在,经常被运营赶着走,被各种吐槽。整天就是迭代、需求、开各种会议,也许技术上没以前进步那么快了,但也对业务有了更多的理解。
各有利弊吧。
另一个变化就是心态。以前是一种学院派的心态,做事前会想的很多,考虑各种细节,有十足的把握再动手;现在越来越草莽。。。凡事先从需求出发去考虑,以解决问题为最优先,不再那么完美主义。什么系统都敢做。。。不敢说做的多完美,至少能用。有种落草为寇的感觉。。。
项目管理是个很复杂的东西
作为开发参与了某个项目,历时两个月,中间出了各种各样的问题,深感项目管理真的是很难。
项目管理的目标说起来很简单,无非是协调进度、控制风险、保证产品按时完成。但然并卵,知道了不等于会做,不等于不会出错。
我不知道怎样才是正确的,只能说说自己看到的一些问题。
- 每个人对需求的理解都不同。需求方提出需求,经过产品方的加工细化,再反馈到开发、测试。这中间就有很大风险,信息可能“失真”。但即使直接跟需求方对接,也很难保证需求、产品、开发、测试有相同的理解。往往是开发按自己的理解做事,但需求方却说“这不是我要的东西”;测试按自己的理解写测试用例,但跟开发出的系统背道而驰;甚至需求方自己也不能理解需求,他们往往只有一个模糊的概念,不同的时间去问他,可能会得到不同甚至相反的答案。。。所以要将需求落实到文档上,也就是PRD文档,一切以这个文档为准。这个文档必须得到各方一致认可。对于开发而言,不在这个文档内的功能,都是计划外的,如果一定要做,请走需求变更流程,项目延期也不是我的责任;对于测试而言,直接对照PRD文档写测试用例,如果某个用例无法通过,就是开发的责任。所以PRD文档是非常非常关键的,这个文档必须有绝对的权威性。
- 需求不详细。有PRD文档不代表万事大吉。写的烂的PRD和没有差不多。一般PRD是由需求方和产品先商量一致后给出初版,然后由开发和测试确认,经过必要的修改,最后存档,作为日后撕逼的基础。但即使是PRD中的描述,也未必足够详细,主要体现在一些细节上,比如文案、校验条件,总会有些模糊的地方。这些模糊的地方,又会导致各方理解上的偏差,那要PRD还有何意义?PRD就是为了“统一思想”而存在的。所以这里对产品经理要求很高,他们必须把需求理解透彻并写到PRD中。另外我不得不说,NB的产品经理是真NB,水的也是真水。。。两极分化很严重。一些人鼓吹“人人都是产品经理”,只能呵呵。好的PRD应该覆盖所有的用例,最好还有界面原型。另外对于开发而言,必须逐字逐句的去研究PRD,吹毛求疵也不为过,所有不合理的、模糊的地方必须指出并要求修改细化,并重新审核。即使冒着项目无法按时开工的风险,也不能让步。因为一旦确认PRD,所有风险都会转移到自己身上。如果日后因为需求模糊而出问题,只能自己背锅。但有个风险在于有时你不能自己决定,可能是你的技术leader/其他同事来决定,他未必会那么仔细,这就要自己好好去沟通了。
- 设计过分复杂。确认PRD后,一般会进入设计阶段。我不了解前端/视觉的设计,只说说后端的技术方案的设计。我只负责几个模块,但要上线的时候,得知居然整个产品分了10个子系统,还有依赖关系,我就震惊了。。。这就是“想太多”。开发在设计系统的时候,往往会考虑扩展性,考虑性能,考虑“通用”而过度设计。但对需求方而言,他才不关心你如何实现。他只关心时间,越快越好。如果能先做一些小系统满足他的需求,观察下这个产品确实有活下去的价值,再重构,也许会更好。随着产品的发展,架构上的推倒重来是不可避免的,不可能有一劳永逸的方案。总不能上线初期就非要按twitter的体量去设计,最后DAU只有几百。。。另外有些同学总是先设计数据库表,姑且叫做数据库驱动设计(Database Driven Design, DDD)吧,这是个很不好的习惯。他们往往先在mysql中建好表,再设计上层的系统,设计各种接口。这样思路不会受限嘛?而且为啥这么确定存储是mysql嘞。。。
