公司活动写的一篇文章。这里也发下吧。
介绍下YARN中资源调度相关概念和算法。以hadoop 2.2.0为准。
YARN虽然是从MapReduce发展而来,但其实更偏底层,它在硬件和计算框架之间提供了一个抽象层,用户可以方便的基于YARN编写自己的分布式计算框架,而不用关心硬件的细节。由此可以看出YARN的核心功能:资源抽象、资源管理(包括调度、使用、监控、隔离等等)。从某种程度上说YARN类似于IaaS。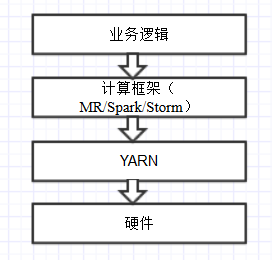
YARN的基本概念不再赘述。一些缩写:RM = ResourceManager、NM = NodeManager、AM = ApplicationMaster。
什么是资源?
对一个资源管理系统而言,首先要定义出资源的种类,然后将每种资源量化,才能管理。这就是资源抽象的过程。
先抛开YARN不谈,在一个分布式、多用户的系统中,什么是资源?
我们通常所说的“资源”都是硬件资源,包括CPU使用/内存使用/磁盘用量/IO/网络流量等等。这是比较粗粒度的。也可以是抽象层次更高的TPS/请求数之类的。其实广义来看,时间、人力等“软件”也是资源,可惜一般很难量化。
为什么要有“资源”这个概念?首先可以用来衡量系统的瓶颈,系统能否充分利用资源?什么时候应该扩容?在多用户的系统中,“资源”还额外承担着限制用户的功能。比如当总体资源紧张时,重要的用户可以优先获得资源,有更高的资源上限,普通的用户更难获得资源。
YARN的资源抽象比较简单,只有两种资源:内存和CPU。而资源数量是管理员手动设置的,每个NM节点可以贡献一定数量的内存(MB)和CPU,由RM统一管理,不一定是真实的内存和CPU数。
其中内存资源是比较关键的,直接决定任务能否成功。如果某个任务需要的内存过多,可能无法执行,或者OOM。CPU资源的限制比较弱,只限定了一台NM上能并发执行多少任务。如果并发的过多,执行的可能比较慢。
基本概念
Container
Container是RM分配资源的基本单位。每个Container包含特定数量的CPU资源和内存资源,用户的程序运行在Container中,有点类似虚拟机。RM负责接收用户的资源请求并分配Container,NM负责启动Container并监控资源使用。如果使用的资源(目前只有内存)超出Container的限制,相应进程会被NM杀掉。
可见Container这个概念不只用于资源分配,也用于资源隔离。理论上来说不同Container之间不能互相影响。可惜现阶段YARN的隔离做的还不太好。
Container的另一个特性是客户端可以要求只在特定节点上分配,这样用户的程序可以只在特定的节点上执行。这跟计算本地性有关。后面会讲到。
Container是有最大资源限制的。在我们的设置中,每个Container最多只能有8G内存,8个CPU。这是由RM端的参数yarn.scheduler.maximum-allocation-mb和yarn.scheduler.maximum-allocation-vcores决定的。
调度器与队列
在YARN中,调度器是一个可插拔的组件,常见的有FIFO,CapacityScheduler,FairScheduler。可以通过配置文件选择不同的调度器。
在RM端,根据不同的调度器,所有的资源被分成一个或多个队列(queue),每个队列包含一定量的资源。用户的每个application,会被唯一的分配到一个队列中去执行。队列决定了用户能使用的资源上限。
所谓资源调度,就是决定将资源分配给哪个队列、哪个application的过程。
可见调度器的两个主要功能:1.决定如何划分队列;2.决定如何分配资源。此外,还有些其他的特性:ACL、抢占、延迟调度等等。
后文会对这几种调度器分别介绍下。
事件驱动
YARN实现了一套基于状态机的事件驱动机制:很多对象内部有一个预先定义好的有限状态机,相应的事件会触发状态转换,状态转换的过程中触发预先定义的钩子,钩子执行的过程中又生成新的事件,继续状态转换。这种设计的好处是耦合小,但不太好理解。
几个角色:
Dispatcher —— 用于分发事件,一般是异步的。内部用一个BlockingQueue暂存所有事件。
Event —— 事件类型。
Handler —— 事件的消费者。每个消费者只handle特定的事件,所有Handler要在Dispatcher上注册。
这个机制在YARN的各个模块中用的非常广泛,不只用于调度器。
pull-based
