近日重看了《HBase权威指南》,结合着0.98.8的代码,总结一些知识点。
由于hbase版本更新很快,而且每个版本变化都很大,本文不一定适用于其他版本。
我们是0.94和0.98混着用的,也可能有些0.94的知识点混在里面。。。
话说,hadoop还是Hadoop我都觉得挺正常,但hbase就不如HBase顺眼。。。
B+树和LSM树
太理论的我也不懂。
B+树是传统RDBMS中实现索引的关键。特点是数据都在叶节点,而且查找操作非常高效。
但更新代价比较大,可能导致叶节点的分裂。更新索引的时间可能比真正写数据的时间还长,一些大表的索引比数据还大。
而且对磁盘的依赖较大,因为机械磁盘的随机读写性能都是比较差的。所以RDBMS都在往SSD发展。。。
较适合读多写少的情况。
LSM树的核心思想在于延迟更新,会将数据/索引的更新暂时以日志的形式记录下来,等待后台线程去合并。
可以将随机写转化为顺序写(将update和delete都转化为insert),所以不像B+树那样受机械硬盘的限制。
特别适合大量写入的情况。读性能也不错,但storefile过多的话,估计读性能会下降比较快。
由于需要后台线程合并,有额外开销。当这种额外开销超过带来的性能收益时,就不值得了。也是一种trade-off。
关于hlog
注意hlog是regionserver级别的。所有region的日志都会写到一个文件中。当需要回复的时候,按不同的region拆分hlog。拆分好后,region才会开始回放日志。这个拆分的过程可能会非常慢,因为日志文件没有任何索引,只能从头遍历。
这种设计的前提是需要hlog拆分的情况比较少,可以将所有hlog写入转换为顺序写,提升性能。如果每个region维护一个hlog,可能造成大量随机写。
hlog其实就是hadoop的sequence file,其中key是HLogKey对象,包括region,tablename、sequence id、时间戳等信息;value是WALEdit对象。一个WALEdit对象中可以包括多KeyValue对象(这应该是为了保证行级别的原子性。如果更新一行中的多个列,会产生多个KeyValue对象,但在hlog中只保存一条记录)。
hlog对于写入影响很大,所以可以关闭wal或者延迟刷新wal以提升性能。
日志文件滚动有2种情况:
- regionserver中的LogRoller进程每一小时触发一次日志滚动。
- 当日志文件达到hbase.regionserver.hlog.blocksize大小时,触发日志滚动。
每次日志滚动的时候,都会触发一次对oldlog的检查。这个检查有2种情况:
- 遍历所有hlog file,如果某个hlog file中最大的sequence number小于所有store file中最大的sequence number,说明对应的hlog file中的记录已经全部持久化了,这个hlog file可以被删除了。所谓删除也不是马上删除,而是移动到一个临时目录(0.94是/hbase/.oldlogs),等待master中的一个LogCleaner线程来删除。相关逻辑见FSHLog.rollWriter方法。
- 如果hlog file文件数量大于hbase.regionserver.maxlogs,就遍历最老的一个hlog,找到哪条记录还没有被持久化,强制相应的region做一次flush,然后将最老的文件移动到临时目录等待删除。
hlog拆分
当集群启动或regionserver挂掉时,都需要拆分/回放日志。
以0.94 hbase为例。
所有hlog都存在/hbase/.logs/${regionserver.id}目录下。当回放hlog时,hmaster会按顺序遍历这个目录下所有文件,将对应region的日志放到一个临时目录/hbase/splitlog/${regionserver.id}/${region.name}。当一个hlog拆分完毕后,对应的文件会移动到/hbase/.oldlogs,等待master中的线程去定期删除。当所有hlog文件拆分完毕后,将拆分后的日志移动到/hbase/${table.name}/${region.name}/recovered.edits目录,然后打开region。region打开时如果发现recovered.edits目录,就会回放其中的日志,回放完毕才能对外服务。
hlog拆分机制经历过很多变化,从早期版本的单线程拆分,到多线程,到目前的分布式处理。
关于HA
hbase没有真正的实现HA。根据上面的分析,当一个regionserver挂掉后,要经历很长时间的hlog拆分、回放过程。
拆分log时,会遍历/hbase/.logs下所有文件,日志越多恢复服务所需时间也越长。
所以及时删除log是很必要的,删除机制见我上面的分析。
region split
用户可以设置自己的split策略,我们一般用ConstantSizeRegionSplitPolicy,同时将hbase.hregion.max.filesize设为一个比较大的值,这样可以手动控制split的时机。注意这个属性限定的是一个store的大小,而不是整个region的大小。