- 过分乐观。定下技术方案后,需要预估工作量,这个时候往往会过分乐观。有很多原因,有时是有外部依赖,比如依赖于别人的工作,但估时间没有考虑到他人的进度;有时是只考虑编码时间,没有考虑联调/测试;有时就是自己经验不足,或者碰到技术难题,很难一概而论。根据测试那边的反馈,大多数项目预估的工作量都不准,甚至一周估成一天都可能。测试建议我们在自己估的时间基础上*1.4,还是有点道理的。但更大的问题在于leader可能直接拍板定下工作量是xx人日,这就不是乐观不乐观的问题了。。。
- 责任不明确。其实就是个分工合作的问题,解耦不够彻底。单独的模块应该由单独的人负责,不同的模块、系统如果有依赖,在设计时就应定好交互的接口,而不要在开发时再改来改去。如果你的接口变化,导致我的模块延期,这个风险不是我的责任,而且这个风险必须通知到项目中所有人。
- 非技术人员随便给出技术建议。“不就是加个按钮嘛”,“加个同步就ok”,“从标题就能取到数据”。这个没啥好说的,搞技术的都碰到过。对方讲道理的话就解释下,否则只能开撕了。
- 测试用例过度。开发中存在过度设计的情况,测试中也可能存在。很多测试用例都是针对一些corner case,比如输入长度,一些文案等。某人因为一个地方的文字应该是“图片”还是“头图”跟我争了半天。。。这当然说明测试很敬业,我很佩服。但在项目延期风险很大的情况下,是否应该有所变通?更关键的是,很多PRD中没有的东西,也会出现在测试用例里,测试会考虑各种“误操作”的情况。虽然说从做产品的角度来说,要把用户都当成白痴,但这是内部系统啊,都是同事在用,就那么信不过他们的智商嘛。。。
- 会议冗长低效。开了很多会议,需求评审、测试用例评审、xx评审,但效果很差。说实话,我坐在下面看他们讲,都不知道他们讲的是什么,昏昏欲睡。开会比写代码还累。只有到跟我相关的部分,才大概听进去一些。我讨厌开会,很多会议的意义在于“这件事已经通知你,别说你不知道,现在不仔细听以后出问题就是你的责任”。。。但有些会议又真的无法避免,只能想办法提高效率了。个人感觉,时间不要太长;事先把会议的内容发出来,让大家先看下有个准备,带着问题去开会;每次只跟特定的人开会,比如前端的需求就只跟前端的人开评审会,不要把所有人都叫上。其实“如何高效的开会”这个问题已经超出项目管理的范畴,是一个更普适性的问题了。
- 沟通问题。沟通真是人类亘古以来最大的难题。沟通成本随项目参与的人数呈几何级数上升,就像巴比伦塔的故事一样。而且我们还要经常和北京的团队沟通,有些问题面对面都说不清,何况电话/邮件。沟通的问题有很多种,比较突出的是:只在口头上达成一致,但过段时间对方又不认了;有些变化没有通知所有人,只是小范围知道。有个笨方法是每次都邮件@所有人,当然不是所有人都会看,但出问题时可以说“我之前邮件通知你了啊”,虽然个人觉得这样很不负责任。。。
综上,大部分问题都出在需求阶段。如果需求能明确、详细,后面很多的问题其实都可以避免。
另外项目经理必须足够强势,统筹全局,该吵架就要吵,总是和稀泥是不行的。
在做这个项目的时候,几乎觉得这个项目已经在慢性死亡了。就像打dota,己方只剩基地,对面都神装了,但就是不推进。自己知道要输,出于职业精神还不能早退,就只能耗着。好在,经过2次延期后,这个项目终于结束了,虽然不如人意,砍掉了一堆东西,成品跟设计完全不一样,但也算阶段性胜利了。
经过这个项目,我现在很想尝试下敏捷开发,不知道如果用敏捷方法来做这个项目,会不会有更好的结果。但敏捷也不是银弹,不能解决上面的所有问题,只是另一个方向的尝试罢了。