通俗的说,AM通过心跳向RM申请资源,但当次心跳申请的资源不能马上拿到,而是要再经过若干次心跳才能拿到。这是一种pull-based模型。
AM通过RPC协议ApplicationMasterProtocol与RM通信。这个协议在服务端的实现会调用YarnScheduler的allocate方法(所有调度器都必须实现YarnScheduler接口)。allocate方法有两个作用:1.申请、释放资源;2.表示AM是否存活。超过一段时间AM没有调用这个方法,RM会认为AM挂掉并尝试重新提交。
allocate方法有3个参数:
那真正分配container是什么时候?答案是NM的心跳时。当NM向RM发送心跳时,会触发一个NODE_UPDATE事件。schduler会handle这个事件尝试在这个node上分配container。里面有一系列判断,比如当前节点是否有足够资源、优先给哪个application分配资源。如果成功分配container,就加入一个List中,等待AM下次心跳来取。
这点跟以前的JobTracker比较像,也是TaskTracker各自去拉取任务。
常见调度器
前文说过,调度器的两个主要作用:1.决定如何划分队列;2.决定如何分配资源,这里又分两种情况:为队列分配资源和为单个application分配资源。从这两方面看下常见的调度器,重点分析下FairScheduler。
FIFO
最简单、也是默认的调度器。只有一个队列,所有用户共享。
资源分配的过程也非常简单,先到先得,所以很容易出现一个用户占满集群所有资源的情况。
可以设置ACL,但不能设置各个用户的优先级。
优点是简单好理解,缺点是无法控制每个用户的资源使用。
一般不能用于生产环境中。
CapacityScheduler
在FIFO的基础上,增加多用户支持,最大化集群吞吐量和利用率。它基于一个很朴素的思想:每个用户都可以使用特定量的资源,但集群空闲时,也可以使用整个集群的资源。也就是说,单用户的情况下,和FIFO差不多。
这种设计是为了提高整个集群的利用率,避免集群有资源但不能提交任务的情况。
特点:
- 划分队列使用xml文件配置,每个队列可以使用特定百分比的资源
- 队列可以是树状结构,子队列资源之和不能超过父队列。所有叶子节点的资源之和必须是100%,只有叶子节点能提交任务
- 可以为每个队列设置ACL,哪些用户可以提交任务,哪些用户有admin权限。ACL可以继承
- 队列资源可以动态变化。最多可以占用100%的资源。管理员也可以手动设置上限。
- 配置可以动态加载,但只能添加队列,不能删除
- 可以限制整个集群或每个队列的并发任务数量
- 可以限定AM使用的资源比例,避免所有资源用来执行AM而只能无限期等待的情况
当选择队列分配资源时,CapacityScheduler会优先选择资源用量在规定量以下的。
当选择一个队列中的application分配资源时,CapacityScheduler默认使用FIFO的规则,也可以设定每个app最多占用队列资源的百分比。
关于CapacityScheduler一个比较重要问题就是百分比是如何计算的。默认的算法是DefaultResourceCalculator类的ratio方法,只考虑了内存。也就是说CapacityScheduler调度时是只考虑内存的。管理员也可以手动设置选择其他算法。
优点:灵活、集群的利用率高
缺点:也是灵活。某个用户的程序最多可以占用100%的资源,如果他一直不释放,其他用户只能等待,因为CapacityScheduler不支持抢占式调度,必须等上一个任务主动释放资源。
FairScheduler
我们一直在用的调度器。设计思路和CapacityScheduler不同,优先保证“公平”,每个用户只有特定数量的资源可以用,不可能超出这个限制,即使集群整体很空闲。
特点:
- 使用xml文件配置,每个队列可以使用特定数量的内存和CPU
- 队列是树状结构。只有叶子节点能提交任务
- 可以为每个队列设置ACL
- 可以设置每个队列的权重
- 配置可以动态加载
- 可以限制集群、队列、用户的并发任务数量
- 支持抢占式调度
优点:稳定、管理方便、运维成本低
缺点:相对CapacityScheduler,牺牲了灵活性。经常出现某个队列资源用满,但集群整体还有空闲的情况。整体的资源利用率不高。
下面重点看下资源分配的算法。
Max-min fairness算法
FairScheduler主要关注“公平”,那么在一个共享的集群中,怎样分配资源才算公平?