split过程非常快,因为只是新建一些引用文件,当一个引用文件对应的数据被compact处理后,才会删除引用文件。
当一个region中存在引用文件时,不能再次split。
触发compact检查的几种情况
compact是hbase里特别折腾人的机制之一。
有几种操作会触发compact检查:
- memstore flush
- 在hbase shell里执行compact、major_compact命令
- 调用HAdmin类的相应方法
- regionserver中有一个线程CompactionChecker,默认每10秒执行一次,检查所有online的region
每次触发compact检查后,再判断是minor还是major(用户手动触发的major_compact除外)。
compact的临时数据会写到/hbase/${table.name}/${region.name}/.tmp目录中。
RegionServer中有一个对象CompactSplitThread负责compact/split/merge region。这货虽然叫XXThread但其实不是线程。。。
每个compact是否是major,由CompactionPolicy.isMajorCompaction方法决定。
默认的RatioBasedCompactionPolicy只会检查hbase.hregion.majorcompaction属性。
所以这个属性设为0之后就不会触发major compact。但由minor提升而来的major还是存在的(如果某次minor compact选择的storefile就是当前region的所有storefile,就会提升为major compcat,只会出现在写入较少的表上)。
每次compact后会再检查一次是否要split。
关于flush与compcat
每次flush后,都会检查是否需要split、是否需要compact,见MemStoreFlusher类。
如果要split,就直接split;否则再检查是否要compact。是否compact由StoreEngine.needsCompcation方法决定。
默认是DefaultStoreEngine,其实是交给RatioBasedCompactionPolicy.needsCompaction方法决定。
我以前以为split后会立刻触发compact,看来不是。
关于large和small线程池
CompactSplitThread中有两个线程池:large和small。
如果一次compact要处理的数据量大于hbase.regionserver.thread.compaction.throttle,就进入large线程池。否则进入small线程池。
这个large/small和是否major compact没有必然联系。不知为何要这样设计。
关于hfile
HFile格式: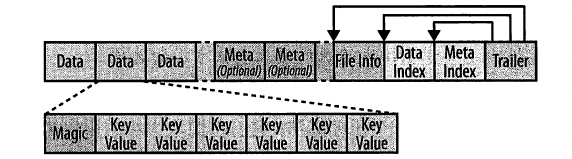
KeyValue格式:
HFile一旦写入完成,就是不可变的。因为hdfs要修改已经存在的文件只能append,而HFile元数据在末尾,不能直接append。
DataIndex和MetaIndex是类似于B+树的索引结构。RegionServer启动的时候,会将所有索引加载到内存里,便于后续查找。
这个索引只能到块的级别(索引了每个块的rowid范围),同一个块内的KV是没索引的,只是按Key排序。所以想找特定的KV时,可能要遍历整个块。
注意只有rowid是有索引的,而且对于column family、column qualifier是没索引的。
hbase默认的块大小是64KB。写入的数据量大于64KB后,会生成一个新的块并写入。如果开启了压缩,写入的数据一般小于64KB。如果写入一个特别大的KV,也可能大于64KB。
hbase的块和hdfs的块没有任何关系。
KeyValue其实很多信息都是冗余的。比如column family,在同一个storefile中肯定全都是一样的。
为了减少查询开销,节省空间,务必选择名称较短的列族和列。
hbase读路径
说说自己的理解,没有看代码求证过。
- 如果读请求中包含时间戳条件,根据storefile的时间戳排除一些文件。
- 如果能应用bloom filter,又可以排除一些storefile。
- 在剩下的storefile和memstore里扫描所需数据。由于storefile和memstore是有rowid索引的,可以快速选出一批备选storefile。
- 扫描备选的storefile,定位到所需的block。遍历block,找到所需的KeyValue。在这个扫描过程中,还要加上其他一些过滤条件,比如特定的列名。
- 猜测扫描顺序是先memstore,再按时间降序扫描所有storefile。这样可以取得最新的数据,跟踪到同一份数据的update/delete。
关于二级索引
hbase中只有一种索引:rowkey(转换成byte[]按升序排列)。而如果需要多种索引就比较麻烦。
- 存多份数据,并建不同的rowkey格式。缺点是数据量放大很多倍。