其他一些教训:
- 所以的一切都落实到文档上。IM上的沟通不算数。
- 出问题时,不要总是抱怨,要想解决办法。抱怨不解决任何问题。
- 加班能解决的问题都不是问题。
- 学会保护自己。换句话说,学会甩锅,但不能乱甩,要有理有据的甩。
话说,虽然我上面写了这么多,但给其他人看,估计也不会有什么感悟。因为有些事情真的只能自己经历过才能理解,别人再怎么对你解释都没用。像我当初学软件工程、软件文档、软件测试的课程时,觉得这个真水,有毛线用啊,凑学分的吧,刷GPA的吧。但现在体会到了,真的是有用的。很多我觉得“水”的东西只是因为我不懂,以后吐槽要小心些了。
运维思维
我发现运维经验在日常工作中还是很有帮助的。至少有问题时可以自己排查,而且一些任务也可以自己写脚本完成,不用找op。
做运维时,很多东西必须从底层去理解原理。现在也就养成了这样一种习惯,对于未知的库、未知的框架,总想搞明白原理,不一定要去看代码,但必须要有个能自圆其说的解释,这样开发时心里也就更有底。
看到一些同学,只会用ide,很少用命令行,maven/git之类的只在eclipse里用,其实这样不太好,出了问题大多数情况下还是要到命令行里排查。
正好最近看到一篇运维相关的文章,讲的还不错:用十条命令在一分钟内检查Linux服务器性能。
运维思维的另一个体现是开发时总是会考虑监控、报警、统计之类的运维需求。如果我做的系统完全没有监控,就会很心虚。。。虽然公司没有强调,但脑中总会有个SLA的概念。有些时候,写这些运维需求的代码,会比写业务代码更耗时间。。。因为现在我们的运维工具/平台很不完善,很多要自己做。
其实还有一个好处,但是不是技术相关的。由于做过运维,与op交流时也就会更高效,知道哪些事确实不是op的锅,不会强人所难。
可能的话,推荐大家都体验下做op的感觉。就像在某些公司里,技术也要经常轮值去做客服一样。
做OP/PE最重要的是服务态度,是及时响应、换位思考,技术反而是次要的。
只有体验过,才能互相体谅,甩锅的时候才不至于甩错。。。
商品管理
工作中想到的一些问题。面对亿级别的商品,如何有效管理?
仔细想想,其实不止是商品,任何东西都是这样,比如管理一大堆图书,管理很多图片。所谓“管理”,另一个说法是“如何组织数据”。目的是为了快速检索,如何能快速找到想要的商品/图书/图片。否则我要遍历整个数据集才能确定哪些是我想要的。从这个角度说,有点类似索引。
一个不太恰当的比喻:商品管理就是面对一大堆object,我们要判断他们的class是什么,并且把class用一定的结构组织起来。比如java的package结构。
首先大家都会想到分类。比如把衣服分成男装/女装,上装/下装,图书分成英文/中文之类的。感觉这是人类的本能啊,见到陌生的事物都会尽量先套用到已有的认知模型里。分类的好处是天然的树状结构,便于理解,B+树不也就是按主键id的范围分类么。生物学中的界、门、纲、目、科之类,就是这样的产物。问题在于分类的标准是什么?不是每个人都是林奈。各个类别之间,总会有些模糊的界限,导致一些实体(姑且这么称呼),放在类别A可以,放在类别B似乎也没错。就像哥德尔的不完备性定理一样,总会有些不能证真也不能证伪的命题,分类系统中也总是会有些无法明确类别的实体。没办法保证所有类别是互斥的。简言之,就是逼死强迫症。而且分类的标准有时很难让人理解,我就一直很奇怪为什么蜘蛛不是昆虫,而要搞一个单独的蛛形纲。