常用的是max-min fairness算法:wiki。这种策略会最大化系统中一个用户收到的最小分配。如果每一个用户都有足够地请求,会给予每个用户一份均等的资源。尽量不让任何用户被“饿死”。
一个例子:资源总量是10,有3个用户A/B/C,需要的资源分别是5/4/3,应该怎样分配资源?
第一轮:10个资源分成3份,每个用户得到3.33
第二轮:3.33超出了用户C的需求,超出了0.33,将这多余的0.33平均分给A和B,每个用户得0.16
所以最后的分配结果是A=3.49,B=3.49,C=3
上面的例子没有考虑权重,如果3个用户的权重分别是0.5/1/0.8,又应该如何分配资源?
第一轮:将权重标准化,3个用户的权重比是5:10:8。将所有资源分成5+10+8=23份,按比例分配给各个用户。A得到10*5/23=2.17,B得到10*10/23=4.35,C得到10*8/23=3.48。
第二轮:B和C的资源超出需求了,B超过0.25,C超过0.48。将多出资源分配给A。
最后的分配结果是A=2.9,B=4,C=3
由于进位的问题会有些误差。
更多用户的情况下同理。
DRF
Max-min fairness解决了单一资源下,多用户的公平分配。这个算法以前主要用来分配网络流量。但在现代的资源管理系统中,往往不只有一种资源。比如YARN,包含CPU和内存两种资源。多种资源的情况下,如何公平分配?Berkeley的大牛们提出了DRF算法。
DRF的很多细节不提了。核心概念在于让所有application的“主要资源占比”尽量均等。比如集群总共X内存,Y CPU。app1和app2是CPU密集型的,app1每次请求3个CPU,app2每次请求4个CPU;app3和app4是内存密集型的,app3每次请求10G内存,app4每次请求20G内存。设分给app1、app2、app3、app4的请求数分别是a、b、c、d。DRF算法就是希望找到一组abcd,使得3a/X=4b/X=10c/Y=20d/Y。
如何判断CPU/内存密集型?如果任务需要的CPU资源/集群总的CPU资源 > 需要的内存资源/集群总的内存资源,就是CPU密集型,反之是内存密集型。
实际应用中一般没有最优解,而是一个不断动态调整的过程。和max-min fairness一样,也要经过多轮分配,才能达到一个公平的状态。
如果考虑权重的话,算法会更复杂一点。另外在单一资源的情况下,DRF会退化为max-min fairness。
资源分配过程
了解了一些基本的算法,接下来看看FairScheduler的资源分配过程。
前文说过NM的心跳会触发一个NODE_UPDATE事件,scheduler同时也是这个事件的handler,会尝试在对应的节点上分配container。
在FairScheduler中,所有的queue、application都继承了Scheduable,构成一个树状结构。资源分配的过程就是从这颗树的根节点开始查找,直到找到一个合适的Scheduable对象的过程。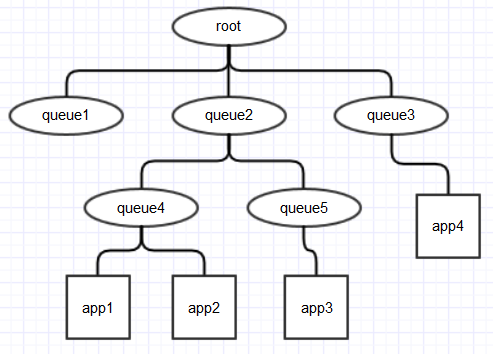
以上图为例,共有3种对象:ParentQueue(root是一个特殊的ParentQueue)、LeafQueue、Application,只有LeafQueue才能提交app。
每个Queue可以定义自己的SchedulingPolicy,这个policy主要用于Scheduable对象的排序。目前共有3种SchedulingPolicy的实现:FifoPolicy、FairSharePolicy、DominantResourceFairnessPolicy,FIFO只能用于LeafQueue,其他两种Policy可以用于任意Queue。默认是FairSharePolicy。