- 用户自己维护一个索引表。其实不一定是索引表,也可能是用于索引的列族。这种方式很难保证原子性,很可能数据表已经更新,但索引表还没更新(索引表可能是用MR定期更新)。而且用户写代码时也要自己处理索引表相关逻辑。
- coprocessor。不是很了解,我的理解是将方法2中用户手动的操作转换为服务端自动的操作。
关于bloom filter
相关原理见这篇文章。
bloom filter对get操作很有效,因为可以快速判断一个rowkey是否在一个storefile里。
但scan操作不一定有效,因为scan是个范围,bloom filter无法判断这个范围的所有rowkey是否都在某个storefile里。
在0.98中建表是默认都开启了ROW级别的BloomFilter。
ROW级别的BloomFilter对Scan一定是无效的。
ROWCOL级别的BloomFilter对包含列条件的Scan可能有效。
所以bloom filter是否适用还是要看自己的使用场景。
常见服务端优化
- JVM调优。regionserver对内存非常敏感。目标:减少老年代的内存碎片,尽量让对象在新生代就死亡;减少FGC,否则可能触发zk超时。
- 开启MSLAB特性。默认是开启的,但可能浪费一些内存。
- 开启snappy压缩。snappy压缩优于lzo。
- 手动管理split和compcat、监控storefile数量。这也是无奈之举。尽量在流量低的时候做这些操作。
- 分散热点,将写入量较大的region分散到不同regionserver。
常见客户端优化
|
|
建表时的一些优化:
- 尽量只有一个列族
- 预分区
- 列族和列的名字尽量短
- 尽量开启snappy/lzo压缩
- 开启bloom filter(0.98默认会开启ROW级别的,如果有特殊需求可以开启ROWCOL级别的)
服务端比较重要的一些配置项
比较容易出问题的一些配置。
| 配置项 | 说明 |
|---|---|
| zookeeper.session.timeout | zk客户端的超时设置,也受服务端限制 |
| hbase.regionserver.handler.count | rpc handler用于处理客户端读写。当每次RPC操作数据量较小时,这个数字可以设的大一点,否则可能对regionserver产生较大内存压力,进而造成GC问题。要结合自己的内存大小来设置。 |
| hbase.regionserver.maxlogs | 每个regionserver保存的日志文件数量,不要太大,不然回放日志时间很长 |
| hbase.regionserver.hlog.blocksize | 每个hlog日志文件的大小,不要太大,不然回放日志时间很长 |
| hbase.hstore.blockingStoreFiles | 当某个store中storefile数量超过这个值时,整个region就会阻止继续写入,等待后台合并 |
| hbase.hstore.blockingWaitTime | 跟上一个配置相关。每次阻止写入多长时间。 |
| hbase.hregion.memstore.block.multiplier | 如果客户端写入过快来不及flush,memstore最多可以增加到几倍,之后会阻止写入 |
| hbase.hregion.max.filesize | 每个region的大小,超过这个大小会触发自动split,只有当hbase.regionserver.region.split.policy设置为ConstantSizeRegionSplitPolicy时才有效 |
| hbase.regionserver.regionSplitLimit | 当一个regionserver上region数量达到这个数字,就不会自动split了。但还是可以手动触发。 |
| hbase.hregion.majorcompaction | major compact的周期,设为0可以关闭自动major compact。跟compaction policy有关,默认是RatioBasedCompactionPolicy |
| hbase.hstore.compaction.min | 每次minor compact,最少选择多少个storefile? |
| hbase.hstore.compaction.max | 每次minor compact,最多选择多少个storefile? |
| hbase.hstore.compaction.max.size | minor compact时,大于这大小的storefile会被排除 |
| hbase.regionserver.thread.compaction.large | compact时large线程池的大小 |
| hbase.regionserver.thread.compaction.small | compact时small线程池的大小 |
| hbase.regionserver.thread.compaction.throttle | 如果一次compact(不分minor/major)处理的数据量大于这个值,进入large线程池;否则进入small线程池。 |