回到电商,商品管理很重要的一块就是类目体系。这是一颗很大的树,但深度有限制(据说最多4级?),每个商品会唯一挂到一个叶子节点下面。这个概念很好理解,有点类似网站中的面包屑导航,只要一级一级点下去,就能找到你想要的商品。但电商们又在这颗树上搞出了一些新的玩法。首先,每个节点都会有特定的属性,称作类目属性。每个商品都必须对照模版去填对应的值。比如手机类目,会有“厂商/制式/系统”等属性(称之为属性模版),而一个iphone商品就会有对应的“apple/4G/ios”属性值,像class和instance。这只是一个虚构的例子,实际上系统这种属性都可以拿出去单独做一个类目了。类目和属性相辅相成,商品的某些特质,可以作为类目,也可以作为属性,要看运营如何抉择。属性有几种:关键属性,决定SPU,比如品牌+型号确定唯一款手机;销售属性,决定SKU,比如服装的颜色、尺码;简要属性:直接展示在商品详情页。属性的管理也非常复杂,包括属性的层次结构,属性和类目的关联等等,不比商品管理简单。其次,衍生出了前台/后台类目的差别。大意是前台用于展示给用户,经常改变,比如随季节变化;后台用于展示给卖家,比较稳定。前台类目是一个“虚拟的”类目体系,一个前台类目可以映射到多个后台类目,多个前台类目也可以包含同一个后台类目。这也是出于精细化运营的需要。有点类似React中的虚拟DOM?
为了弥补分类系统的不足,又出现了另一种组织方式:标签。这也很好理解,人们在日常生活中一直是这样做的。比如你说你是东北人,就会被某些人贴上“大男子主义”之类的标签。。。知乎上更是各种“XX癌”、“XX婊”的标签泛滥,这和所谓的“扣帽子”是一回事,有些是无心的,有些是恶意的。所以现在都在提倡no judge,不要随意下判断。扯远了。。。如果说分类系统是一棵树,那标签系统就是一个HashMap,可以快速把贴着某个标签的所有实体选出来。我见过一些完全用标签管理图片的系统,还挺好用的。标签系统的一大好处是标签库可以让用户自己去不断丰富,类似UGC。
电商中的标签,更多的是对类目体系的一些辅助。当然如果一定要较真的话,标签和类目概念上还是有重叠的。尤其是类目属性。商品的某些特性,可以表达为属性,也可以表达为标签,这个没有定式。另外,标签也是有类别的。可能有些标签是描述商品手感的(丝柔顺滑之类的),有些是描述风格的(小清新/复古),还有些干脆是从评论中提取的(质量好/发货快)。所以标签管理也是很复杂的一个问题。是否会有一个“标签树”?
总之,商品管理最常用的两种方法:类目和标签。以上只是我一些很初级的理解。也许还有其他形式,我就不清楚了。
当然没有完美的方法,只要能解决实际问题就可以,不要在意那些细节。
就像各种奇怪的物理理论,超引力/弦理论/P膜之类的,你相信这个世界真的是这样么?但它们能解决特定问题。数学模型能解释物理现象,就是好模型。如果能进一步,做出预测并被证实,就会被很多人奉为真理了。
商品管理是电商中非常基础的服务,会影响到所有环节,比如搜索会根据关键词预测类目,减少要检索的商品数量。
最近我常做一件事,就是在淘宝的搜索页看它给出的过滤条件,猜测哪些是类目,哪些是属性,哪些是标签,挺有意思的。
linode再见
我的linode节点又一次被qiang,终于下定决心放弃了。懒得再折腾了,又要去提ticket,又要换ip。还要去改dns。本来还想换个机房试试,但ping了下速度也不咋样。
仔细想想,用了一年多,每月10刀,也没干啥,就偶尔用来翻翻qiang,搭了个gitlab,有点浪费啊。每月那么多的带宽根本用不了。
在某个高富帅的推荐下,换用了EurekaVPT,顿时感觉逼格提升了很多。
速度很快,关键在mac上可以实现全局代理,ios也能用,很方便。
以前为了给iphone翻qiang,折腾过pptp、openvpn,各种蛋疼。
虽然说生命在于折腾吧,但有限的人生面对无限的折腾,总要有所取舍。
另外关于dns再提醒下,运营商自动分配的dns一般都有劫持,google的8.8.8.8又丢包严重。可以考虑阿里dns或v2ex dns。其实国内dns服务商挺多的,但有节操的不多。。。