分配Container是一次深度优先搜索:从root节点开始,首先检查当前节点资源是否用满,是则直接返回(这里会同时考虑CPU和内存)。如果当前节点是ParentQueue,就将所有子节点排序(SchedulingPolicy决定了这里的顺序),依次尝试在每个子节点上分配container;如果当前节点是LeafQueue,就将下面的app排序(也是SchedulingPolicy决定,但加入了一些app特有的判断条件),依次尝试为每个app分配资源;如果当前节点是app,会比较当前app的资源需求与节点的剩余资源,如果能满足,才真正分配container。至此整个资源分配过程才完成。如果找不到合适的app,最后会返回null。
从上面的过程可以看出,每次NM心跳时,都会触发一次资源分配,而且只能分配一个container。所以NM的心跳频率会影响到整个集群的吞吐量。另外可以配置参数yarn.scheduler.fair.assignmultiple让一次心跳分配多个container,默认是false。
下面看下默认的FairSharePolicy是如何排序的。这个policy只考虑内存资源,但跟max-min failness不太一样。max-min fairness关注整体资源的公平分配,而FairSharePolicy目的在于公平分配“被调度的机会”,所以最终的资源分配可能不是算法上的最优解。但目的是一样的,都是让所有app有机会运行,不会被饿死。
每个Schedulable对象都有minShare、maxShare、fairShare 3个属性,其中minShare、maxShare用于排序,fairShare用于抢占式调度,后文会讲到。此外还有权重属性(weight),也会用于排序。对于queue而言,minShare、maxShare就是fair-scheduler.xml里配置的minResource和maxResource,weight也是直接配置的。对于application而言minResource直接返回0,maxResource直接返回Integer.MAX_VALUE,weight如果没有配置yarn.scheduler.fair.sizebasedweight=true就直接返回1.0,意味着所有app的权重是相同的。
FairSharePolicy在比较两个Schedulable对象时,先看是否有已分配资源小于minShare的,如果是说明当前Scheduable处于饥饿状态,应该被优先满足。如果两个Schedulable都处于饥饿状态,就看谁占minShare的比例更小(谁更饿)。如果没有饥饿状态的,就比较两个Schedulable已用资源与权重的比例,这个比例越大,说明占用了越多的资源,为了公平,应该给另一个Schedulable分配资源。
DominantResourceFairnessPolicy是YARN中DRF算法的实现,会考虑内存和CPU两种资源,排序逻辑会更复杂些,这里略过。
任务分配过程
任务分配过程决定一个app被分到哪个队列。相对于资源分配过程,这个过程简单的多。因为app在提交的时候一般会指定队列名。
第一步:检查提交的app是否指定了队列名。如果没有指定,检查是否存在和用户同名的队列。如果还不存在,就提交到default队列。default队列可以在配置文件中指定,也可以在调度器初始化时默认创建。
第二步:检查ACL,当前用户是否有向指定队列提交任务的权限。
第三步:如果通过ACL检查,发出一个APP_ACCEPTED事件。app加入LeafQueue的children,开始等待资源分配。
FairScheduler的一个特点是客户端可以动态创建队列,即指定一个不存在的队列。但生产环境中这一般是不允许的。
抢占式调度
FairScheduler特有的功能。当某个队列资源不足时,调度器会杀死其他队列的container以释放资源,分给这个队列。这个特性默认是关闭的。
关键点有两个:1.启动抢占式调度的条件?2.选择哪些container去杀掉?