锁和一致性
研究ReentrantReadWriteLock时,脑洞大开,想到一些问题。
首先看到了读锁和写锁,由此想到乐观锁和悲观锁。但其实这根本不是同一个层次的东西。悲观锁就是我们通常说的锁,也叫排他锁/写锁,而乐观锁根本不是锁,是一种重试机制。基本原理是先读取当前数据的版本号,然后对数据做修改并写回,但写回的时候会判断版本号和之前的是否一致,如果不一致说明数据变化了,会重试“读取-修改-写入”的过程,直至写入成功。用过zookeeper的都知道,修改某个znode节点数据时必须带版本号的,感觉和那个有点类似。
由乐观锁想到CAS。我的理解就是处理器级别的乐观锁指令,原理上是一样的。话说这个缩写到底是Compare And Set还是Compare And Swap。。。google的过程中找到一篇文章,讲了JVM里的各种锁。从来不知道锁分这么多类型,偏向锁我只在JVM启动时的参数里听说过。
由synchronized关键字又引申出java内存模型(JMM),引伸出变量可见性和happens-before语义。大意就是由于编译器的优化和处理器的乱序执行,代码的执行顺序不一定是和源文件中一致的。而synchronized代码块却一定可以保证顺序。关于JMM,我以前研究volatile时了解过一点,但现在才知道所谓的working memory完全是逻辑上的概念,以前还奇怪gc的图上怎么没这块内存。
由乐观锁又想到mysql中的MVCC,据说这也是一种乐观锁。以前听登博讲过一点,但没听懂。。。于是google去,找到了这个,图画得挺清楚,内容上有点疑问。据说mysql中MVCC只在READ_COMMITTED和REPEATABLE_READ下有效,而且似乎只对读起作用?多个事务并发修改同一份数据时,没看出来mvcc有啥作用?关键是没看到重试机制,可能是我不了解。这个MVCC的原理就是在undo中保存数据的快照,读取的时候,根据当前事务选择特定的版本。有了mvcc,读肯定不会阻塞了,即使其他事务在某行上加了排它锁。摘录一段话:“理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。”
可见,乐观锁的应用场景其实很有限。
关于undo和redo日志,我以前也有点模糊。redo log其实就是WAL,用于系统挂掉时恢复用的。undo log则是用于回滚的。其实undo功能上可以代替redo,也能恢复数据,但效率很差。而redo是顺序写,效率很高。这也是WAL的标准特性了。
MVCC又引出了mysql的事务隔离级别。mysql中的4种标准的隔离级别大家都知道,READ_UNCOMMITTED会读到未提交的数据,即脏读;READ_COMMITTED会读最新提交的数据,但同一个事务中,同样的查询可能读到不同的值,因为其他事务会修改数据,这个叫不可重复读还是幻读?REPEATABLE_READ是mysql默认的隔离级别(可能和版本有关),保证在同一个事务中,同样的select语句,读到的数据肯定都是相同的,无论字段值还是行数;SERIALIZABLE最好理解,所有事务串行执行。模糊的地方在于到底什么是幻读?网上有种说法是READ_COMMITTED下读到的数据值会变,叫做不可重复读;REPEATABLE_READ下读到的数据行数会变,叫做幻读。但根据我亲自测试,REPEATABLE_READ读到的行数不会变啊,即使其他事务新插入了几行数据,在当前事务中也看不到,测试方法见这里。读不会产生幻觉,反而写会产生幻觉,主键跟一条不存在的记录冲突。。。也许跟mysql版本有关?