前文说过每个Schedulable对象都有minShare、fairShare属性。这两个属性是抢占式调度的阈值。当一个Schedulable使用的资源小于fairShare*0.5、或者小于minShare,并且持续超过一定时间(这两种情况的超时时间不同,可以设置),就会开始抢占式调度。
Schedulabe的fairShare是会不断变化的(minShare一般不会变化)。如果队列的minResource、maxResource、权重等属性变化,fairShare都要重新计算。application开始或结束,也都要重新计算fairShare。FairScheduler中有一个线程UpdateThread,默认每0.5秒调用一次update方法,就会重新计算fairShare。
计算fairShare的过程就是将“上层”Schedulable的fairShare,“公平”的分配给下层的Schedulable。计算过程从root queue开始。root queue的fairShare就是整个集群的可用资源。怎样才算公平?要综合考虑各个Schedulable的权重、minShare、maxShare,算法也是由SchedulingPolicy决定的。默认是FairSharePolicy。这个计算逻辑跟max-min fairness类似。
当FairScheduler决定开始抢占时,首先会计算要抢得的资源量。对于使用资源量小于minShare的,要恢复到minShare;对于使用量小于fairShare*0.5的,需要恢复到fairShare。将所有要恢复的资源量相加,得出要抢的的资源总量。然后遍历所有LeafQueue,找到所有资源用量大于fairShare的app,将他们在运行的container加入一个List,按优先级升序排列。然后遍历,优先杀死优先级低的container。当释放足够的资源后,抢占停止。
如何确定container的优先级?这是由AM在申请资源的时候决定的。用一个整数表示,数字越大优先级越低。以MapReduce为例,AM Container是0,Reduce Container是10,Map Contaienr是20。意味着一个map任务更容易被杀死。
抢占式调度可以一定程度上保证公平,但不可控因素比较多。如果用户的长时间任务因此失败,是不可接受的。所以生产环境一般关闭这个特性。
计算本地性
从MapReduce时代开始,“移动计算比移动数据更经济”的概念就深入人心。在YARN中,当然也继承了这一传统。这一特性主要是用来配合HDFS的,因为HDFS的多副本,任务应该尽量在选择block所在的机器上执行,可以减少网络传输的消耗。如果开启了Short-Circuit Read特性,还可以直接读本地文件,提高效率。
本地性有3个级别:NODE_LOCAL、RACK_LOCAL、OFF_SWITCH,分别代表同节点、同机架、跨机架。计算效率会依次递减。
根据前文所述,Container在申请时可以指定节点,但这不是强制的。只有NM心跳的时候才会分配资源,所以container无法一般确定自己在那个节点上执行,基本是随机的。scheduler能做的只是尽量满足NODE_LOCAL,尽量避免OFF_SWITCH。计算本地性更多的要AM端配合,当AM拿到资源后,优先分配给NODE_LOCAL的任务。
但FairScheduler中,允许一个app错过若干次调度机会,以便能分到一个NODE_LOCAL的节点。由yarn.scheduler.fair.locality.threshold.node控制。这个参数是一个百分比,表示相对整个集群的节点数目而言,一个app可以错过多少次机会。
比如yarn.scheduler.fair.locality.threshold.node为0.2,集群节点数为10。那么FairScheduler分配这个资源时,发现当前发来心跳的NM不能满足这个app的NODE_LOCAL要求,就会跳过,继续寻找下一个APP。相当于这个app错过一次调度机会,最多可以错过2次。
对RACK_LOCAL而言,有一个参数yarn.scheduler.fair.locality.threshold.rack,作用差不多。
发展趋势
YARN的发展一直比较快,调度/资源相关的一些值得关注的改进:
Label based scheduling
https://issues.apache.org/jira/browse/YARN-796
https://issues.apache.org/jira/browse/YARN-3214
可以给不同的节点加上标签,比如某些节点CPU频率比较高、某些节点内存比较大,RM在调度的时候,可以更有针对性。甚至可以分成多个小集群供不同用户使用。
管理更多资源
磁盘:https://issues.apache.org/jira/browse/YARN-2139
网络:https://issues.apache.org/jira/browse/YARN-2140
Dynamic resource configuration
https://issues.apache.org/jira/browse/YARN-291
动态加载资源配置。包括自动探测实际的机器配置,而不是管理员手动设置。
app级别的权重设置
https://issues.apache.org/jira/browse/YARN-1963
使用Docker做资源隔离
https://issues.apache.org/jira/browse/YARN-1964