我甚至觉得不可重复读跟幻读根本就是同一个东西。。。但根据wiki的说法,确实是有区别的。只能说mysql的REPEATABLE_READ实现比较特殊了?
由隔离性想到ACID,其实这里的C我一直都不太理解,这个东西太抽象了。什么保证各种约束的完整性,这个各种约束到底是啥。还有分成读一致性/写一致性的,还有nosql中的最终一致性。这篇文章讲的比较有道理,“一致性”这个词,在不同的系统中有不同的含义。不要过于纠结。
由ACID又会牵扯到CAP。其实CAP有很多争议,至少这两个词里的C的含义是不同的。我一直都觉得hbase很难套用到CAP理论里:hbase是强一致性(写入的数据马上就能读到);数据肯定是分区的(那么多regionserver呢);高可用(虽然我觉得不算真正的高可用)。似乎C/A/P三个条件都能满足啊,于是就凌乱了。。。话说,这些理论,听听看看就好了,很多都不是“真理”,甚至可能被证实是“谬论”。我们做工程的,要把主要精力放在解决实际问题上。
既然提到两阶段提交,我就又google了下,但没太懂。如同那个作者说的“本质上就是锁定”,而且这个算法一眼看去就觉得有很多问题。。。看上去很美,但实现起来肯定一堆坑要填。话说,有哪些系统实现了两阶段提交?如果能实际使用下可能就理解了。
两阶段提交又会引出paxos,这货太难懂了,实在不想碰它。而且这个东西和多线程一样,当时你觉得自己完全懂了,已经是天下无敌了,过段时间再看,又是一堆问题。。。
既然提到MVCC,不可避免的涉及到锁。mysql提供了表级/页级/行级的锁,但我不想再深究了,暂时脑容量不够了。。。
微服务
看某篇文章有感。
微服务的好处到底在哪里。也许从单独一个模块看确实清晰好维护,但整个系统看来不会更复杂么,是一个互相交错的网。以前是同一个系统中的模块互相调用,现在是各个系统之间通过RPC/REST互相调用,效率肯定会变差吧。而且很难搞清楚调用关系,从我们的dubbo使用经验来看,调用链很长,一旦出问题调试起来还是挺麻烦的。
所以微服务需要一个强大的中心管理者角色,梳理整个系统的调用关系,监控各个系统的状态之类的。没有这样一个角色,微服务就会很坑爹。所以实践微服务才需要那么多的基础服务。这会带来额外的开销。这种开销是否值得,就要权衡了。
但微服务有个实实在在的好处就是分批发布,不会说有个模块功能变化,就要重新发布整个系统。
其实很多公司在实践中已经不自觉的用到微服务了吧,但都是手工做的,没有形成系统的规范、框架罢了。换句话说,没有形成方法论。
重构一个系统时,我们都会提到水平切分/垂直切分,那微服务算啥?网状切分?。。。
也许算作垂直+水平吧。
不管怎么切,不要过度设计。很多时候没必要切的那么细。
一些读后感
RPC之恶。“单看 RPC 给编程实现带来的方便性,其实最终是增加了,而不是减少了系统的复杂度”。RPC只是看着很方便,很容易被滥用。像dubbo这种,编码的时候真的感觉不到是RPC,就当普通的方法用了,但一跑起来就一堆问题。对RPC请求应该更谨慎处理的。
将Hadoop的计算和存储分开能有效的提升性能。很有趣的观点,这么搞的前提是有足够的带宽。以前强调数据本地性,是因为在机房中带宽才是最宝贵的资源,最多就千兆网络。如果未来万兆网络能普及,也许真的不用考虑本地性了。
微信斑马系统。我关注的是对于数据如何使用。用户画像->人群聚类->精准推广,这个过程很有意思。另外它的隐私策略也值得思考,各种数据产品很少去考虑隐私,而PII(Personal Identifiable Information)数据理论上是不能被使用的,有法律风险。另外,这是一个去中心化的系统,由商家自己去运营、分析,也有些借鉴意义。
SOA与微服务的比较和对比。概念上的模糊不影响使用,不要纠结于学术之争。感觉微服务就是SOA的一种实现方式。
Wix是如何把MySQL当NoSQL用的。把mysql当作KV来用,很有意思。若干年前我听雷火的一个分享,也提到把mysql当作key-value来用。实际中的很多工程里,我们也是这么做的,比如存一个大json进去,需要的时候再去解析。当数据量不大的时候,mysql作为KV挺好用的。当然也要看业务,OLAP之类的就算了。
Spark 2015 AND Spark 1.6。spark这一年的发展,说是“恐怖”也不为过。记得几年前还是个实验室项目,却这么快变成业界标准。就像每年都有人给出下一代iphone的概念设计图,看上去很美,大家都知道是假的,结果特么居然成真了。。。1w+的contributor是什么概念。。。可惜由于工作原因,不像以前关注那么多了。听说RDD要退出历史舞台了,继续感叹发展速度。。。
如何选择开源项目
只是作为用户发一些牢骚。
选择开源项目最重要的是什么?我最关注的是活跃度。包括社区的活跃度、commit频率等。如果碰到问题,作者/社区是否能很快的修复?如果一个项目都好几年没人维护了,这怎么敢用?没错我说的就是dubbo。。。据说dubbo本来是阿里云的人搞的,后来要统一切换到淘宝的HSF,dubbo放弃了可惜,于是就开源了。。。
但有些时候是没得选的,像dubbo这种,没什么好的替代品,只能硬着头皮用,踩到坑也要自己填,于是就很痛苦。。。
还有velocity,也是好久没人维护了,我很不想用。但要维护一些已有的系统就不得不用。。。
这就是个技术倾向性的问题。不会有啥大问题,就是影响心情。
将精力花在一些过时的技术上,也很不值得。
另外一定要避开所谓的toy project,尤其是一些个人开源的,没什么实际应用案例的。最近看到了一个系统,作者没用spring mvc或是jersey之类的,而是自己发明了一个mvc框架。虽然美其名曰开源框架但其实也只是自己用。。。看这种代码异常痛苦啊。而且这个代码很奇怪,本来想说奇文共欣赏摘录一段给大家看看的,但一时找不到。大概就是把java写成汇编的感觉,各种奇怪的缩写/下划线,什么camelcase都靠边站。一眼望去,真的看不出来是java的代码。。。
反过来说,怎样才是一个负责的开源项目?不是把代码扔上去就不管了,要有详细的用户文档和实例,良好的反馈机制,及时修复问题。更进一步,测试覆盖率/设计文档/注释/项目管理等等。除非真的是没得选,我会更关心这些“软实力”。
其他
写到最后才发现,怎么这么多字,刷新了我的记录了吧。
我的习惯是脑中出现什么念头就先记下来,有空再慢慢整理成文字。所以这篇文章其实是断断续续写了大半个月的,内容也很杂。
关于题目。解释下大陨石之术:小说写到最后,作者编不下去的时候,往往会搞一些突发事件,让角色挂掉,于是就可以顺理成章的完结了,这被称为“天降大陨石”。。。当然所谓的陨石可能是意外/疾病之类的。如果有读者非要较真,还可以美其名曰“开放式结局”。。。
这篇文章本来叫做《方法论SC》的,是《方法论?》的续篇。某天凌晨3点多读完了《白夜行》,惊觉大陨石之术重现江湖,甚感欣慰,久不能平,决定改下标题以示纪念。。。
其实当时我的心情是:are you kidding me??
扯回正事。最近写工作总结和规划,我写到想做一些有趣的事,不要一直重复日常。怎样才是有趣的?我仔细想了想,研究新的技术当然算有趣,但我更想做一些东西,让用户发挥自己的创造力,不要受我的限制。如果用户能在我的系统上找出我意想不到的玩法,我也会很开心。用游戏来比喻的话,可能是《恶魔城》的出城,或者《马里奥制造》《Minecraft》之类的。
像暴雪爸爸一样,买地图编辑器送游戏。。。
还只是很模糊的想法,希望以后能有机会吧。
